COMS6998 Dialog Systems
6998: Conversational AI
Logistics and Related Topics
- paper sign up: https://docs.google.com/spreadsheets/d/1qUP7ngFG996foQN017L0gHDrorpZcPYAOcwgFFmeV_k/edit#gid=0
- instead of Piazza, we are using Slack (for a smaller group but more interactions)
Grading
| Grading | |
|---|---|
| Paper Presentation (35min, record and place ppt link in the google shee, this time also includes discussion) | 15% |
| Reading Summary (weekly, 2 papers) | 15% |
| Proposal | 10% |
| Mid-Term Project Report | 15% |
| Final Report | 30% |
| Class Attendance (ask questions in class) | 15% |
The main conference for NLP would be ACL, and dialog has been a very popular field:
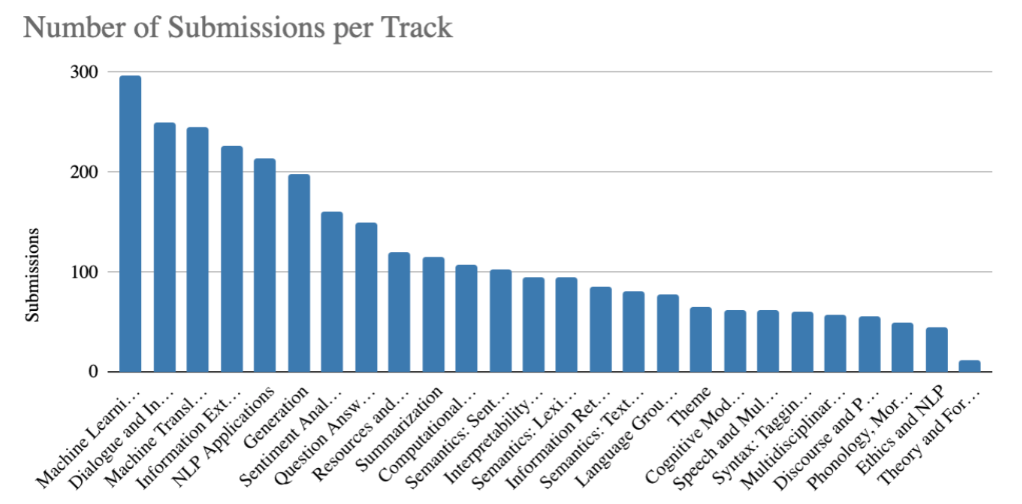
Task-oriented conversational agents can help complete task that are more efficient, standardized, and cheaper way.
Dialog System Basics
Usually have two different goals and hence two metrics
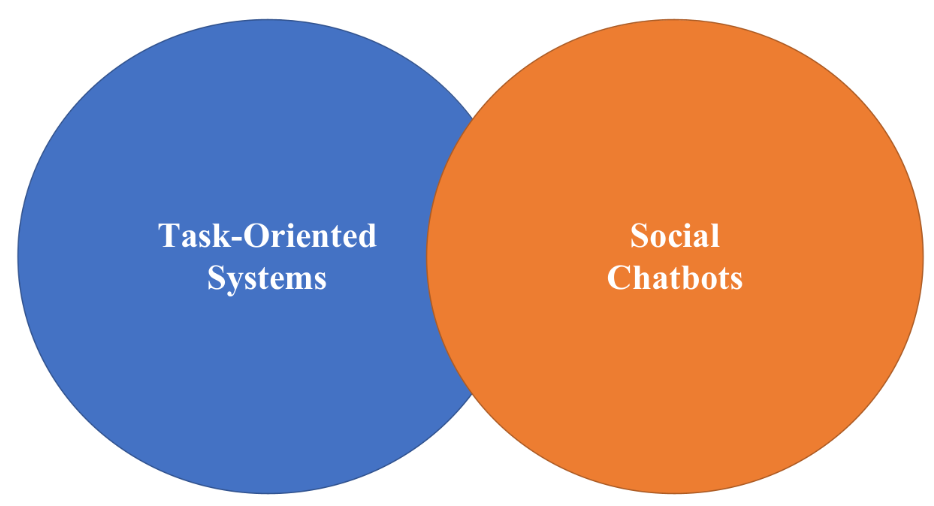
- task-oriented chatbot: relative simple to evaluate
- e.g. flight booking
- social chatbot: engage the user to stay in the conversation.
Usually, we consider dialog framework (abstractions) for task oriented chatbots:
| Module | Task | Example I/O | Solution/Architecture |
|---|---|---|---|
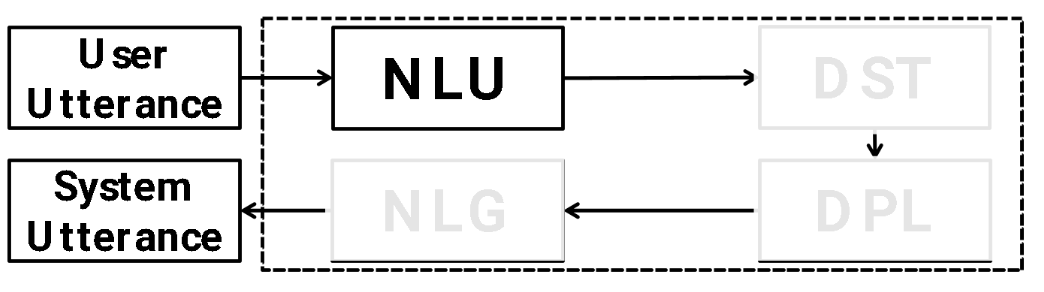 |
What is the user intent? For instance | Problem: user utterance $\to$ a distributed semantic representation Sub-Tasks: intent detection, slot filling e.g. I need something that is in east part of the town $\to$ Inform: location=east |
classification+sequence labeling (BIO tags) or sequence generation (e.g. directly use T5 to generate the desired output) |
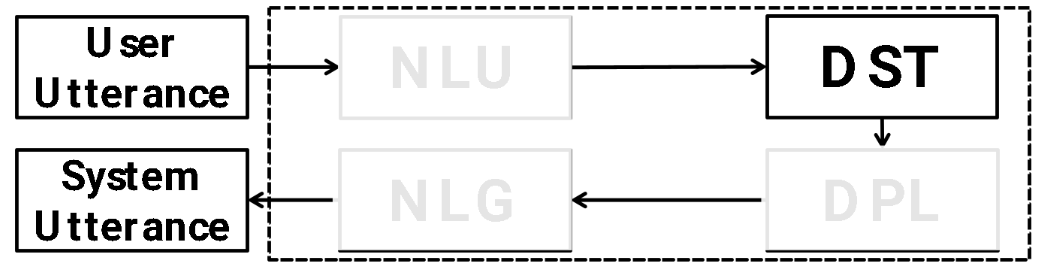 |
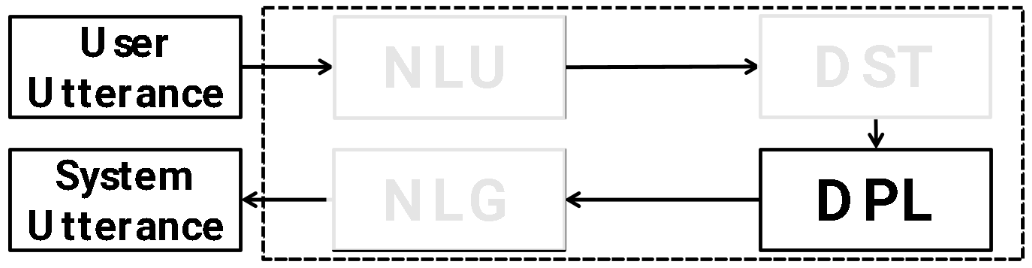
Important information you need to remember over time to complete the task (i.e. what is happening and what the user still needs) (e.g. tracking NLU output over time). This is actually very important because if you get this right, then you just need to do some API calls and done. |
Input: User: I am looking for a moderate price ranged Italian restaurant. Sys: De luca cucina and bar is a modern European restaurant in the center. User: I need something that’s in the east part of town Output: inform: price=moderate, location=east |
Sequence classification (e.g. given price, is it low, moderate, or high) or sequence generation |
 |
Dialog Policy Planning: plan what the system should say. (e.g. use of offline RL) |
Problem: dialog state $\to$ system action mean representation(intent + slot)/template e.g. inform: price=moderate, location=east $\to$ provide: restaurant_name, price, address |
supervised learning or reinforcement learning |
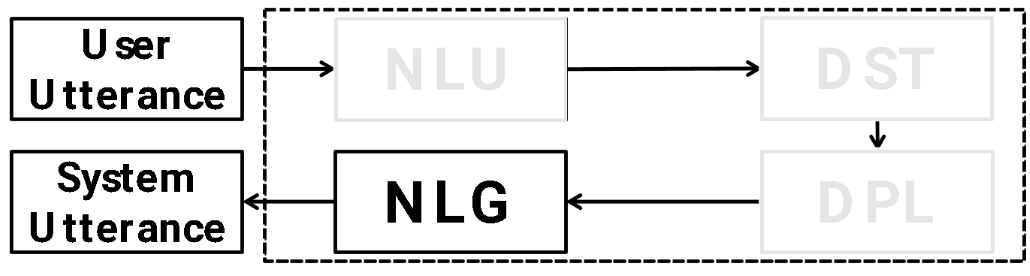 |
How to say it | e.g. provide: restaurant_name, price, address $\to$ Curry prince is moderately priced and located at 452 newmarket road. |
Seq-2-Seq generation |
why has this been a popular framework?
- since this is a modular framework, it is easier to debug/find error and/or employ constraints
- however, it would become difficult to update the entire system since we need all components to be coherent
Of course, then you have this simple brute force approach
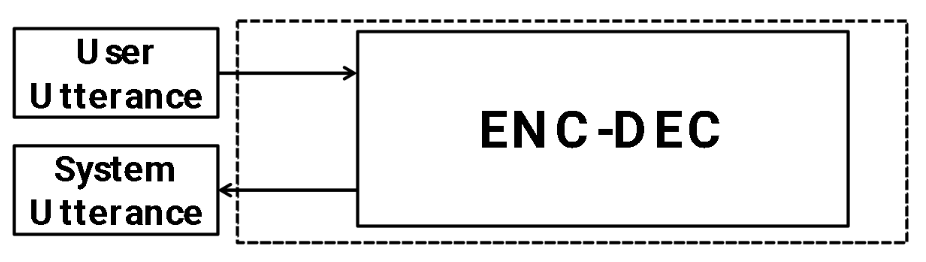
but then the problem is:
- hard to perform error analysis: did the model failed to understand? fail to plan? fail to generate?
- difficult to control the output as desired
Some challenges:
Dialog history and/or context tracking is still sub-optimal
- No data! No labelled data, and conversational data are mostly from company
- Big domain shifts between different dialog domains
- Difficult to evaluate how good your dialog system is (without human)
Notes on Presentations
- explain table: what is measured/the metric
- anything wierd about table
- outline, why am I talking about this
Dialog Datasets
Contains readings for different dialog datasets. Some common things you need to know is:
- Wizard-of-Oz (a style of collecting dialog data): connects two crowd workers playing the roles of the user and the system. The user is provided a goal to satisfy, and the system accesses a database of entities (basically to resolve the user’s requests), which it queries as per the user’s preferences.
- Machine-machine Interaction (a style of collecting dialog data): the user and system roles are simulated to generate a complete conversation flow (e.g. generate what DA to do at each turn), which can then be converted to natural language using crowd workers.
MultiWOZ - A Large-Scale Multi-Domain Wizard-of-Oz Dataset for Task-Oriented Dialogue Modelling
Aim: Provide more data and across more than one domains even within a conversation. Therefore, they collected a fully labelled (current domain, dialog intent, slot, and its value) human-human written conversations over multiple domains. This can then be used for belief tracking (i.e. what the system believe the user’s intent is), dialog act and response generation.
- cover between 1 and 5 domains per dialogue thus greatly varying in length and complexity. This broad range of domains allows to create scenarios where domains are naturally connected.
- For example, a tourist needs to find a hotel, to get the list of attractions and to book a taxi to travel between both places.
Dataset Setup:
-
Each dialogue is annotated with a sequence of dialogue states (i.e. what the user is asking for, by tracking which intent/slot-value the user is trying to fulfill) and corresponding system dialogue acts (i.e. the DA of the system repones)
-
A domain is defined by an ontology (i.e. set of concepts that are related), which is a collection of slots and values that the system has (know how to deal with):

