COMS4118 Operating Systems
- Week 1 - Introduction
- Week 2
- Week 3 - 4
- Week 5
- Midterm Solution
- Week 6 - Process Scheduling
- Week 7 - Memory Management
- Week 8 - 10 - File System
- Virtual File System
- Disk and Disk I/O
- Data Organization on HDD
- Data Organization on SSD
- HDD and RAID
- File System Review
- Actual Linux Implementation
- Linux File System
- struct inode (in memory)
- struct file (in memory)
- struct superblock (in memory)
- struct dentry (in memory)
- struct task_struct (in memory)
- c libfs.c (generic)
- c init.c
- func do_mount()
- func legacy_get_tree()
- c fs/open.c
- func dcache_dir_open
- func dcache_readdir
- func d_alloc_name()
- snippet sub-dir iteration
- snippet iget_locked
- snippet create file/folder
- Linux Disk I/O
- Linux File System
- Week 11 - I/O System
- Useful Kernel Data Structures
- Useful Things to Know
Week 1 - Introduction
OS 1 Logistics
- Course Website
- includes TA OH sessions
- https://www.cs.columbia.edu/~nieh/teaching/w4118/
- Issues with the course
- Use the w4118 staff mailing list,
w4118@lists.cs.columbia.edu- e.g. regrade request
- Or email to Professor Jason personally
- Use the w4118 staff mailing list,
- Homework Assignments 50%
- Lowest will be dropped
- Submitted via
git, and by default latest submission counts (or, you can specify which submission)- instructions available on https://w4118.github.io/
- Codes can be written anywhere, but testing must be done in the VM machine of the course
- Using materials/code outside of your work needs a citation (in top-level
references.txt)- this includes discussions from fri.,ends
- except for materials in the textbooks
- see http://www.cs.columbia.edu/~nieh/teaching/w4118/homeworks/references.txt
- Details see http://www.cs.columbia.edu/~nieh/teaching/w4118/homeworks/
- Synchronous Exams 50%
- Midterm 20%
- Final 30%
Cores of the Course:
- How the underlying C APIs work
- Concurrency
- threading
- synchronization
- Programming in the Kernel
- build, compile, run your own OS
What is an OS
Heuristics: Are applications part of an OS? Is browser part of an OS?
Microsoft and Netscape. Microscope basically bundled the browser Netscape with their OS!
- the government accused Microsoft for taking a potential monopoly in software as well
OS Kernel + OS environment
Kernel = Core part of an OS
where:
- A kernel provides APIs to its upper levels
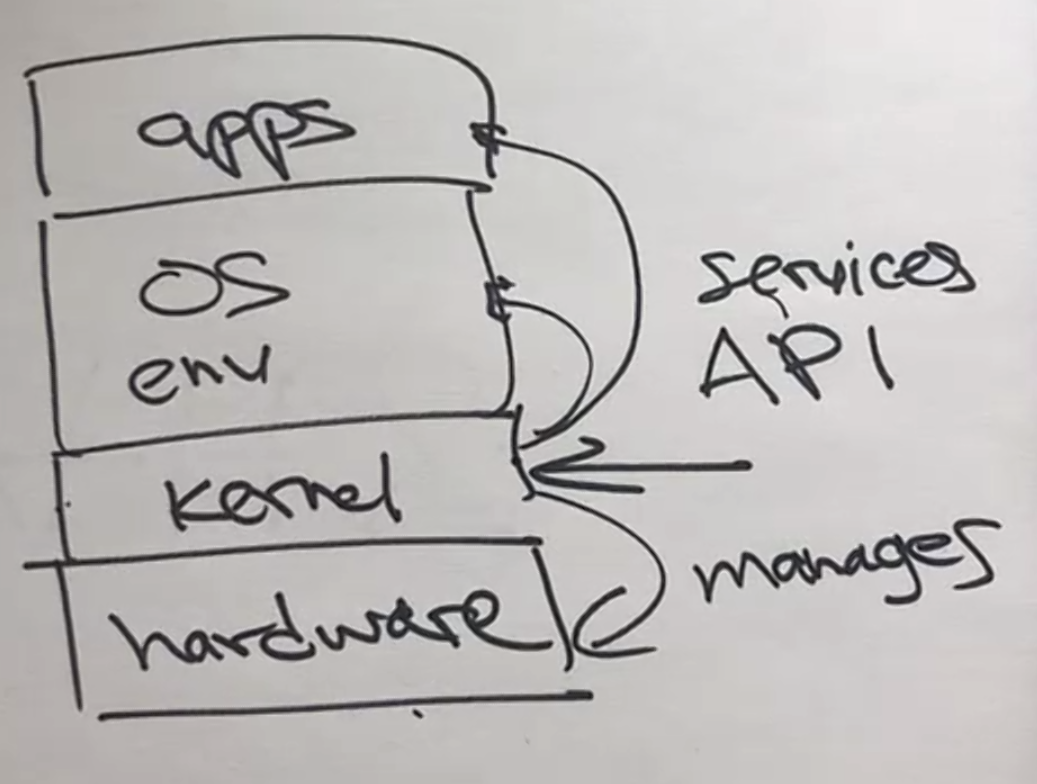
Things we need an OS to do:
- manage the computer’s hardware
- provides a basis for application programs and acts as an intermediary between the computer user (and applications) and the computer hardware
- to do this, OS supply some API/System Calls so that users/applications can use them
- run a program (process)
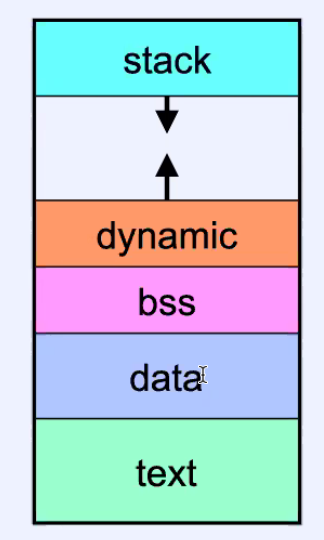
Reminder:
To run that process, the OS needs to manage the Unix Address Space
where:
- remember that your code stays in
text, static/global data indataandbss, and etc.
- the difference between
dataandbssis that one of them stores initialized data, one of them initialized data
What OS Do
First, a computer system contains:
- A hardware
- CPU, memory, I/O devices
- An OS
- provides an environment within which other programs can do useful work
- depends on the need, OS can “act” completely differently (different implementation)
- for example, when you have a shared system, the OS will tend to maximize resource utilization— to assure that all available CPU time, memory, and I/O are used efficiently and that no individual user takes more than her fair share. (As compared to a personal laptop, which does not care about resource sharing)
- from the computer’s point of view, the operating system is the program most intimately involved with the hardware.
- In this context, we can view an operating system as a resource allocator.
- An application program
- word processors, spreadsheets
A small history of OS
- The fundamental goal of computer systems is to execute user programs and to make solving user problems easier. Computer hardware is constructed toward this goal.
- Since bare hardware alone is not particularly easy to use, application programs are developed. These programs require certain common operations, such as those controlling the I/O devices. The common functions of controlling and allocating resources are then brought together into one piece of software: the operating system.
However, we have no universally accepted definition of what is part of the operating system.
Yet a popular definition is: operating system is the one program running at all times on the computer—usually called the kernel.
- Along with the kernel, there are two other types of programs:
- system programs, which are associated with the operating system but are not necessarily part of the kernel, e.g.
- System Software maintain the system resources and give the path for application software to run. An important thing is that without system software, system can not run.
- application programs, which include all programs not associated with the operation of the system, e.g. a web browser
- system programs, which are associated with the operating system but are not necessarily part of the kernel, e.g.

where:
- usually when you execute commands in CLI such as
ls, they basically executes a system program (a file), which then in turn will execute some underlying system calls to perform the task
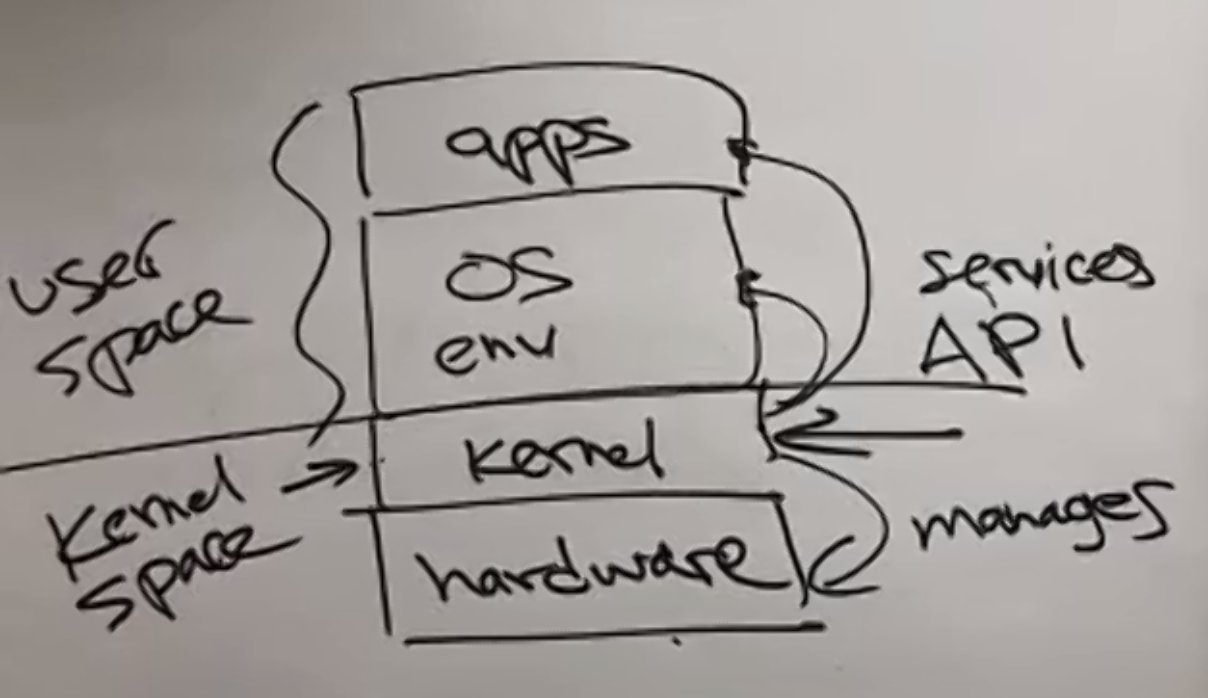
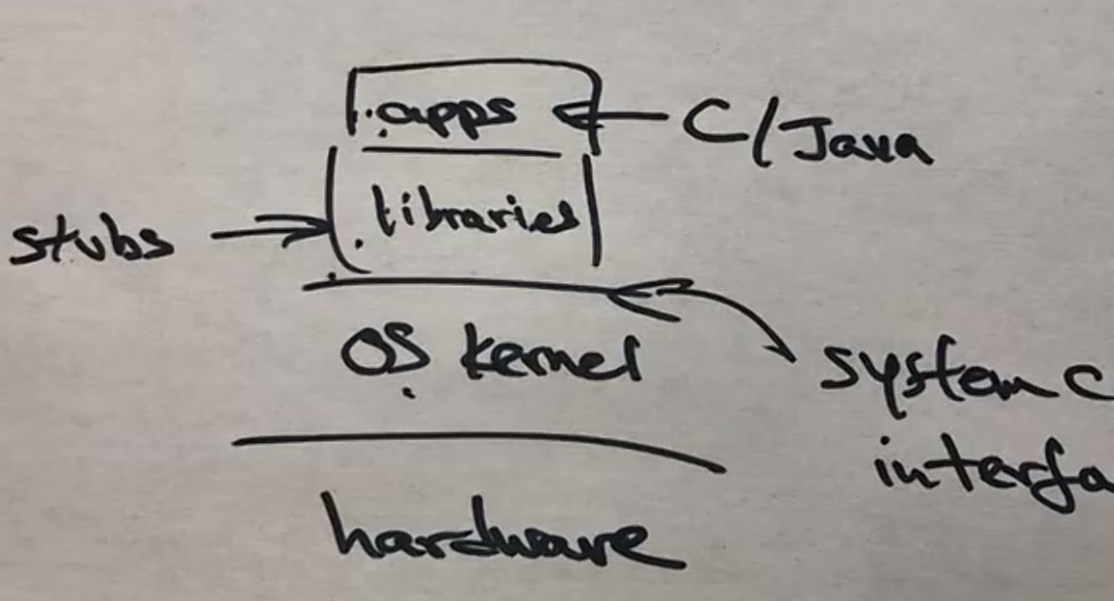
Kernel vs OS
- Sometimes, people refer to the OS as the entire environment of the computing system, including the kernel, system programs, and GUIs (possibly some native applications as well).