and in general, a dialogue act consists of the intent/act type (such as
requestorinform) and slot-value pairs. For example, the actinform(domain=hotel,price=expensive)has the intentinform, where the user is informing the system to constrain the search to expensive hotels.
Dataset Collection Setup:
-
sample domains to generate some dialog scenario
-
prompt a user with a task template (generated by machine but mapped to natural language using a template)

which is presented gradually to the user, and the user needs to fulfill those tasks by talking to the system.
-
the system (wizard) is given some API/backend to query whatever he/she needs, and tries to answer the question. Note that the belief state can be tracked implicitly here since we can just check what the system is querying the database to know what he/she thinks the user needs.
- note that in the end, it is annotated again by the MT because there could be errors when performing the database queries (e.g. incomplete)
-
perform annotation on dialog act (e.g.
inform(domain=hotel,price=expensive)) by using Amazon Mechanical Turk (by eliminating some poor workers). An example of what they are given is shown here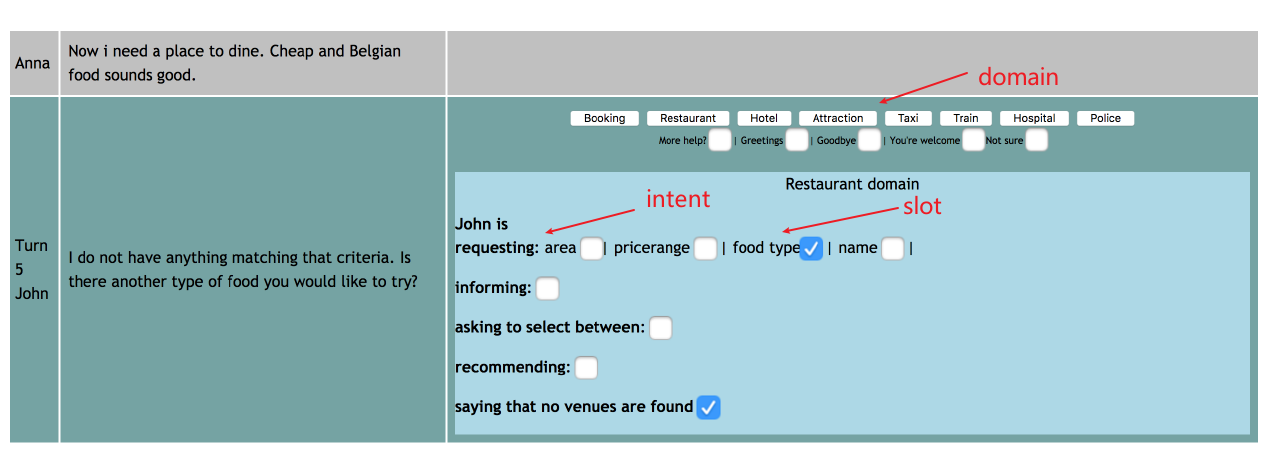
-
This results in the following data statistics:
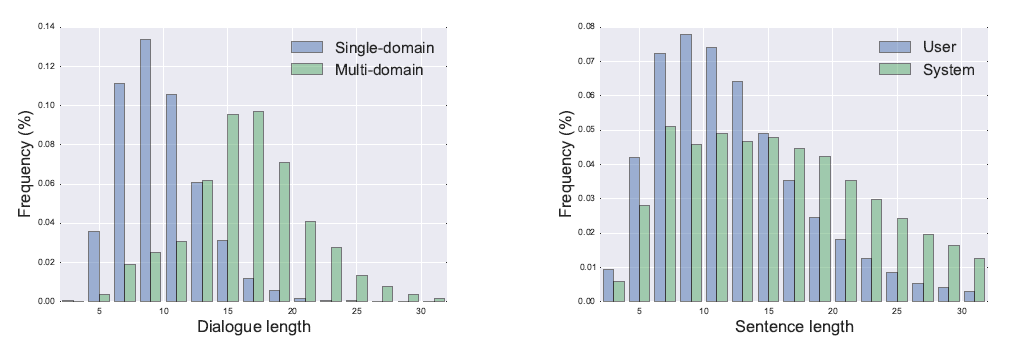
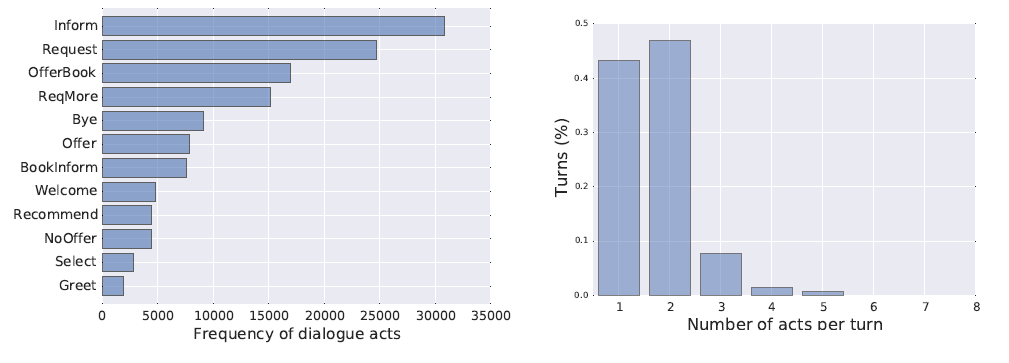
on the left we see that multi-domain dialogs tends to be longer, and on the right we see that system reponses tend to be longer. And finally, very self-explanatory:
Dataset Benchmarks: here they consider using this dataset to do three things:
-
dialog state tracking (identify the correct slot-value pair): since other datasets only have a single domain, only the
restaurantdomain in this dataset is used: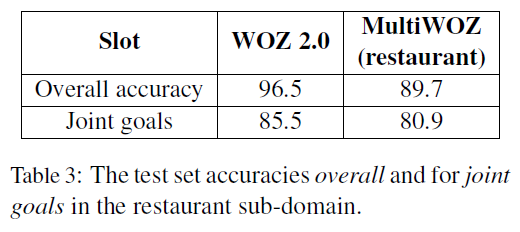
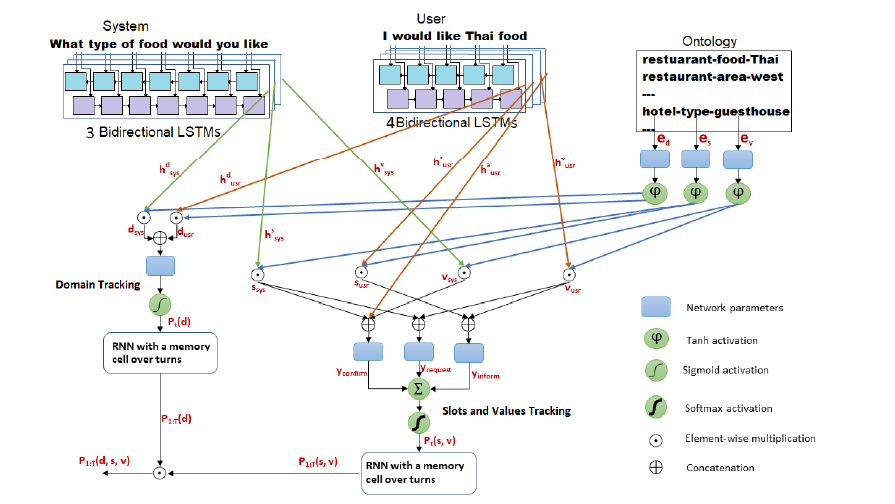
Here, the model is a SOTA from another paper which basically considers learning slot-value pairs and domains separately during training, hence enabling model to learn cross-domain slot-value pairs:
the result is that overall accuracy is lower, hence this dataset is harder.
-
dialog-context-to-text generation (more end-2-end than next one) given the oracle belief state (tracked when system is doing query). We generate the response by doing:
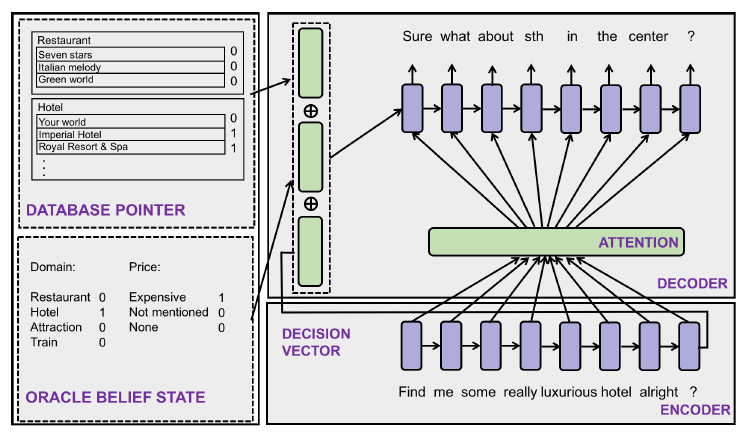
which basically sets the hidden state $h$ for the decoder to be information about what user said (belief state), while attending to the user’s actual utterances. Since this is generation, metrics such as BLEU for fluency would apply:
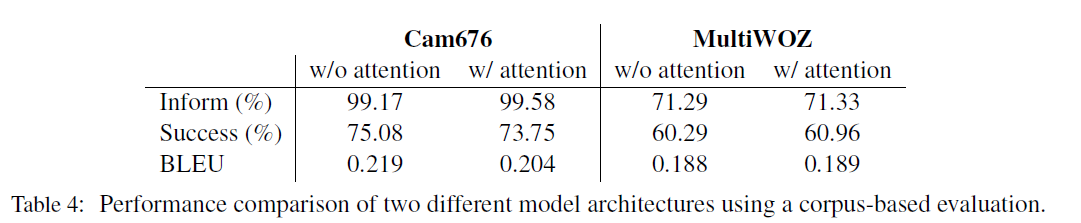
where Success measures whether if the system has fulfilled the user’s request, and Inform measure whether the system has provided an appropriate entity.
-
dialog-act-to-text generation: since we have all the annotated dialog-act as well, we can test systems on their ability to generate utterances from meaning representations (e.g. dialog act to do next). Details skipped here.
Towards Scalable Multi-Domain Conversational Agents: The Schema-Guided Dialogue Dataset
Aim: In reality, there might be a dynamic set of intents and slots for a task, i.e. their possible values not known in advance. Therefore, they propose a dataset for zero-shot settings and also propose a schema-guided paradigm to train models making predictions over a dynamic set of intent/slots you can have in the input schema.
- essentially this dataset is collected by 1) generate outlines via M-M interaction, and then 2) convert to human language by AMT paraphrasing them
Dataset Setup:

- a schema (see above) is a combination of intent and slots with some additional constraints (such as some intent requires at least certain slots to be there)
- there are also non-categorical slots
Dataset Collection:
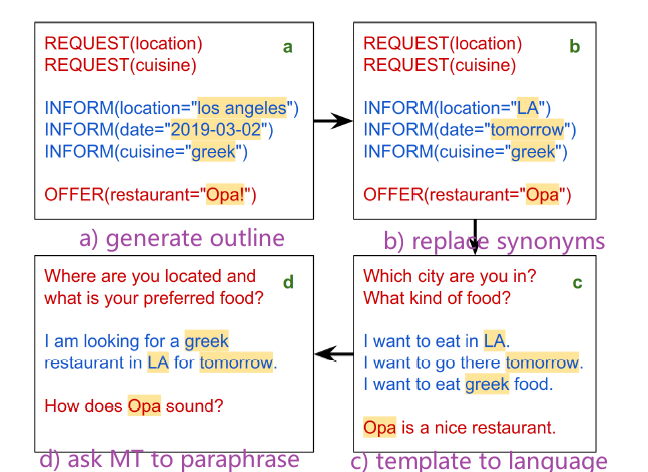
- first they use dialog simulators to interact with services to generate dialog outlines, basically a). This is achieved by first seeding the user agent with a scenario (among the 200 they identified), and then generate the dialog act to do for the next turn.
- then the system agent generates in a similar fashion.
- the rest is basically shown in the above flowchart.
- the MT is asked to exactly repeat the slot values in their paraphrases. This has the advantage of easily string matching to find the slot span annotation automatically. Also, it preserves all the annotation in a), hence there is no more need for human annotators.
- perhasp a disadvantage: reduced noise in human conversation as every/most sentences would be goal oriented? Are the intent natural on a human-basis?
Dataset Benchmark: since one aim of this is to do zero-shot dialog state tracking, they also made a model to do that
- their model is basically done by:
- obtain a schema embedding by converting the current information into an embedding (e.g. by BERT). which embeds all the intents, slots, and slot-values.
- obtain an utterance embedding of the user and the previous dialog history
- combine the above using the so called “projection” operation, which you can then use to do
- active intent prediction: what is the current intent?
- only a single intent per utterance?
- requested slots by the users (a classification task)
- user goal prediction: what is the slot-value currently (up until now) request by the user
- have a classifier to predict for each slot if things have changed
- if yes, predict what is the new value
- active intent prediction: what is the current intent?
-
then, from the above we can consider evaluation tasks such as:
- Active Intent Accuracy: how much active intent of the user I got right
- Request Slot F1: macro-averaged F1 score for requested slots
- Average Goal Accuracy: for each turn, the accuracy of the predicted value of each slot (fuzzy machine score used for continous values)
- Joint Goal Accurarcy: usually more useful/stricter than the above
some important results are shown here
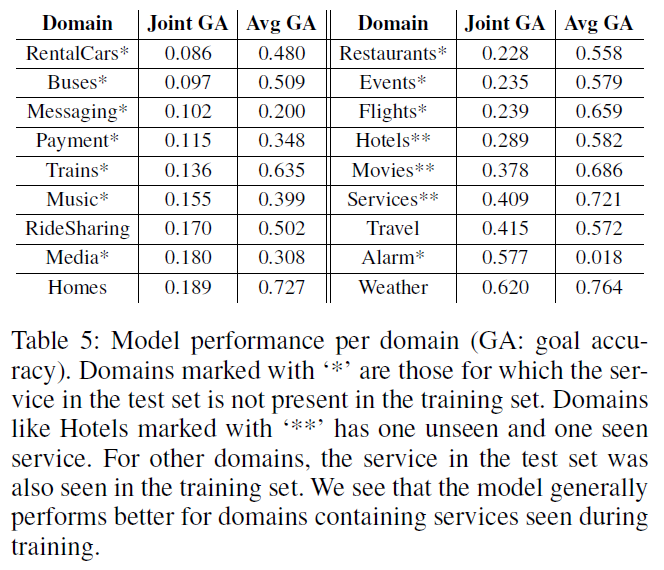
where we notice that major factors affecting the performance across domains is:
- the presence of the service in the training data (seen services), so degrade for domains with more unseen services
- Among seen services, ‘
RideSharing’ domain also exhibits poor performance, since it possesses the largest number of the possible slot values across the dataset - for categorical slots, with similar slot values (e.g. “
Psychologist” and “Psychiatrist”), there is a very weak signal for the model to distinguish between the different classes, resulting in inferior performance
Can You Put it All Together: Evaluating Conversational Agents’ Ability to Blend Skills
Aim: Recent research has made solid strides towards gauging and improving performance of open domain conversational agents along specific skill. But a good open-domain conversational agent should be able to seamlessly blend multiple skills (knowledge, personal background, empathy) all into one cohesive conversational flow. Therefore, in this work they:
- investigate several ways to combine models trained towards isolated capabilities, ranging from simple model aggregation schemes that require minimal additional training, to various forms of multi-task training
- propose a new dataset,
BlendedSkillTalk, which blends multiple skills into a single conversation (one skill per turn, but different across turns), to analyze how these capabilities would mesh together in a natural conversation
Dataset Setup
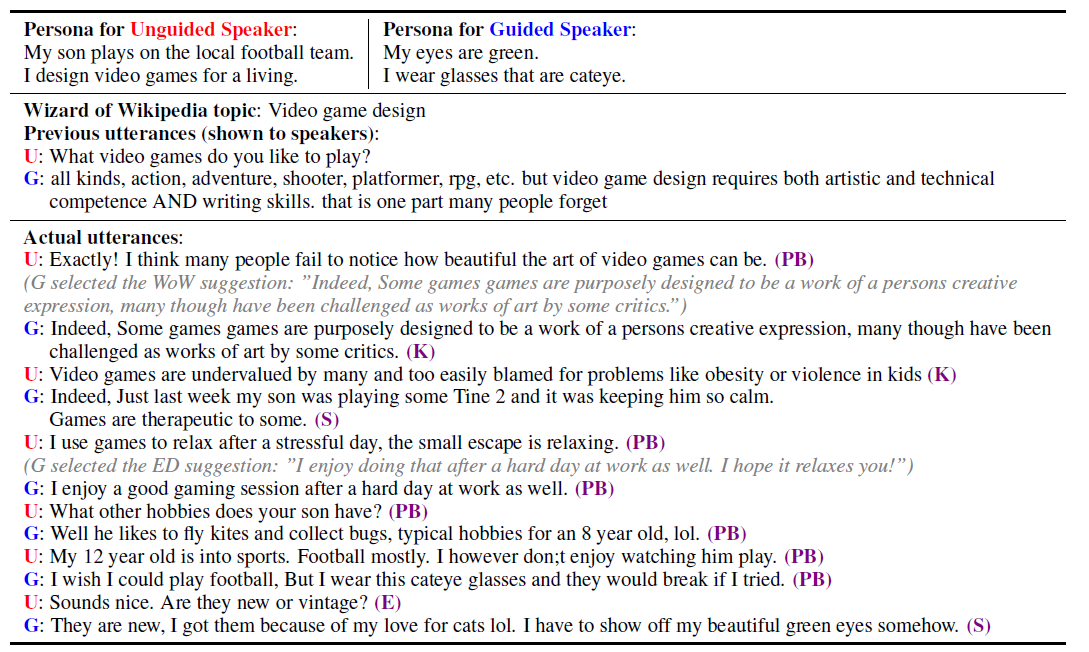
-
BendedSkillTalk, a small crowdsourced dataset of about 5k conversations in English where workers are instructed to try and be knowledgeable (Wizard of Wikipedia), empathetic (EmpatheticDialogs), or give personal details (ConvAI2) about their given persona, whenever appropriate.-
ConvAI2 example:

then the user is asked to converse on telling each other about their personalities
-
WoW example:

where the topic is used as an initial context
-
ED example:

-
-
labels are the skill per turn, namely which skill they used.
Dataset Collection
- To ensure MT workers not stick with one specific skill or being too generic, they prompt one user (guided user, denoted by
G) with responses from models that have been trained towards a specific skill as inspiration (one each from each skill) - Each starting conversation history is seeded randomly from the
ConvAI2,WoW,EDdataset- if from
WoW, a topic is also given. If fromED, the situation description is given
- if from
- In fact, for labelling we have 4 labels because
EDutterances has “Speaker” and “Listener” taking different actions:- Knowledge, Empathy, Personal situations, Personal background
Dataset Benchmarks: since it is combining skills from three datasets essentially, we can have:
-
a base architecture of poly-encoder which is a retrieval model: select from a set of candidates (the correct label combined with others are chosen from the training set). This is pretrained on the pushshift.io Reddit dataset
-
since it is asked to rank among candidates, metric such as
hit@kapplies. This metric works as follows. Consider two correct labels:Jack born_in Italy Jack friend_with Thomasand a bunch of synthetic negatives are generated, where the model is ranking them:
s p o score rank Jack born_in Ireland 0.789 1 Jack born_in Italy 0.753 2 * Jack born_in Germany 0.695 3 Jack born_in China 0.456 4 Jack born_in Thomas 0.234 5 s p o score rank Jack friend_with Thomas 0.901 1 * Jack friend_with China 0.345 2 Jack friend_with Italy 0.293 3 Jack friend_with Ireland 0.201 4 Jack friend_with Germany 0.156 5notice that if we are doing
hit@1, then only $1/2$ times the model did correctly, but if we dohit@3, then the it is $2/2$.
-
-
Finetune on BST: finetune the pretrained dataset directly on
BlendedSkillTalkDataset -
Multi-task Single-Skills: finetune the model to multi-task on
ConvAI2,WoW, andED- however, note that there could be some stylistic difference between
ConvAI2dialogs andWoWdialogs. For instance, the prior include a persona context, and the latter include a topic - therefore, to avoid model exploiting those, all samples are modified to always include a persona and a topic (where there is already an alignment of
WoWtopics toConvAI2)
- however, note that there could be some stylistic difference between
-
Multi-task Single-Skills + BST: after the multi-task training, finetune again on the BST dataset
-
Multi-task Two-Stage: since many single-skilled models have already been trained, we can just use a top level BERT classifier to assign which model gets to score candidates.
-
Then, along with just models trained on their own dataset, we can have 7 models to evaluate:
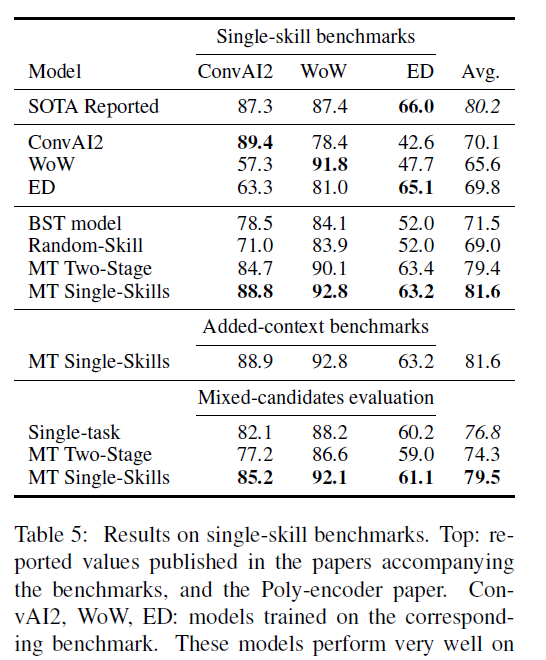
where we observe that:
-
BST shows balanced performance but failed to match the performance of the single-skill models on their original dset, as well as losing to MT Single-Skills.
-
MT Single-Skills does not do exactly well as single-skill model when evaluated on their own benchmark (for
ConvAI2andED). But perhaps this is unfair since those Single-Skill models only have to choose from candidates from their own domain. Hence, the author considers mixing candidate for them to also include samples from other dataset, which gives rise to the Mixed-candidates evaluation.Here, MT Single-Skills is doing better, suggesting that multi-task training results in increased resilience to having to deal with more varied distractor candidates
-
-
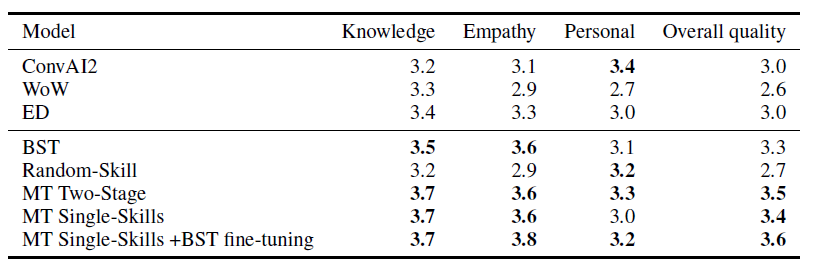
finally, there is of course the human evaluation:
Dialog Understanding
Many models are basically performing the task of:
- input dialog history up to current turn
- output: “what does the user want from us” in terms of classifying intent, slot, slot-value
- then by filling in the values, e.g. book a plane from Paris to London, the system can perform API based queries
source=London, dest=Paris
- then by filling in the values, e.g. book a plane from Paris to London, the system can perform API based queries
Attention-Based Recurrent Neural Network Models for Joint Intent Detection and Slot Filling
Aim: we want to explore how the alignment information in slot filling can be best utilized in the encoder-decoder models, and on the other hand, whether the alignment-based RNN slot filling models can be further improved with the attention mechanism that introduced from the encoder-decoder architecture . To this end, we propose an attention-based neural network model for joint intent detection and slot filling.
The main idea is:
- encode input sequence into a dense vector
- then use this vector to decode/generate corresponding output sequence. Here LSTM is used so alignment is natural (see example below)
Setup