- Below shows the general structure of a UNIX system, in particular, what a kernel does and the structure of the entire layered environment

System Calls
Definition:
- A system call (commonly abbreviated to
syscall) is the programmatic way in which a computer program requests a service from the kernel of the operating system- Therefore, it is the sole interface between a user and a kernel
- it is also made to return integers
Here, you need to know that:
-
the difference between user space and kernel space is:
Definition: Errors in System Calls
- Since using the APIs depend on the programmer, OS puts error code in
errnovariable
- errors are typically indicated by returns of
-1
For Example: A System Call
write() is actually a system call of UNIX:
if(write(df, buffer, bufsize) == -1){
// error!
printf("error %d\n", errno); // for errno, see below
// perror
}
where:
- Many system calls and system-level functions use the
errnofacility. To deal with these calls, you will need to includeerrno.h, which will provide something that looks like a global integer variable callederrno.- There are a standard set of predefined constants corresponding to common error conditions (see
errno.hfor details).
- There are a standard set of predefined constants corresponding to common error conditions (see
Reminder:
- C does not have any standard exception signaling/handling mechanism, so errors are handled by normal function return values (or by side affecting some data).
However, for most of the other cases, this is what happens:
where:
- the library does a little abstraction for making system calls easier
- for example, the
libclibrary - for example,
fread()andfwrite()are library functions. (They also do not return integers.)
- for example, the
Creating a Process
Heuristics:
- How does an OS create and run a process?
- First, we need to remember that a process has:
- an Unix Address Space (stack, heap, etc.) to keep track of what the program is doing
- a stack pointer to tell you where the stack is
- a program counter to tell you which line of code/instruction to run
- registers for storing data
- etc.
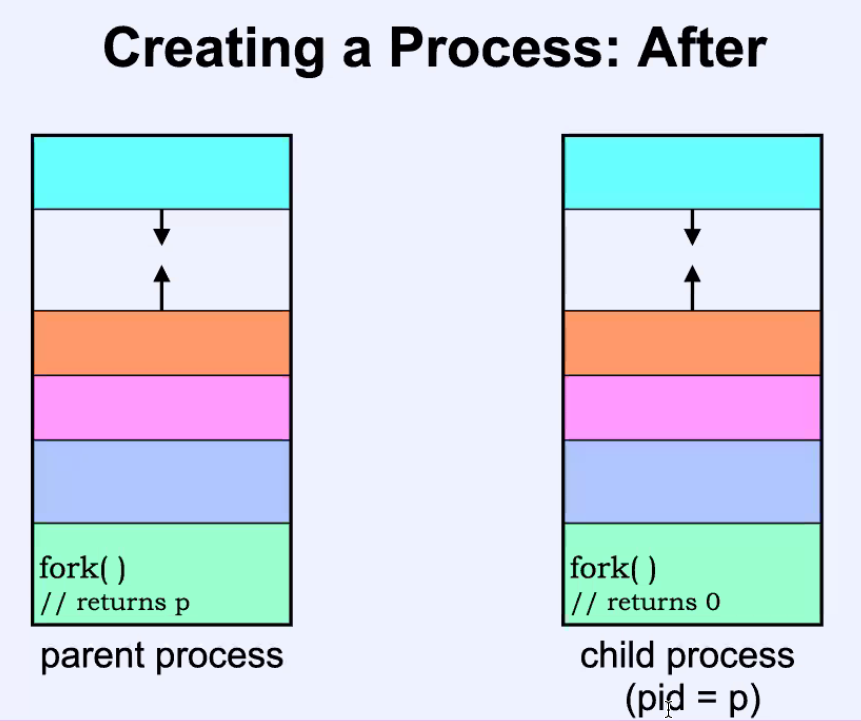
In fact, we know one C function (abstracted away by the OS) to create a process: fork()
Reminder:
- After calling
fork()during one of your process, it will create another process:
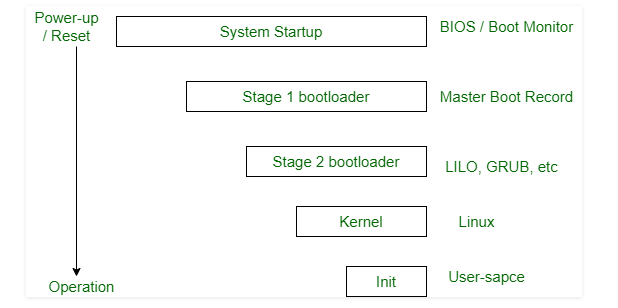
Booting an OS
In summary, the following happens:
- When a CPU receives a reset event—for instance, when it is powered up or rebooted—the instruction register is loaded with a predefined memory location, and execution starts there
- At that location is the initial bootstrap program. This program is in the form of read-only memory (ROM). (This means it is fixed code)
- The PC will be loaded with something called a BIOS (Basic Input/Output System.) On modern PCs, the CPU loads UEFI (Unified Extensible Firmware Interface) firmware instead.
- Then, that bootstrap program (e.g. BIOS) hand off to a boot device
- typically, it is on your hard disk/SSD. Traditionally, a BIOS looked at the MBR (master boot record), a special boot sector at the beginning of a disk. The MBR contains code that loads the rest of the operating system, known as a “bootloader.”
- basically, it will read a single block at a fixed location (say block zero) from disk (so the bootloader) into memory and execute the code from that boot block
- For large operating systems (including most general-purpose operating systems like Windows, Mac OS X, and UNIX) or for systems that change frequently, the operating system is on disk.
- boot device is configurable from within the UEFI or BIOS setup screen.
- so you can switch that to read from a USB stick
- typically, it is on your hard disk/SSD. Traditionally, a BIOS looked at the MBR (master boot record), a special boot sector at the beginning of a disk. The MBR contains code that loads the rest of the operating system, known as a “bootloader.”
- Then, depending on the choice, that boot block/bootloader (e.g. GRUB) can:
- contain the entire sophisticated code that load the entire OS into memory and begin execution
- contain a simple code that only knows where to find the more sophisticated bootstrap program on disk and also the length of that program.
- On Windows, the Windows Boot Manager (bootloader) finds and starts the Windows OS Loader. The OS loader loads essential hardware drivers that are required to run the kernel—the core part of the Windows operating system—and then launches the kernel.
- On Linux, the GRUB boot loader loads the Linux kernel.
- Now that the full bootstrap program has been loaded, and you can now work with it.
- On Linux, at this point, the kernel also starts the
initsystem—that’ssystemdon most modern Linux distributions
- On Linux, at this point, the kernel also starts the
The next step of
initis to start up various daemons that support networking and other services.
- X server daemon is one of the most important daemon. It manages display, keyboard, and mouse. When X server daemon is started you see a Graphical Interface and a login screen is displayed.
Questions
-
Question
“The boot block can contain a simple code that only knows where to find the more sophisticated bootstrap program and the length…”. Why do the more work of locating the other bootstrap program? Why can’t it just load the sophisticated boot strap program directly?
Is it there to allow users to potentially install and then choose from different OS?
Week 2
Using your Computer System
After booted, how do we use it?
- Explanation of what happens at boot up time is written in section Booting an OS
Some History:
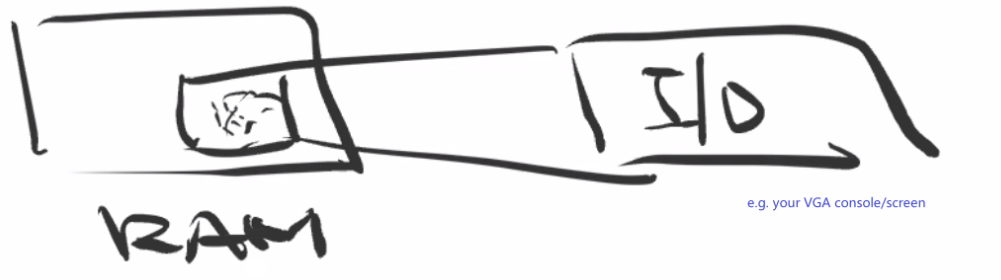
Before OS comes up:
people uses assembly code to manipulate registers/RAM
commonly used ones include x86 with AT&T syntax:
mov $0xDEAD, %ax # to move the value 0xDEAD into register axthis means that to do I/O, you will need to use a Memory Mapped I/O, which basically maps addresses of an I/O device to your RAM, so that you have a way to directly read/write data into the I/O
However, when the OS booted up, it is in 16-bit mode, so that you can only address up to
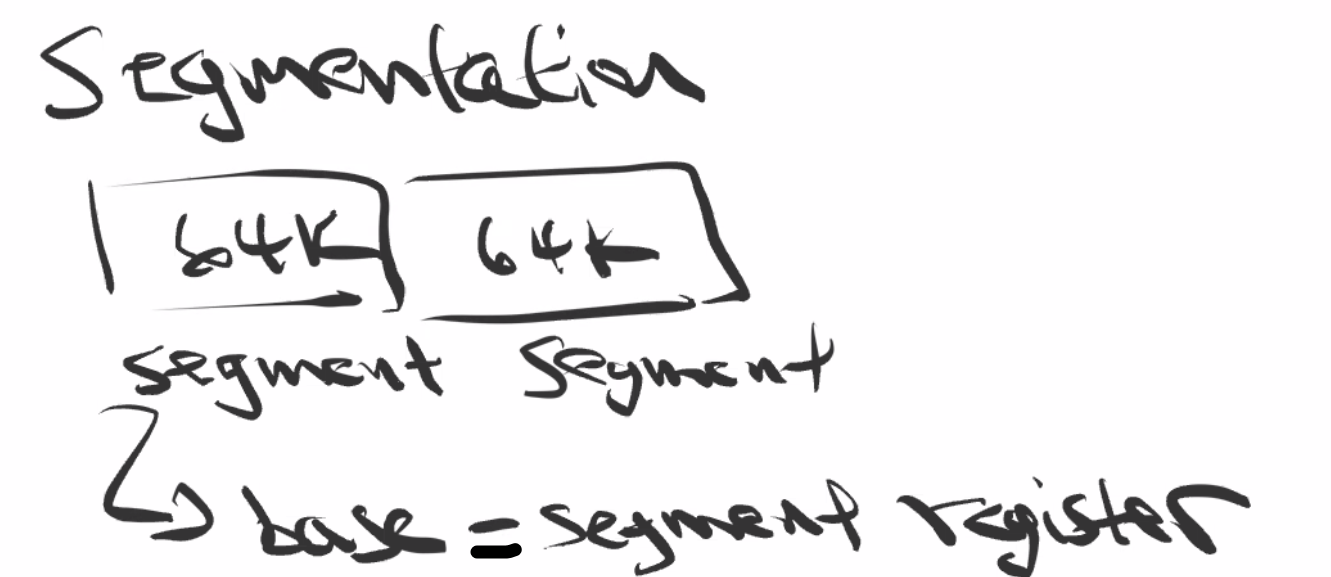
0xFFFFTherefore, to access addresses outside of that, we need to use segmentation:
So addresses are calculated with:
address = base * 0x10 + offsetthen to access address
0xf0ff0:mov $0xf000, %ax mov %ax, %ds # you cannot directly copy literals into ds register movb $1, (0xff0) # accesses 0xf0ff0
Now, when you have an OS
- All we needed to do is to use
OS System Calls- without all the difficulty with assembly code and stuff
- Can use the C library
- Can have multiple programs and run multiple processes
But in essence, it just becomes that the OS have the control all the hardware.
- instead of yourself being able to manipulate via the assembly code
- so the OS has to deal with:
- program interrupt timers
Interrupts
How does interrupt works?
In between your instructions, the CPU checks from the interrupt line, whether there has been an interrupt, and will handle that before proceeding.

where:
- attached to the CPU, you have an INTR(upt) line
- from that PIC, you can attach things such as:
- timer
- disk
- networks
- all of which that can generate interrupts
Interrupt vs Trap
- A trap is a software-generated interrupt.
- e.g. to call system calls
- Interrupts are hardware interrupts.
Typically, there is also an interrupt descriptor table (IDT) to that contains pointers to handlers to each type of interrupt
- so it has a bunch of functions, that can be used to handle different types of interrupts
- for example, when a time interrupt happened, the CPU checks the table, and looks at and goes to the address of the time interrupt handle (where some code will be there to handle time interrupts)
- those handlers will be OS code (managed by the OS)
- this IDT table is stored in the
idtregister- this will be setup by the OS at boot/load time
Note
- When your CPU has to deal with an interrupt, you need your CPU to push every register holding current data into the stack
- Then, when the CPU is done with the interrupts, it pops off from the stack, so that it can deal with last processed code
Exception
Exceptions happen within the instruction, as compared to interrupts between instructions
- for example, when you attempt to divide by 0, the CPU itself will throw an interrupt
CPUs tend to throw an exception interrupt (in between exceptions), on things like division by zero, or dereferencing a NULL pointer.