- the input essentially is the sentence, and slot detection and slot-filling is done simultaneously from the flat structure
- potential problem cannot track implicit information, e.g. slot value not there, or hierarchical information (i.e. tagging v.s. parsing)
- let the input sentence be $x=(x_1,…,x_T)$, and output be $y=(y_1,…,y_T)$ and intent in addition.
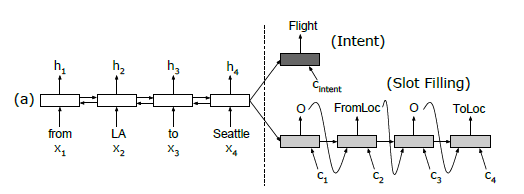
Architecture
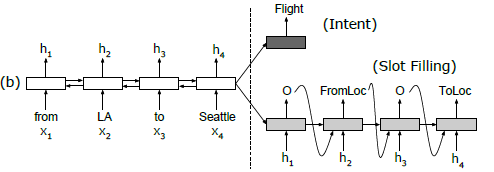
| no aligned inputs | aligned inputs | aligned inputs and attention |
|---|---|---|
 |
 |
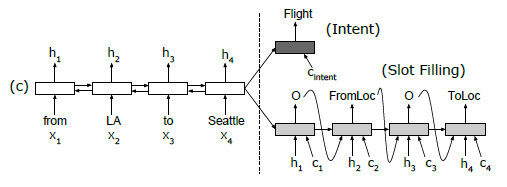 |
-
essentially you have an RNN for encoder, and an RNN for decoder with inputs using the hidden states from $x$ for alignment
- encoder: bidirectional LSTM, so we get $[fh_1,…,fh_T]$ and $[bh_1,…,bh_T]$ being the forward/backward hidden states. Then $h_i = [fh_i, bh_i]$ is the total hidden state for each input $x_i$
- decoder: unidirectional LSTM
-
to model attention vector, we want to measure how each hidden state $s_j$ in the decoder relates to the aligned word’s hidden state $h_k$:
\[e_{i,k} = g(s_{i-1},h_k)\]then essentially $e$ is transformed into weights
\[c_i = \sum_{j=1}^T \alpha_{i,j}h_j,\qquad \alpha_{i,j} = \mathrm{Softmax}(e_{i,j})\]essentially $c_i$ provides additional information to answer: which of the aligned word’s hidden state $h_j$ relate to the current state I want to decode $s_{i-1}$. They also provided a visualization of this attention
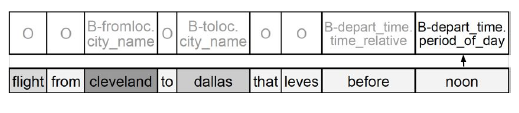
where we are decoding the last tag, and we are attending to words such as
cleveland.- they mentioned that the motivation to bring in an additional context $c$ is because distant information just from $s_j$ tends to be diluted a lot and lost.
-
therefore, their ultimate model involves giving the decoder both the aligned hidden state $h_i$ and the attended context $c_i$
-
TODO two objectives and one network
-
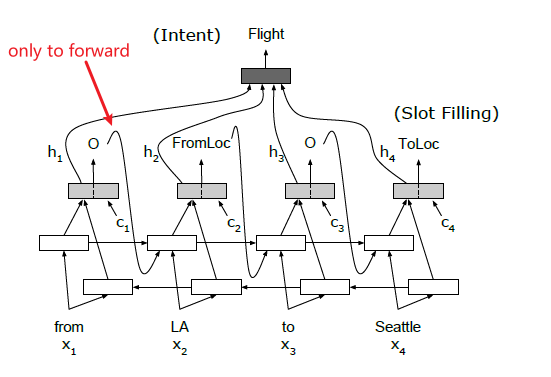
to further utilize the decoded tags, they can also do it auto-regressively by feeding the decoded tag into the forward direction of the RNN
Results
-
They are using ATIS-3 and DEC94 dataset, which has joint intent detection and slot filling task
-
then essentially they were doing an ablation study of a) effect of alignment b) effect of attention:
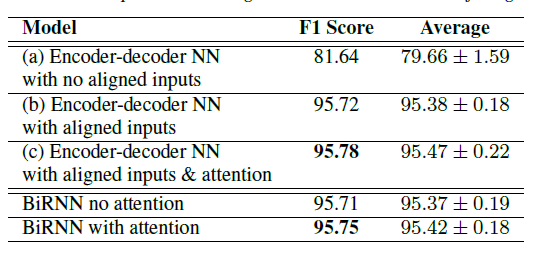
so it is found that alignment and attention does give improvement, yet the latter gave only small improvement. They also investigate further and found that the attention was giving mostly uniform weights except for a few cases (hence the small boosts)
Conversational Semantic Parsing for Dialog State Tracking
Aim: By formulating DST (dialog state tracking) as a semantic parsing task over hierarchical representations, we can incorporate semantic compositionality, cross domain knowledge sharing and co-reference.
- essentially outputting a tree instead of slot-filling
- additionally, they collected their own dataset
TreeDSTannotated with tree-structured dialog states and system acts- they combine essentially the idea of semantic parsing (e.g. drawing tree from production rules) to do DS tracking
- in their approach, the tree drawing is done by predicting a node and its parent
Setup:

-
As in DST, the task is to track a user’s goal as it accumulates over the course of a conversation. To capture a hierarchical representation of domain, verbs, and operators and slots:
Tree Representation Condensed, Dotted Representation 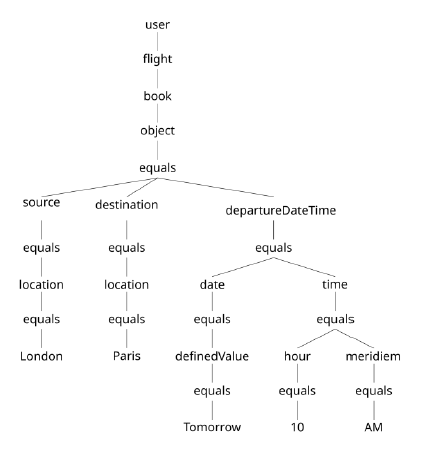

this is done for both user and system, and this dotted form is also referred to as a meaning representation. Advantages of this include:
- tracking nested intents and representing compositions in a single graph
- naturally supports cross domain slot sharing and cross-turn co-reference through incorporating the shared slots or the references as sub-graphs in the representation
-
At each turn we have
- $x_t^u$ being user utterance, $y_t^u$ being user dialog-state
- $x_t^s$ being system utterance, $y_t^s$ is system dialog act
- both $y_t^s,y_t^u$ adopt the same structure semantic formalism
Dataset:
-
collection is similar to the SGD paper, where they:
- generate agendas/conversation flows by using machines
- convert them via templates to language
- ask MT to paraphrase to natural language
-
specifically, the agenda generation for both user and system is done by:
-
a module generating the initial user goal $P(y_o^u)$. This can be done by sampling a production rule

-
a module generating system act $P(y_t^s\vert y_t^u)$. This is done by looking at the user’s act tree $y_t^u$, look up the production rules to figure out how to finish the tree, and take that as the system act

-
a module for user state update/DS based on dialog history $P(y_t^u\vert y_{<t}^s,y_{<t}^u)$. There are two details in this task:
-
model “introduces a new goal, continues with the previous goal, or resumes an earlier unfinished goal”. Therefore, a stack is used and updated. Therefore the top of the stack always represents the most recent unfished task $y_{t-1}^{top,u}$ and the corresponding system act $y_{t-1}^{top,s}$
-
the next dialog state $y_t^u$ is generated based on the top elements of the stack as the dialog history
- precaustion: implies an additional structure to dialog, hence unfair advantage as their model also stores a stack? (see their modelling choice of dialog history, which takes the top of the stack as well)
since this is now generated from two trees (there are two at the top of the stack)