- These interrupts are trapped, like when hardware interrupts, halting execution of current program and return control to the OS, which then handles the event.
CPU Modes
This could be very useful to deal with constrain accesses/control security .
- user mode
- privileged mode (kernel)
When you are running user programs, your OS switches the CPU into user mode
When you are running necessary system calls, your OS switches the CPU into kernel mode
Some privileged instructions involve:
- writing the
idtregister - disable interrupts
- if disabled, it means interrupts still comes, but the CPU will not check them between instructions anymore
- switch into kernel/privileged mode
- etc, so that the OS can maintain control
Init Process
- The
initprocess (referred in UNIX often) sets up everything, and is the first process - All the following processes are the children of this
initprocess
Week 3 - 4
Processes
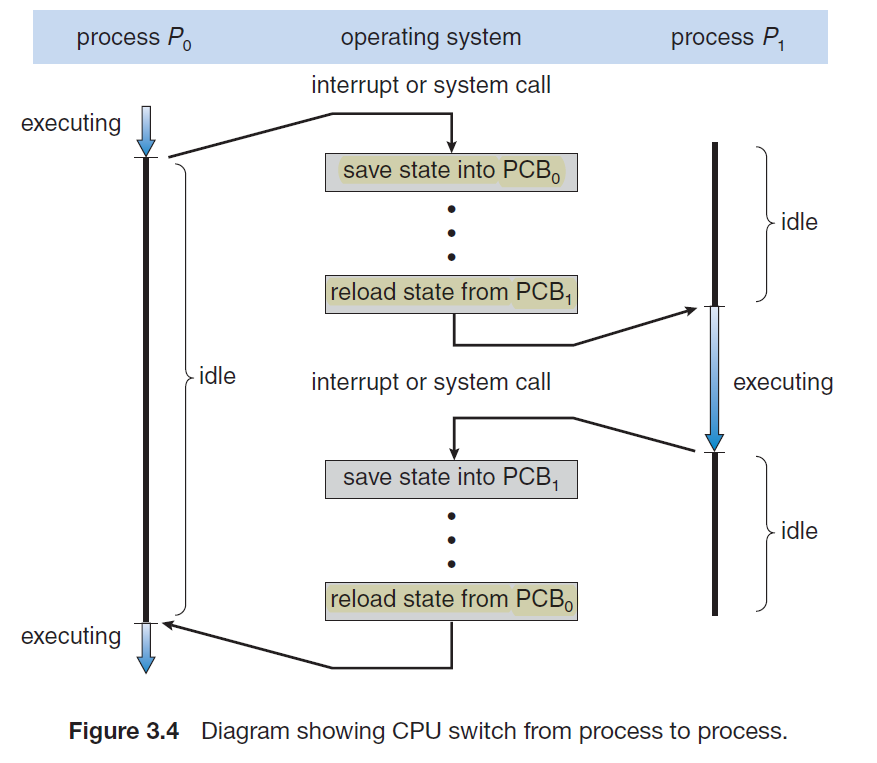
Each process is represented in the operating system by a process control block (PCB)—also called a task control block:
Life Cycle of a Process
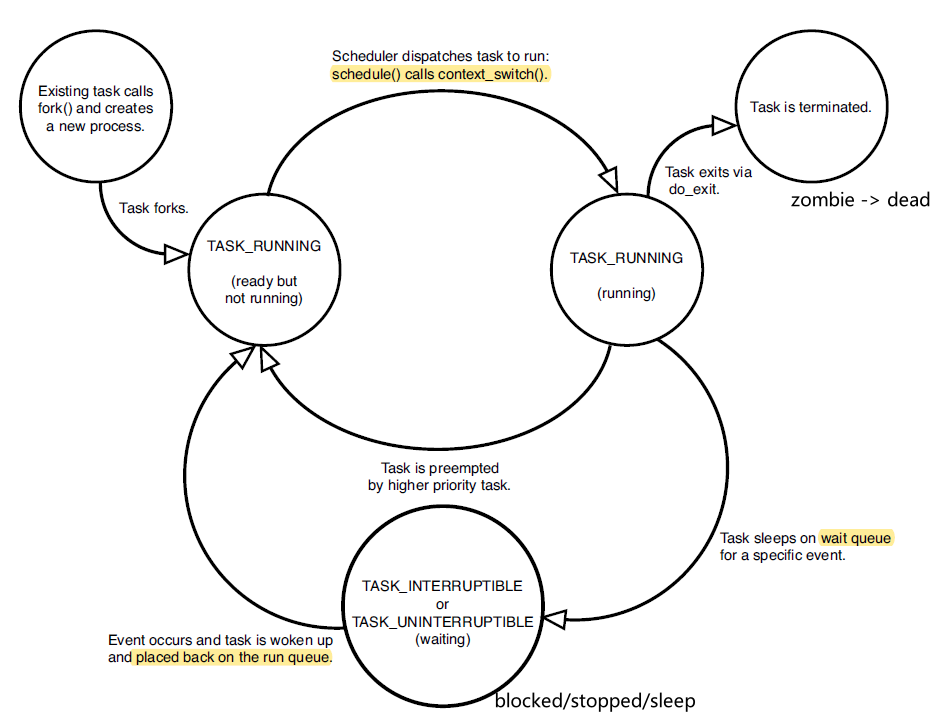
-
it is created
- e.g.
fork()
- e.g.
-
it is queued in a ready queue
- process scheduling
- in the state diagram:
- runnable
-
the scheduler calls the process and now it is running
- in the state diagram
- running
- blocked means your program is waiting on something (e.g. User input, I/O), and not proceeding in execution
- wakes up means your process has got what it is waiting, and goes back in the queue
- in the state diagram
-
program terminates
- the program will not exit unless it has entered the running state
- this explains why, sometimes sending
Ctrl-Cwill not work, because the process has not yet went out from the blocked state
- this explains why, sometimes sending
- in the state diagram
- terminate
- for a process, first it becomes a zombie (parent has not called
wait()yet), then it is dead
- for a process, first it becomes a zombie (parent has not called
- terminate
- the program will not exit unless it has entered the running state
In Linux, this is how the state is recorded
#define TASK_RUNNING 0x0000 /* the obvious one */ #define TASK_INTERRUPTIBLE 0x0001 /* e.g. the Ctrl-C comes, OS interrupts/switches it to runnable */ #define TASK_UNINTERRUPTIBLE 0x0002 /* e.g. the Ctrl-C comes, it is still blocked */ #define __TASK_STOPPED 0x0004 #define __TASK_TRACED 0x0008 /* Used in tsk->exit_state: */ #define EXIT_DEAD 0x0010 /* Process exited/dead AND it has been wait() on by its parent */ #define EXIT_ZOMBIE 0x0020 /* Process exited/dead, but the task struct is still in the OS */ #define EXIT_TRACE (EXIT_ZOMBIE | EXIT_DEAD) /* Used in tsk->state again: */ #define TASK_PARKED 0x0040 #define TASK_DEAD 0x0080 /* First state when Processes is killed FROM running. */ /* Afterwards, it goes to EXIT_ZOMBIE */ #define TASK_WAKEKILL 0x0100 #define TASK_WAKING 0x0200 #define TASK_NOLOAD 0x0400 #define TASK_NEW 0x0800 #define TASK_STATE_MAX 0x1000
Process Scheduling
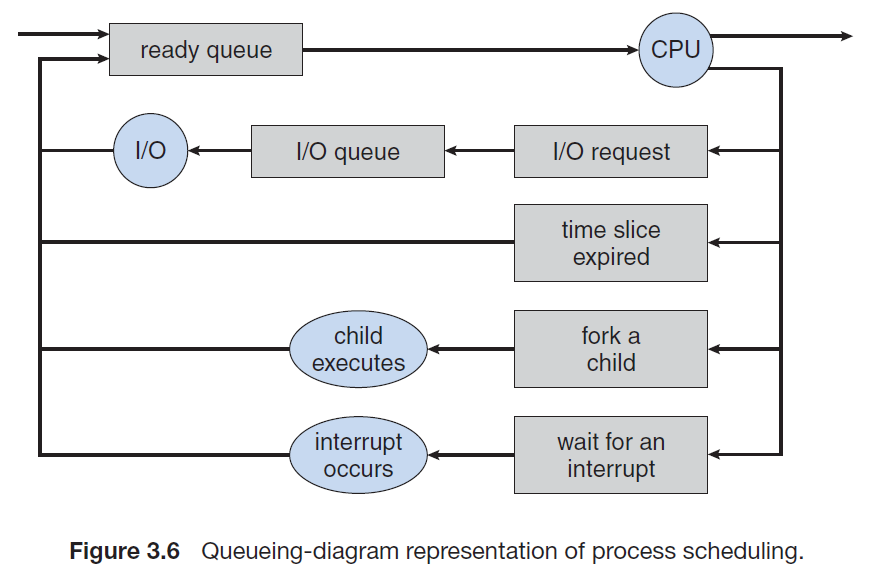
where:
- Each rectangular box represents a queue.
- Two types of queues are present: the ready queue and a set of device queues.
- The circles represent the resources that serve the queues, and the arrows indicate the flow of processes in the system.
A new process is initially put in the ready queue. It waits there until it is selected for execution, or dispatched. Once the process is allocated the CPU and is executing, one of several events could occur:
- The process could issue an I/O request and then be placed in an I/O queue.
- The process could create a new child process and wait for the child’s termination.
- The process could be removed forcibly from the CPU, as a result of an interrupt, and be put back in the ready queue.
Context Switch
This basically refers to the phenomenon that the OS scheduler decides to switch the running current process to running another one (e.g. due to time being used up).
For Example:
- A user process
Phas used up the time it has for execution - Time Interrupt sent to kernel
- Kernel
scheduleanother processQto run. In fact, this is what happens:- process
Pchanges its state to, for example,Running -> Runnable - process
Pthen callsscheduleto schedule another process to run
- process
- So at this point, a context switch happened
- you need to store the state of process
P
- you need to store the state of process
Process Creation
The init process (which always has a pid of 1) serves as the root parent process for all user processes.
Once the system has booted, the init process can also create various user processes, such as a web or print server, an ssh server, and the like
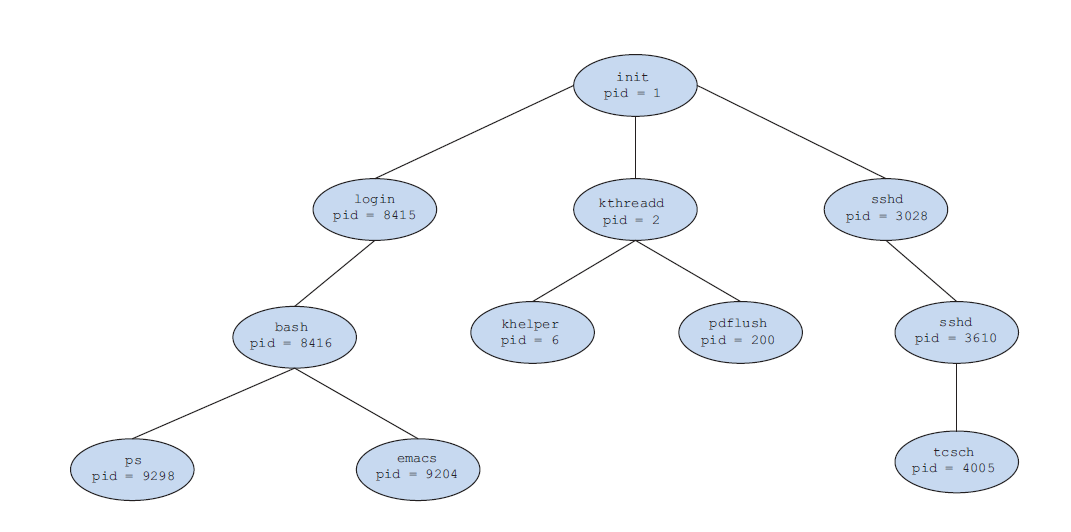
When a process creates a new process, two possibilities for execution exist:
- The parent continues to execute concurrently with its children.
- The parent waits until some or all of its children have terminated.
There are also two address-space possibilities for the new process:
- The child process is a duplicate of the parent process (it has the same program and data as the parent).
- The child process has a new program loaded into it.
Process Termination
A process terminates when it finishes executing its final statement and asks the operating system to delete it by using the exit() system call.
- At that point, the process may return a status value (typically an integer) to its parent process (via the
wait()system call). All the resources of the process—including physical and virtual memory, open files, and I/O buffers—are deallocated by the operating system.
Zombie Process
When a process terminates, its resources are deallocated by the operating system. However, its entry in the process table must remain there until the parent calls
wait(), because the process table contains the process’s exit status.So, a process that has terminated, but whose parent has not yet called
wait(), is known as a zombie process.