where the next user state will be combining the two
-
-
-
finally, a quality control is also done by asking:
- before the paraphrasing, filter out non-realistic interactions
- after the paraphrasing, ask if the human-generated utterance preserves the meaning of the templated utterance
Architecture:
-
our task is to:
- infer $y_t^u$ since $y_t^s$ is observed/what the system just did
- to also track goal switching and resumption, a stack is used to store dialog states
-
to output tree structure, we essentially just need to decode:
- a new node
- the new node’s parent in the existing tree
-
additionally, they chose to maneuver their own features:
-
dialog history is computed as a fixed-size history representation derived from the previous conversation flow $(Y_{<t})$, specifically the top of the stat $y_{t-1}^{top,u}$ along with:
\[Y_{t-1}^u = \text{merge}(y_{t-1}^u, y_{t-1}^{top,u})\] -
encoding the features:
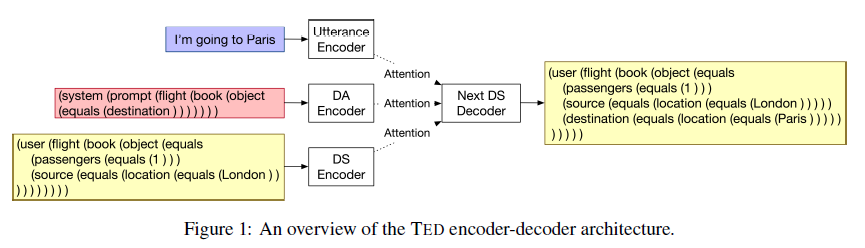
where essentially we have three features and hence three encoders:
- encoder (bidirectional LSTM) for user utterance $x_t^u$
- encoder (bidirectional LSTM) for system act $y_{t-1}^s$
- encoder (bidirectional LSTM) for dialog state $Y_{t-1}^u$ described above
where to encode the trees, they are first linearized into strings by DFS
-
decoding: they experimented with two versions:
-
just decode a flattened string, as in Figure 1. The final aim is to simply compute the probability of next token by accessing its probability of generation and copy
Specifically, the decoder takes
\[g_i = \mathrm{LSTM}(g_{i-1},y_{t,i-1}^u)\]which is basically auto-regressive, and the attention is used together with $g_i$ to compute probability of next token
-
attention: attend current state to history
\[a_{i,j} = attn(g_i,H)\]where history would be either of the three from the three encoders. Then this is used for weights to produce:
\[\bar{h}_i = \sum_{j=1}^n w_{i,j} h_i,\quad w_{i,j} = \mathrm{Softmax}(a_{i,j})\] -
finally, the token distribution is computed by concatenating $\bar{h}_i^x, \bar{h}_i^s, \bar{h}_i^u$ from the encoders and $g_i$ to give $f_i$
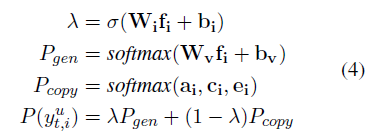
finally, since this is decoding a flat string, the loss is simply CCE of the correct $y_{y,i}^u$
-
-
decode a tree by generating nodes and select their parent relationships from the existing tree: you basically take the hidden state/embedding of the previous node $n_{t,i-1}^u$ and its parent relation $r_{t,i-1}^u$ to be input features as well for decoding:
\[g_i = \mathrm{LSTM}(g_{i-1},n_{t,i-1}^u , r_{t,i-1}^u)\]the we perform two predictions using two layers using $g_i$
-
predict next node probability using equation 4
-
select parent of the node by attending $g_i$ to previously generated nodes and choosing the most relevant
-
-
-
Results
-
experiment on DST dataset, where for models not with hierarchical MR in mind, all training and testing here are flattened:
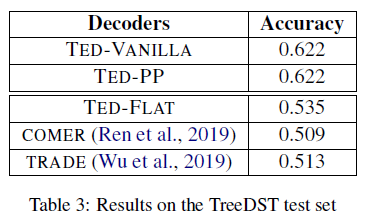
- TODO doesn’t this also mean that flattened based is naturally less accurate than tree based (TED-Flat v.s. TED-Vanilla) given that the task is tree based?
-
evidence of compounding error if prediction is done auto-regressively:
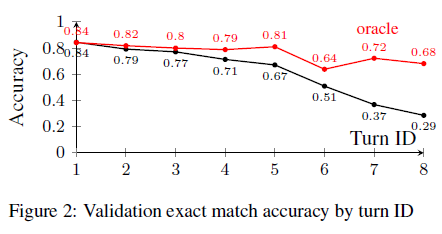
where the oracle means substituting the gold previous state for encoding
Task-Oriented Dialog
Essentially models that can complete task by providing/informing the right entities and complete the task successfully. A popular dataset that has been used for finetuning + testing is the MultiWoZ dataset, which contains an automatic evaluation script as well.
GALAXY: A Generative Pre-trained Model for Task-Oriented Dialog
In this paper, we propose GALAXY, a novel pre-trained dialog model that explicitly learns dialog policy from limited labeled dialogs and large-scale unlabeled dialog corpora via semi-supervised learning.
Specifically, we introduce a dialog act prediction task for policy optimization during pre-training and employ a consistency regularization term to refine the learned representation with the help of unlabeled dialogs
Background:
- there are intrinsic differences between the distribution of human conversations and plain texts. Directly fine-tuning plain-text-trained PLMs on downstream dialog tasks hinders the model from effectively capturing conversational linguistic knowledge. Therefore, current attempts to tackle this issue try to build Pre-trained Conversation Models (PCMs) by directly optimizing vanilla language model objectives on dialog corpora
- Therefore, we hypothesize that explicitly incorporating the DA annotations into the pre-training process can also facilitate learning better representations for policy optimization to improve the overall end-to-end performance
- Although DAs are general tags to describe speakers’ communicative behaviors (Bunt 2009), current DA annotations in task-oriented dialog are still limited and lack of unified taxonomy because each dataset is small and scattered.
Dataset:
-
To begin with, we build a unified DA taxonomy for TOD (task-oriented-dialog) and examine eight existing datasets to develop a new labeled dataset named
UniDAwith a total of 975K utterances. We also collect and process a large-scale unlabeled dialog corpus calledUnDialwith 35M utterances -
We propose a more comprehensive unified DA taxonomy for task-oriented dialog, which consists of 20 frequently-used DAs
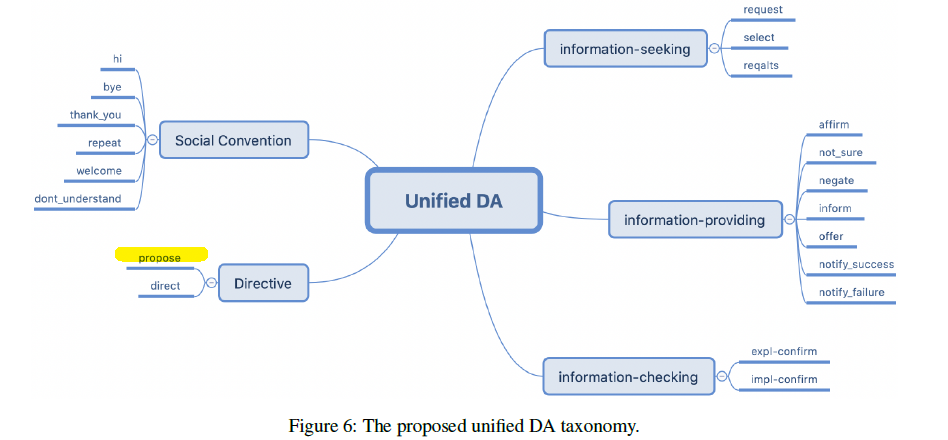
Model:
-
We choose UniLM (Dong et al. 2019) as our backbone model, which contains a bi-directional encoder for understanding and a unidirectional decoder for generation.
-
We adopt a similar scheme of input representation in Bao et al. (2020), where the input embeddings consist of four elements: tokens, roles, turns, and positions.
- Role embeddings are like segmentation embeddings in BERT and are used to differentiate which role the current token belongs to, either user or system
- Turn embeddings are assigned to each token according to its turn number.
- Position embeddings are assigned to each token according to its relative position
-
Four objectives are employed in our dialog pre-training process: response selection, response generation, DA prediction and consistency regularization.
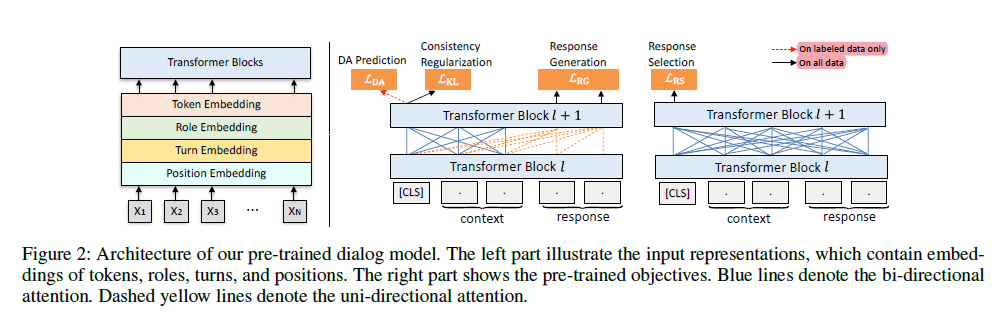
where the important components include:
-
Response Selection. For a context response pair $(c; r)$ from the corpus, the positive example (with label $l = 1$) is obtained by concatenating $c$ with its corresponding response $r$, and the negative example (with label $l = 0$) is constructed by concatenating $c$ with a response $r^-$ that is randomly selected from the corpus. Then simply for each pair:
\[L_{RS} = -\log p(l=1|c,r)-\log p(l=0|c,r^-)\]where the predicted probability is fine-tuned by adding a linear head to the transformer and then a sigmoid on the
\[p(l=1|c,r) = \mathrm{sigmoid}(\phi_a(h_{cls}))\][CLS]token:note that $\phi_a$ is a fully-connected NN with output size of 1.
-
Response Generation. The response generation task aims to predict the dialog response r auto-regressively based on the dialog context $c$. Here we use the standard NLL loss per token in each generated sequence:
\[L_{RG} = - \sum_{t=1}^T \log p(r_t|c,r_{<t})\]for $r_t$ is the $t$-th word in $r$, and $r_{<t}={r_1,…,r_{t-1}}$. So basically this is the greedy prediction.
-
DA Prediction: For a context response pair $(c; r)$ sampled from
\[L_{DA}=-\sum_{i=1}^N \{y_i \log p(a_i|c)+(1-y_i)\log(1-p(a_i|c)\}\]UniDA, the DA prediction task aims to predict the DA label $a$ of the response $r$ based merely on the context $c$. However, since there are responses inUniDAassociated with multiple DA, we model it as a Bernoulli Distribution such that $a\equiv (a_1,a_2,…,a_N)$ for $N$ being the number of dialog acts, and $p(a\vert c)=\prod_i^N p(a_i\vert c)$. Therefore, taking the dialog context $c$ as input, we add a multi-dimensional binary classifiers on $h_{cls}$ to predict each act $a_i$:and our prediction is a single $N$ dimensional vector
\[p(a|c) = \mathrm{sigmoid}(\phi_b(h_{cls})) \in \mathbb{R}^N\] -
Consistency Regularization: because there is no DA label for
\[q(a|c)=\mathrm{softmax}(\phi_b(h_{cls})) \in \mathbb{R}^N\]UniDial, we do some kind of self-supervision on inferring the DA labels based on a given dialog context $c$. Specifically, we use the same network $\phi_b$ to predict the dialog act twice after a dropout layer:which basically predicts DA distribution of a given sequence. Then as we feed the sequence through the same dropout layer we have different hidden features, we can consider to match the two distributions:
\[L_{KL} = \frac{1}{2}\left( D_{KL}(q_1||q_2)+ D_{KL}(q_2||q_1)\right)\]essentially making sure that the learnt features are useful for DA prediction.
-
-
Hence, the pretraining objective is by mixing:
-
\[L = L_{RS} + L_{RG} + L_{DA} + L_{KL}\]UniDAsamples which includes DA annotation, hence -
\[E = \sum_{i}^N q(a_i|c)\log(q(a_i|c))\]UniDialsamples which does not have DA annotation and some are very noisy. Hence we consider a gating mechanism of weighting the $L_{KL}$ by looking at the entropy of the DA prediction $q(a\vert c)$:and we want to weight more on samples with low entropy:
\[g=\min \left\{ \max\left\{0, \frac{E_{\max} - (E-\log E)}{E_\max} \right\},1 \right\}\]Therefore our loss for those data is:
\[L = L_{RS}+L_{RG}+g L_{KL}\]
-
-
Finally, once we trained our model with mixing
\[L_{\text{fine-tune}} = L_{RS} + L_{RG} + \alpha L_{DA}\]UniDAandUniDial, it is a pretrained model and we can fine-tune it with our desired DA dataset :for $\alpha=1$ if the dataset has annotated DA, and $\alpha=0$ otherwise. Notice that a response selection objective is still here even if we in the end only need generation capability. This is because we want to alleviate the model discrepancy between pretraining and finetuning.
GODEL: Large-Scale Pre-Training for Goal-Directed Dialog
Aim: GODEL leverages a new phase of grounded pre-training designed to better support adapting GODEL to a wide range of downstream dialog tasks that require information external to the current conversation (e.g., a database or document) (i.e. the environment $E$ in the model) to produce good responses. While GODEL out-performs previous models such as DialoGPT, they also introduce a novel evaluation methodology: the introduction of a notion of utility that assesses the usefulness of responses (extrinsic evaluation) in addition to their communicative features (intrinsic evaluation, e.g. BLEU). We show that extrinsic evaluation offers improved inter-annotator agreement and correlation with automated metrics.
Setup
-
First, it is pre-trained in three phases, successively folding in data from web text, publicly available dialog (e.g., Reddit), and a collection of existing corpora that support grounded dialog tasks (conditioned on information external to current conversation).
-
we must also acknowledge that machine-human conversation typically serves a purpose and aims to fulfill one or more goals on the part of the user. In other words, the model must offer utility to the user. It is this extrinsic dimension of functional utility, we suggest, that constitutes the proper focus of automated evaluation in general-domain models.
Therefore, a evaluation metric called Utility is proposed, so that cross-dataset comparison can be made instead of the adhoc metrics for a dataset (e.g. Success-rate and Inform-rate).
- currently the utility can only be human-evaluated
-
after large scale pretraining, the model is tested on Multi-WOZ, CoQA, Wizard of Wikipedia, and Wizard of the Internet
Pretraining
-
GODEL is pre-trained in three phases:
- Linguistic pre-training on public web documents to provide a basic capability for text generation.
- Dialog pre-training on public dialog data to improve the models’ handling of general conversational behavior.
- Grounded dialog pre-training to enable grounded response generation
and since we can have grounded dialog, the input can have $S,E$ for $S$ being the dialog context history, and the additional information needed (e.g. price of a hotel) is the environment $E$
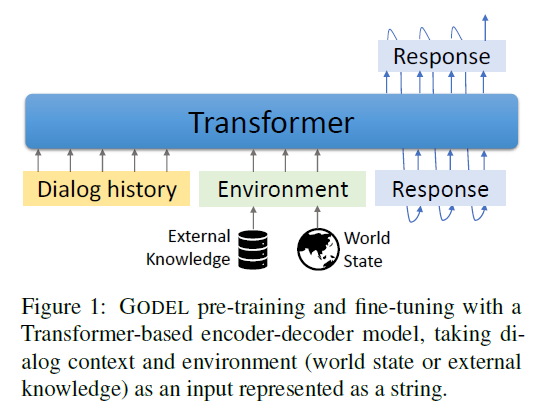
then, the loss for all pretraining task is the cross entropy for decoding each word:
\[p(T|S,E) = \prod_{n=1}^N p(t_n | t_1, ..., t_{n-1}, S,E)\]so $T = {t_1,…,t_n}$ is the target sentence. Note that in tasks that does not require extra information, $E$ is left as empty.
- the public dialog dataset comes from the Reddit comment chains used for DialoGPT
- the grounded dialog dataset contains a collection of: DSTC7 Task 2 corps, MS MARCO, UnifiedQA, SGD
Model
- backbone based on T5, T5-Large, and GPT-J is used
- the models are trained for at most 10 epochs, and we select the best versions on the validation set
Experiments
-
we would like to test the few-shot finetuning ability of the mode, as well as full finetuning, because in general labeled task-oriented data is small in size
-
dataset used for testing therefore include the untouched: MultiWOZ, Wizard of Wikipedia, Wizard of Internet, and CoQA
- specifically, for few-shot we consider tuning 50 dialogs for each task for finetuning
- automatic evaluation metrics are often setup already for those datasets, especially for MultiWOZ
-
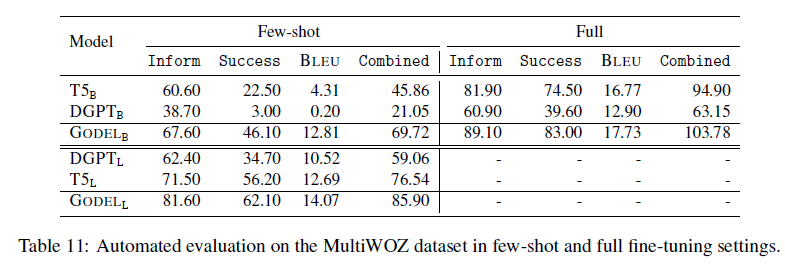
results for few-shot finetuning and full finetuning
Few-shot Fine-tuning Full Fine-tuning 
Social Chatbot
If the aim is to extend conversations by engaging user in anyway, what can we do?
Alquist 4.0 Towards Social Intelligence Using Generative Models and
Aim: The system Alquist has a goal to conduct a coherent and engaging conversation, which essentially uses a hybrid of hand-designed responses and generative models
- usually it is the hand designed responses tree that is functioning
- when OOD is detected from the tree (using intent classifier), response generative model is used.
- note that a lot of control is needed for the generative model to merge nicely with the hand-written responses
Setup
-
in order to entertain the conversational partner, one has to learn what entertains the partner first and then utilize the knowledge in the following conversation
- exploration part, in which Alquist learns the preferences of the user, the main research and development emphasis was put on Skimmer, User Profile building, and Entity and Knowledge Utilization
- exploitation part, in which Alquist utilizes the knowledge about the user, the main emphasis was put on the research and development of the Dialogue Manager, Trivia Selection, Intent and Out-of-Domain classification
-
the basic flow looks like this:
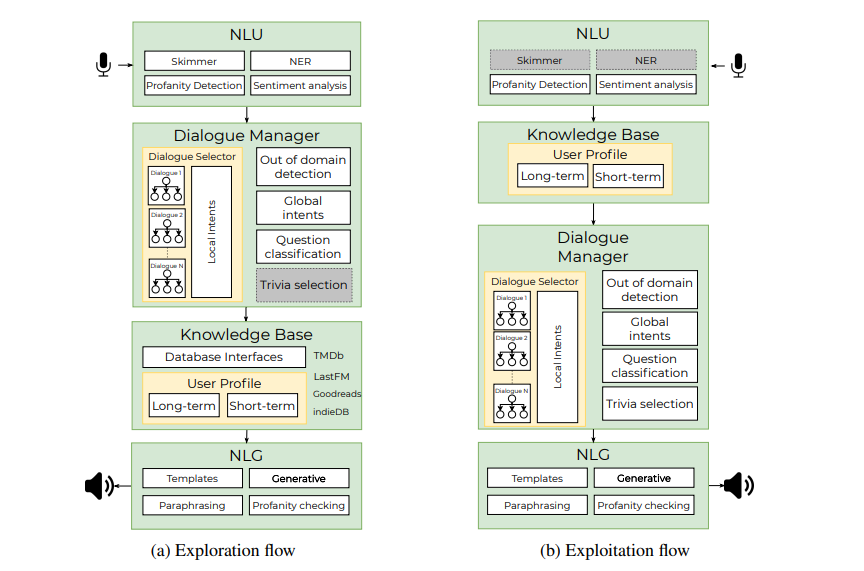
and on a high level, we have on the left:
- First, the Skimmer analyses the user input for the mentioned pieces of information. The pieces of information are stored in the User Profile.
- Based on the values stored in the user profile, the Dialogue Management selects the next dialogue to start, or selects and presents some trivia related to the actual topic of a conversation.
- The dialogue is directed according to the Intent classification of the user input.
- and if needed, knowledge base is queried for updated information
- And finally, if the Out-of-domain classification recognizes an unexpected user input whenever there is, the Neural Response Generator produces a coherent response based on the context of the conversation. Otherwise, it is the scripted dialog.
Main Components
-
Skimmer: extract user information from sentences using regular expressions, and then stored the attribute-value into User Profile
-
User Profile: essentially stores information about the user talking to Alexa:
- long-term profile: global information the bot needs when the same user converses again later
- short-term profile: stores information discussed during the current session/dialog
so that short-term profile is reset at the beginning of each session
-
Entity and Knowledge Utilization: include factual information about the entity that the user is interested in. This means you need to do:
- entity recognition: a sequence tagging task performed by Bi-LSTM
- entity linking and knowledge base: utilize external public domain-specific dataset to obtain information about the recognized entity
-
Dialog Management: there are several small scripted dialogs (of intents), which are of high quality and will be of focus of this system. Then, since there are several dialogs, a dialog selector is used when a small dialog finished and needs to find a continuation dialog:
- the dialog selector collects information about the previous context, such as user profile, topics discussed (from tags), and some additional constraints if the new dialog can start (prerequisites)
- if there is no trivia presented for the presently discussed topic, choose a trivia
- if there are some scripted dialogs that fulfill the constraints, consider them
- if there is none, use the neural response generator
-
Trivia Selection: trivia scraped from reddit, and a model for outputting an embedding for scoring cosine similarity of a trivia and the current context is used
- during scraping, vector embeddings are also stored with texts
- during runtime, a candidate trivia list is retrieved using full-text search
- context of $n=2$ most recent utterance-response pairs is encoded
- cosine similarity computed and most relevant trivia is selected
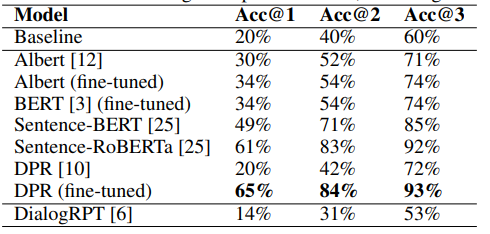
experimentally, the choice of model is determined empirically:
-
Intent and OOD Classification: since each user utterance is seen as intents, the scripted dialog cannot continue if an intent is OOD from the script:
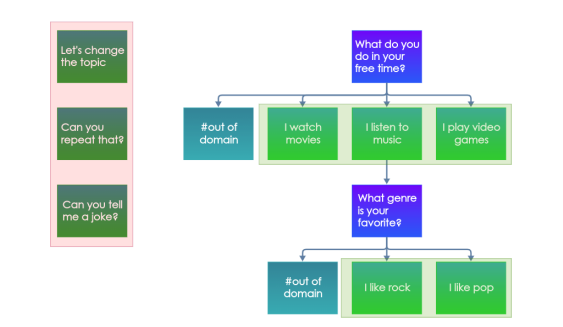
where there are two intents in question:
- global intent: used/can occur at anywhere
- local intent: should be in the tree
again, a combination of a) cosine similarity using a model b) filtering out intents if cosine similarity is not high enough c) if non is left, the intent is OOD.
Which model to use is again chosen empirically, but notice that since such a task is not common in other dsets, they had to artificially create one using existing dset by leaving some intents out, and also hand-annotated a new one
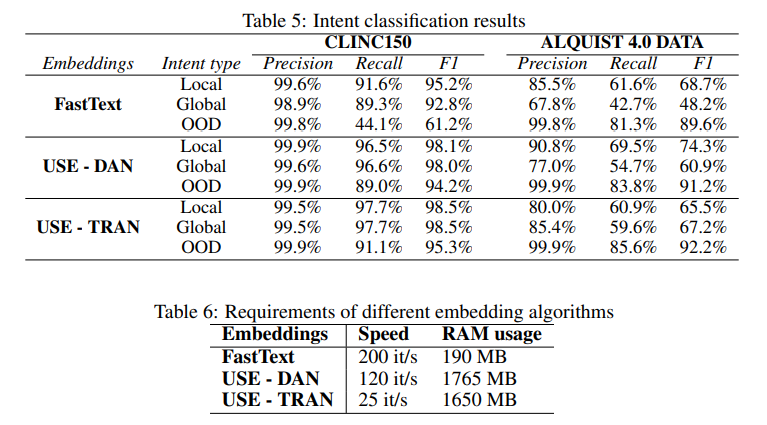
notice that now performance speed also matters
-
Neural Response Generator: used in two tasks: a) if OOD, use this model to generate b) generates a follow up question when a trivia is selected in the dialog manager. Notice that the aim of this is to compensate the incomplete scripted dialog in some cases, but the major focus should be on the success/controllability of the scripted dialog:

where notice that the hand-designed dialog is restored at the end. To have this controllability, the model:
- either generates a question or a statement (otherwise content generated is quite random)
- so that statements followed by a question would be engaging
- and statement itself can be used to bridge the gap between generated and hand-designed content
To achieve this, essentially:
- DialoGPT model is used, where the special token
QUESTIONandSTATEMENTis appended/prompted along with the context - when DialoGPT generated a few candidate questions/statements, a DialoRPT is used to rank the generated content
- tested on several datasets, by:
- using NLTK tokenizer and CoreNLP to annotate each sentence as a statement or a question
- then can convert many existing dialog dataset into such a format for generation
results:
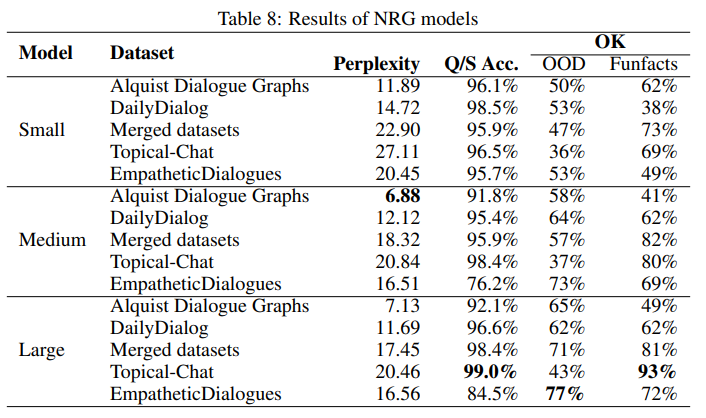
where for evaluation both automatic metric and human evaluation is used:
- automatic metric is straightforward as the labels are known
- human evaluation is done on if the generated content is relevant and factually true, i.e. it is
OK - this is done similarly for checking the follow-up question generation after a trivia/fun facts, hence the two columns under
OK
Jason Wetson Guest Lecture
-
Long term research goal
-
ParlAI - collection of datasets, architectures, and integeration with Amazon MT
-
find things that don’t work, but make your fix general
-
what is missing in current LM such as GPT-2/3:
- knowledge and hallucination in GPT-3
- hook on a retrieval system to incorporate knowledge and hence hallucinate less
-
making an open domain dialog agent
- wanted to have various skills such as Peronality, Emphathy, etc.
- Hence collected trainning data on those skills
- trained Blenderbot
- Blenderbot 1: just stacking transformers
- Blenderbot 2: lemon pick examples, and fix them. For exmaple, very forgetful, and a lot of factual errors
- to solve factual errors, added internet search being part of the bot (generate an internet search query)
- to solve the memory problem, had an addiitonal long term memory module to retrieve information
- can even be used to recommend pizza places
- Blenderbot 3: a bigger transformer, but collect more data to fix prior errors (e.g. still 3% hallucinations)
- takes feedback live from people to learn during interactions, so data from adversarial testers could be used!
- an big architecture, deciding if to do internet search, geneatre response, access memory, etc.
-
how do we use those feedbacks from humans?
-
Director: for each token, add a classification head on thumb-up or down. Therefore, when you generate, you can combine the two scores
-
https://arxiv.org/pdf/2206.07694.pdf
-
when you thumbs down, label entire sentence as negative. Will that smudge down good words, hence the how do you evaluate that classifier. This is what it does, but it still works.
-
-
however, in some cases that labelling can be more sensitive: e.g. if you have a gold correction sentence corresponding to a sentence, then you can align and extract the part of the sentence that is wrong.
-
Still Problems on Chatbots
- why is repetition neuron degenration, liable to repeat
Future of Chatbots:
- how controllable is it to be applied in real life? Jason: probably not medical. But for entertainment, for gaming, recommendations pretty confident.
- Future of incoporating multimodal input into conversations? Jason: if text can be toxic, images can be even more toxic
Knowledge Enriched Dialog Systems
Dialog system but aims to use/find external information to make responses more factual
Increasing Faithfulness in Knowledge-Grounded Dialogue with Controllable Features
Aim: Make a dialog system that is controlled to stay faithful to the evidence. They approach this by:
- adding control tokens prepended to the input sequence
- train dataset using additional information on the objectiveness, lexical precision, and entailment (it generated response follows from the given evidence)
Setup
-
the general idea is to use a piece of evidence (provided beforehand) added to the conversation history as input