- All processes transition to this state when they terminate, but generally they exist as zombies only briefly. Once the parent calls
wait(), the process identifier of the zombie process and its entry in the process table are released.
Orphaned Process
Now consider what would happen if a parent did not invoke
wait()and instead terminated, thereby leaving its child processes as orphans.Linux and UNIX address this scenario by assigning the
initprocess as the new parent
- The
initprocess periodically invokeswait(), thereby allowing the exit status of any orphaned process to be collected and releasing the orphan’s process identifier and process-table entry.
Process Communication
Processes have its own address space. What if we need to share something between two processes?
Inter-process communication (IPC), can be done in two ways:
- message passing
- e.g. signals
- shared memory

Message Passing
Simple Message Passing
This is
where:
signal number, a number indicating some status, such asAhas done its work, and it needsBto proceed
- has nothing to do with Interrupts
singal handler, so that the other process knows what to do with the signal
- obviously,
Bcannot handle the signal untilBruns- e.g.
SIGINT, aims to kill a process, but you could change its implementation in thesignal handler. This is generated byCtrl-C
SIGKILL(forcibly kills the process, does not allow implementation insignal handler)
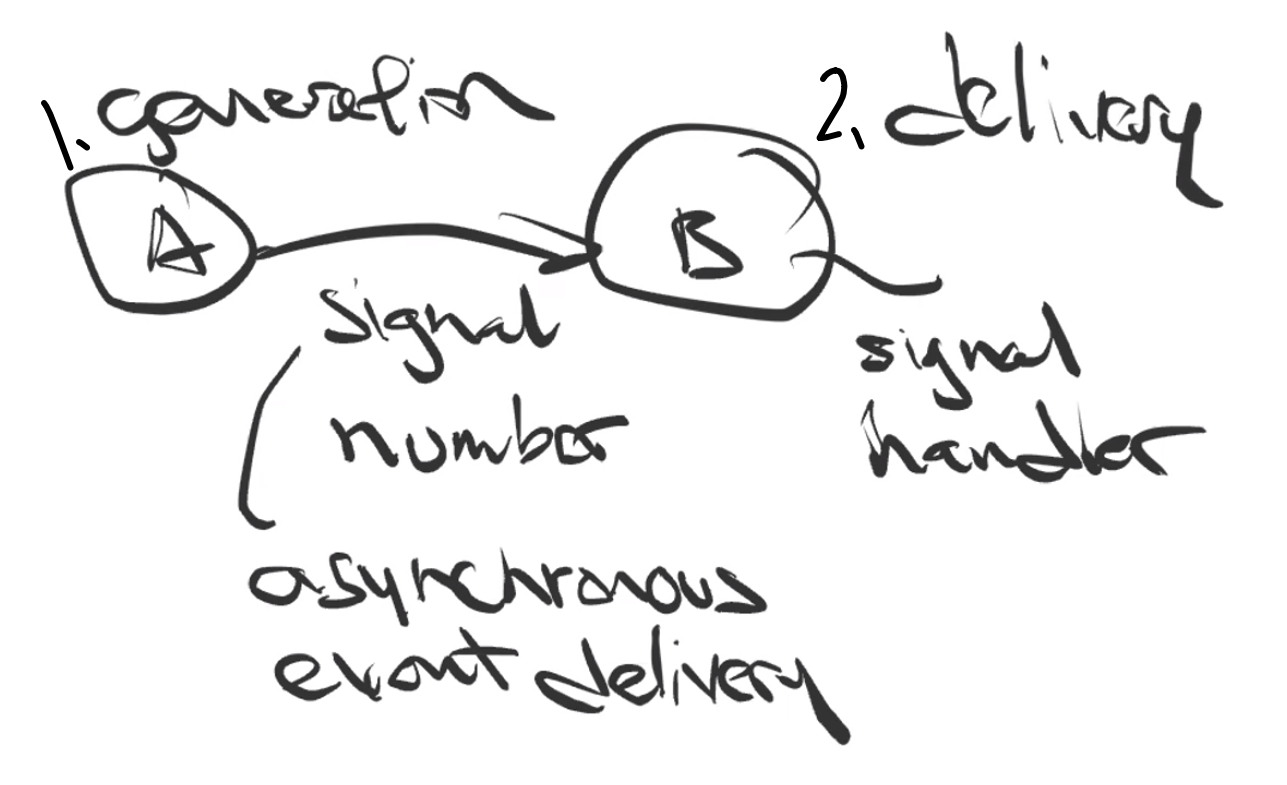
Under the hood, this is how it is implemented. Consider the SIGKILL signal is received by a process:
-
inside
kernel/signal.c-
it has
static int kill_something_info -
in the end, the OS does:
static int send_signal(int sig, struct kernel_siginfo *info, struct task_struct *t, enum pid_type type) { /* Should SIGKILL or SIGSTOP be received by a pid namespace init? */ bool force = false; /* bunch of stuff omitted */ return __send_signal(sig, info, t, type, force); }
-
-
In the end, there is a
sigaddset(&pending->signal, sig);, which adds a signal to the receiving process- the
pendingis basically a field of the task struct, which is a bit map indicating the current signals- in the end,
pendingis asigset_twhich looks likeunsigned long sig[_NSIG_WORDS]
- in the end,
- the
-
After setting the signal, the function in
static int kill_something_infocallscomplete_signal()- this essentially calls
signal_wake_up(), which will wake up the receiving process
- this essentially calls
-
Lastly, the receiving process eventually runs, which means that the OS wants to return back to User mode and run the code of that program.
-
now, during that process, the OS makes the process to be
RUNNING, and the OS does something like (might not be entirely correct):-
prepare_exit_to_usermode(), which calls -
exit_to_usermode_loop, which contains the following:static void exit_to_usermode_loop(struct pt_regs *regs, u32 cached_flags) { while (true) { /* Some code omitted here */ /* deal with pending signal delivery!! */ if (cached_flags & _TIF_SIGPENDING) do_signal(regs); /* other code omitted here */ } } - inside
do_signal, first we callbool get_signal(struct ksignal *ksig) - if you have
SIGKILL, then it will go intodo_group_exit() - then it does
void __noreturn do_exit(long code). This is also what theexit()system call does in the end- in addition to clean ups and exiting, it also sets the process
tsk->exit_state = EXIT_ZOMBIE; - then there is the ` do_task_dead(void)
, which calls__schedule(false);` to tell the OS to schedule another task to do some work, since this task is dead
- in addition to clean ups and exiting, it also sets the process
-
-
Note:
- In step 4 of the above, we see that if the process is still blocked and cannot get back to
RUNNABLE->RUNNING, then the process cannot process its signal, hence pressingCtrl-Cwill not exit it.