-
to train this type of model, dataset with only informative utterances are needed, but that kind does not exist. Since the only available ones (e.g. Wizard of Wikipedia) are generated by humans, they mix chi-chat utterances/subjectivity to objective informative facts in their responses
-
to deal with it, you either remove all subjective ones (e.g. has personal pronouns), but that leaves too little training data left
-
or, as used in this paper, they score existing samples based on objective voice, lexical precision (sticking to fact), and entailment to provide additional signal during training and hence control during inference
- ablation study shows that those control does change performance
- those control tokens are discussed next
-
-
for training, Wizard of Wikipedia is used because there is a gold-labelled evidence provided in the dataset
Model
-
tested on GPT2 and T5, hence overall pipeline looks like:
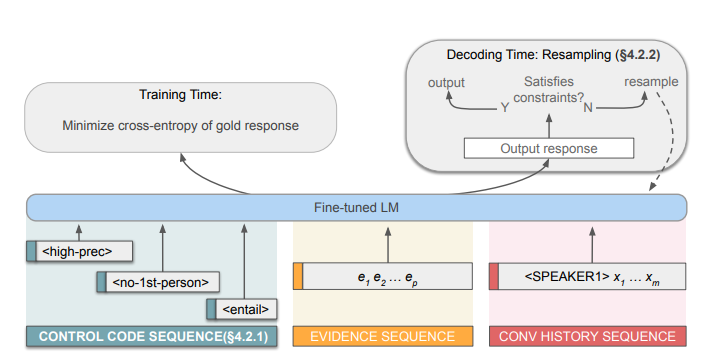
-
they used two approaches in total to add control
- added the special control code during training:
- objective voice: estimated as a binary variable whether if first person pronoun is included
- lexical precision: want most of the words in the response to be contained somewhere in the evidence (drawback is semantic similarity missing). This is then mapped to
<high-prec>,<med-prec>, and<low-prec> - entailment: a binary variable to encourage response semantically entailed by the evidence. During training those are scored by a SOTA natural language inference model to estimate its entailment. Always
<entailed>during inference
- resampling: sample for $d$ times until a satisfactory response is found
- added the special control code during training:
-
after training, performance is evaluated by
-
automatic metric scoring the responses on objective voice, lexical precision, entailment, and BLEU score compared to the original gold response
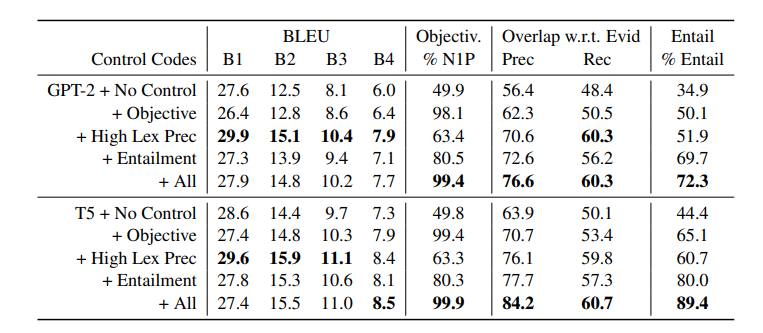
where ablation study is also here. However, since those metrics are all self-designed, human eval is needed.
-
human evaluation: subsample examples from generated response from the previous experiment and ask MT to score:
Table 4 Table 5 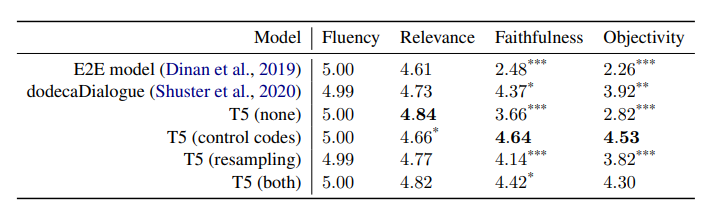

where it seems that there is better faithfulness (to evidence) and objectivity
-
those scores are also found to be highly correlated to the automatic eval scores
-
notice that the gold-evidence is itself relevant to the conversation. So if I just copy-paste, or just summarize the evidence, won’t that give me near perfect score on all three dimensions + probably also highly relevant and high fluency (since the evidence is a fluent text)? Trade off between abstractive and extractive summarization
-
-
Language Models that Seek for Knowledge: Modular Search & Generation for Dialogue and Prompt Completion
Aim: An e2e model that includes capability of Search-Engine, Knowledge Extraction, and Response Generation all into one single model, while treating them as separate modular functionality. The final aim is again to be an open-domain knowledge grounded conversational agent.
- achieved by using appending special tokens in the encoder (or decoder) to indicate which module is being invoked
- done study on treating each module as a separate model as well, but only found marginal improvement while model size becomes 3x big
Setup: the overall pipeline would look like:
-
search module: input dialog context, generate a relevant search query for internet search engine (Bing)
-
knowledge module: input the dialog context + returned documents (intersecting with Common Crawl and take top 5) and generate their most relevant portion to the context (i.e. extracting the useful portion)
-
for GPT based backbone, just append
-
for T5 based backbone, do a fusion-in-decoder which is essentially processing Question + Each Passage in parallel by an encoder, then concatenate the hidden encoder states, and feed into decoder (the model thus performs evidence fusion in the decoder only, and we refer to it as Fusion-in-Decoder)
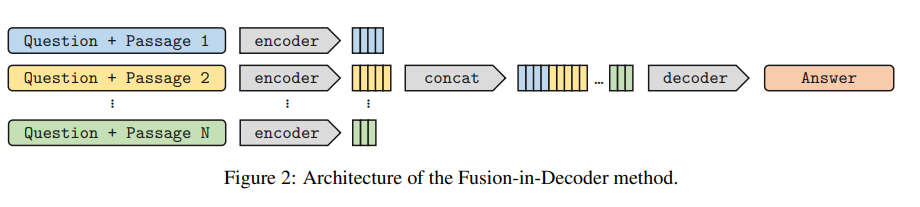
note that this style was also used a lot in Multi-Modal (visual-semantic grounding) work
-
-
response module: input context and the extracted knowledge, and generate a response.
Models:
- in addition to GPT and T5, they additionally trained an encoder-decoder model from scratch, and called it SeeKeR
- specifically, it is pretrained on Reddit as well as LM tasks used in RoBERTa and CC100en
Training: two trainable tasks are proposed:
-
Tasks for dialog
- search module task: using Wizard of Internet which has relevant search queries as labels, train supervised
- knowledge module tasks: need to extract knowledge from documents. Therefore, knowledge grounded dialog datasets with gold knowledge annotations are used, as well as QA datasets.
- response module tasks: can reuse much dataset in the knowledge task by using context + gold knowledge response (and their special tokens) to generate the gold label response
-
Tasks for LM: improve language ability for each component, hence they are based on Common Crawl and is large in size. Also, this will be directly training for the prompt completion task, which is essentially LM
- search module tasks: predict document titles from document
- knowledge module task: constructed a dataset where document contain the retrieved sentence in addition to the document, and the task is to get the retrieved sentence (i.e. extract only the portion that is relevant to the question)
- response module task: input context plus the knowledge sentence and target is next sentence, using the same dset as above
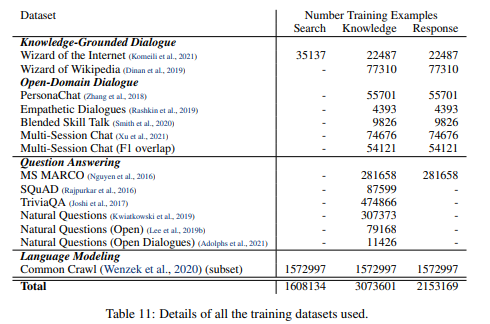
Evaluation
-
compare against models such as BlenderBot 1,2, etc
-
Automatic Evaluation: can be done using Knowledge F1 (overlap of the dialog response with annotated gold knowledge)
- seems that only with gold knowledge response the model is working
- TODO knowledge F1 ignores the semantic, and a lot of discrepancy with the human evaluation?
-
Human Evaluation: since this is e2e, it can converse with MT. Then for each turn in a conversation, they are asked to score several attributes from how knowledgeable it is to its engagingness.
Automatic Human 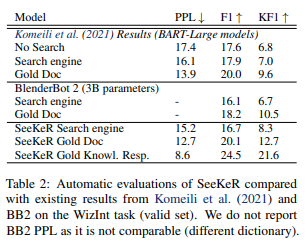
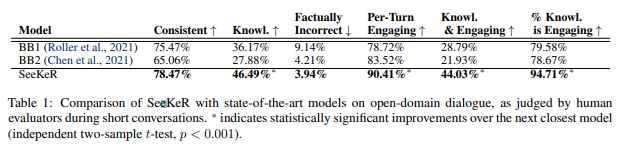
-
Ablation Study:
-
done on the pretraining objectives with those additional dialog datasets
-
testing if the additional LM task is helpful or not
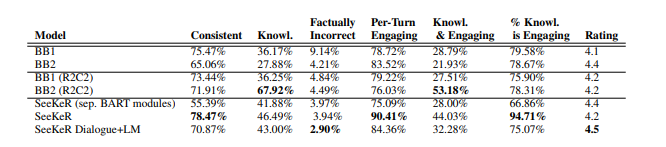
TODO it seems that with LM it is better, so are the modules compared the one with LM or the “standard SeeKeR”?
-
tested if separating each task to a different module would help. It does marginally but 3x the size
-
-
Prompt Completion: in addition to conversing, it can perform prompt (part of a factual statement) and complete it with factual information
- used topical prompts, ranges from Prime Minister of Haiti to the Rio Carnival
- prompts look like
In recent developments we have learned the following about <TOPIC>and then ask the model to continue - evaluation is done by human as well
-
Effect of Multi-Task Training
- Prompt Completion: a fully multi-tasked SeeKeR model performs very well, superior to all our GPT2-based SeeKeR models on every metric
- Open-Domain Dialog: The model performs comparably, if not better, in all automated metrics on the task. In human evaluations, results suffer compared to the dialogue fine-tuned only model, with most metrics being lower
Mixed Social and Task-Oriented Dialogue Systems
There is a goal, such as donation, but to be effective social strategies are required (e.g. to persuade, might need personal stories)
INSPIRED: Toward Sociable Recommendation Dialog Systems
Aim: Lack of dataset annotated with sociable strategies, but want to validate whether sociable recommendation strategies are effective for making a successful recommendation (which is task-oriented)
- design an annotation scheme related to recommendation strategies based on social science theories
- analyze and show that strategies such as sharing personal opinions or communicating with encouragement more frequently lead to successful recommendations
Dataset: the Inspired dataset
- since we are doing recommendation, they curate a database with movies and make sure they include movie trailers and metadata information
- then a dataset is constructed by MT to
- as a recommender: gather preference information and make recommendation
- as a seeker: looks of recommendation, and gets to watch the trailer at the end (used as an indicator of task success)
- additional collection details
- first fill out personality traits
- perform the conversation
- perform a post-task survey of demographic questions
- Seeker asked to rate the recommendation and get a chance to skip or watch the trailer
- strategy annotation
- divide the recommendation strategy into two categories
- sociable strategies: eight strategies related to recommendation task to build rapport with seeker
- e.g. personal opinion, personal experience, similarity, encouragement, etc.
- what they want to test, if this is effective in task-oriented setting
- preference elicitation: to know the seeker’s taste directly
- e.g. experience inquiry, opinion inquiry
- (non-strategy: other utterances such as greeting)
- sociable strategies: eight strategies related to recommendation task to build rapport with seeker
- first ask expert to label, then use those to evaluate MT’s labels and get consistent ones based on Kappa agreement
- divide the recommendation strategy into two categories
- recommendation success annotation: success if defined if seekers finished watching a substantial portion (50%) of the recommended movie trailer and rate the trailer with a high score
Results
-
found that social strategies does correlate to the probability of successful recommendation
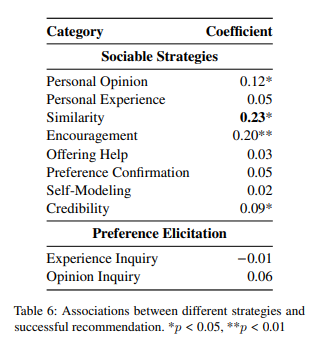
-
examine if the quality of the movie matters more than recommendation
- TODO: “adding movie attributes such as genre, recent release data have an impact on successful recommendation” how is this related to the question? I imagine something like measuring the correlation between quality of the movie v.s. successful recommendation and failed ones.
- found that 96% of recommended movies are covered by the top five genres
Modeling: recommendation dialog system
-
evaluate and show that using the strategies in this
Inspireddataset can create a better recommendation system -
baseline dialog model uses two separate pretrained language models to learn the recommender and the seeker separately
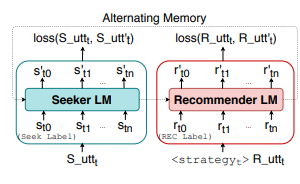
additionally, key terms such as movie names and actor names are delexicalized to terms such as
[Movie_Title_0]for later replacement
-
strategy-incorporated model: generate both the sentences but also strategies
- The model first generates five candidate sentences. Then, it randomly selects a generated candidate that either contains “encouragement” strategy or has the greatest sentence length
- so the model is only either doing encouragement or any other DA but has is the longest = i.e. prioritize encouragement, then longest
-
use human evaluation to see which system is better (or can’t tell which one is better) in terms of fluency, naturalness, persuasion …
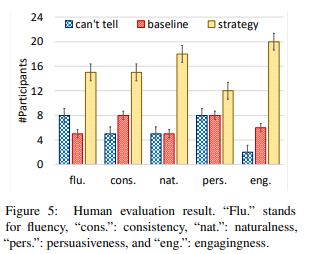
TODO why, if you only prioritize encouragement, you can better fluency, consistency, naturalness? How much is this due to selecting long sentences?
Effects of Persuasive Dialogs: Testing Bot Identities and Inquiry Strategies
Aim: investigate how identities (if you know the bot is actually a bot) and inquiry strategies (ask personal related questions v.s. task related questions) influence the conversation’s effectiveness. Specifically, it is measured by the performance on
Persuasion4Gooddataset.
Hypothesis
- Hypothesis 1: Both identities (whether if you think it is chatbot or human) yield equivalent persuasive and interpersonal outcomes.
- Hypothesis 2: Personal inquires will yield greater persuasive and interpersonal outcomes than non-personal inquiries.
- Hypothesis 3: There is an interaction effect between chatbot identity and persuasive inquiry type on persuasive and interpersonal outcomes.
- We speculate that if the chatbot tries to interact in a personal and human-like way (e.g., by asking personal questions), people may feel uncomfortable, which can subsequently degrade the interpersonal perceptions of the partner as well as their persuasiveness
- e.g. if chatbot perceived as human + doing personal inquiry makes it more persuasive
Setup
- use
Persuasion4Gooddataset - categorized the 10 persuasion strategies into two groups
- persuasive appeals: do persuasion such as emotional appeal
- persuasive inquires: ask questions to facilitate persuasion. This is further split into
- Non-personal Inquiry refers to relevant questions without asking personal information. It include two sub-categories: 1) source-related inquiry that asks if the persuadee is aware of the organization, and 2) task-related inquiry that asks the persuadee’s opinion and experience related to the donation task.
- Personal Inquiry asks about persuadee’s personal information relevant to donation for charity but not directly on the task, such as “Do you have kids?”
Dialog System
-
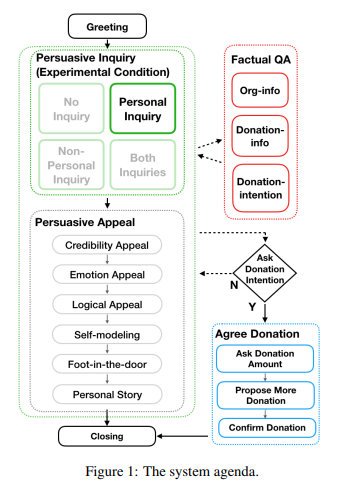
use agenda-based dialog system, meaning that the flow/intent of what to say is more or less predefined
-
the overall model thus contains three main components
- NLU: input user utterance and output user dialog act
- a hard task and hence enhanced the input with sentiment score, context information output from CNN and pretrained character embedding, got around 62%
- TODO uses a regular expression and pre-defined rules to reach 84.1%. What happened here?
- Dialogue Manager: outputs the next system dialog act, but follows the agenda shown above
- the first green block is the control experiment: want to measure if having each of the four strategy would affect overall persuasion = if personal inquires yield more persuasiveness
- then, the system proceeds to persuasive appeal, where a fixed strategy order is used
- finally, when user dialog act is `agree-donation` (predicted by NLU), enter
Agree Donationstage and always present the three task in the order: ask donation amount, propose more donation, … - in addition, a factual QA component is there in case if user asked fact related questions related to the charity
- Natural Language Generation: there are three ways to generating: a) template base, b) retrieval-based from the training dataset and c) generation
- template-based for Persuasive Inquiry: we want to study the effects of different persuasive inquiries instead of the impact of the surface-form; therefore, the surface-forms of the persuasive inquiries should be a controlled variable that stays the same across experiments.
- retrieval-based persuasive appeal: want to also be templated based but now you have a large context, hence that doesn’t work anymore
- NLU: input user utterance and output user dialog act
Evaluation
- designed 2x4 cases
- 2 cases of having bot being labelled as
JessieorJessie (bot) - 4 cases of each of the persuasive inquiry strategy: personal + non-personal inquiry vs. personal inquiry vs. nonpersonal inquiry vs. no inquiries
- 2 cases of having bot being labelled as
-
first found not much difference in which strategy used overall
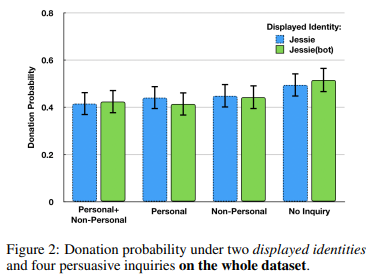
but then they found that participants are perceiving bots are humans or vice versa despite the given label
-
found that if bots are perceived as human, then the above it matters
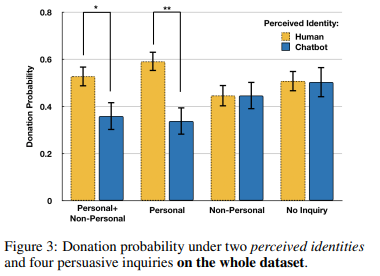
this shows that being a human is more persuasive hence:
- nullifies Hypothesis 1, which claims being perceived as human or machine does not matter
- supports Hypothesis 2, that using personal inquires help
-
finally, we can check cases when the person believed in the given labelled identity
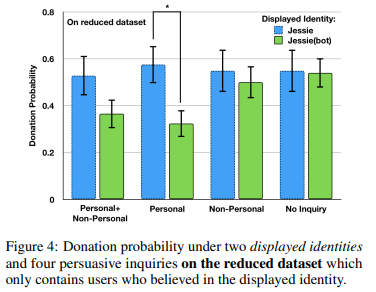
where this means that if bot’s identity does not matter, then in each pair of blue and green bar it should be same height:
- when participants talked to “Jessie (bot)” but perceiving it as a human, they were also more likely to donate than those in the same condition but perceiving it as a bot. In contrast, when participants talked to “Jessie” but suspected it was a bot, they were least likely to make a donation, which supported the UVM in Hypothesis 3
- also, result showed that “Jessie (bot)” would decrease the donation probability ($\beta$=−0.52, $p$<0.05). So the bot’s identity matters in the persuasion outcome, which again disproves Hypothesis 1