Lastly, how does the OS implement the wait() functionality for zombies?
- under the cover, it uses the
wait4()function inkernel/exit.c- this calls
kernel_wait_4, which eventually callsdo_wait() - which calls
do_wait_thread() - which calls
wait_consider_task() - if the task has exit state being a
Zombie, then it callswait_task_zombie()- this changes the state to
EXIT_DEAD - then it calls
release_task(). At this state, everything is cleaned up for the task and it is gone
- this changes the state to
- this calls
Shared Memory
In short, there APIs for a program to share memory, but it is difficult to use
- as a result, a solution is to use threads, which has the default behavior of shared heap/data
- therefore, it is much more easier to use threads for shared memory
Threads and Cores
Cores
- each core appears as a separate processor to the OS
- so with 4-cores, you can execute 4-threads in parallel
- with 1-core, you can execute 4-threads concurrently (by interleaving)
Threads
-
a thread is a part of a process, and is like a virtual CPU for the programmer
-
a thread provides better code/data/file sharing between other threads, which is much more efficient than the message passing/memory sharing technique between processes
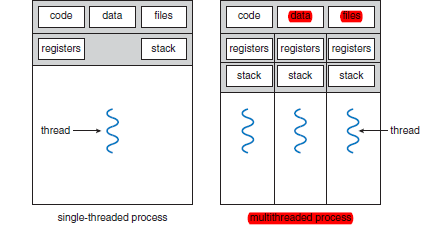
A Thread is:
- basically an independent thread of execution, so that you can execute stuff
A Thread contains:
CPU Registers such as
PC,SP,GPR, etc (separated)Stack (separated)
Other Memories (e.g. heap) is shared
- so you basically have the same address space
where:
- in the end there is just one address space for those threads
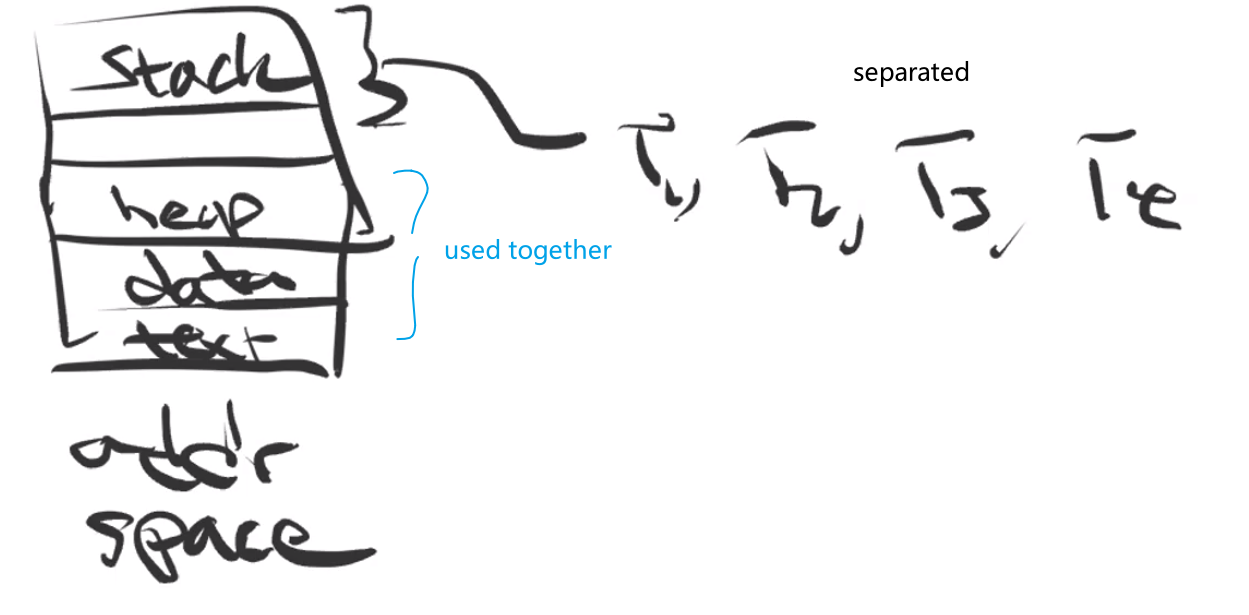
Multithreading Models
In real life, the threading happens as follows/is implemented as follows:
- user thread - the user controllable/programmable thread.
- The kernel does NOT know about them. This means they are by default belonging to a single process.
- this means for multithreading to actually occur, you need to create/manage copies of the processes
- kernel thread - managed by the OS, hence manages user threads
- your OS knows about them, so if one thread gets a
SEGFAULTfor example, then only that thread will die, but not other kernel threads - if your OS has kernel threads, then this could lead a user thread maps to a kernel thread for actual execution.
- your OS knows about them, so if one thread gets a
For mapping user thread to kernel thread, there are the following possibilities:
-
one to one model
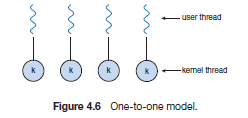
currently used by many OS.
- Disadvantage: creating a user thread means also needing to create a kernel thread, which is some overhead
-
many to one model
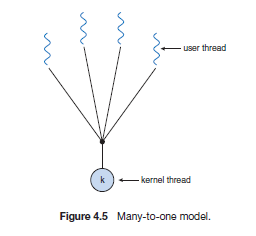
- Disadvantage: no parallelism, only concurrency. Also, if one thread invoked a blocking system call, all the rest of the threads are blocked as well.
-
many to many model
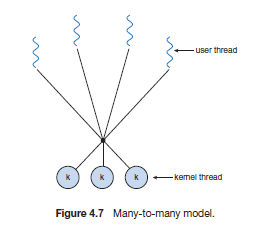
Linux Implementation of Threads
In Linux, a thread is represented as the same as a process:
-
it is
struct task_struct -
the only difference would be the
memory spaceof atask_struct, which would be shared for threads -
a common function to use would be
clone()-
using
CLONE_VMflag, then threads will share their memory/address space -
using
CLONE_THREADflag, then threads are grouped together, hence associated to a single process -
for example:
#define CSIGNAL 0x000000ff /* signal mask to be sent at exit */ #define CLONE_VM 0x00000100 /* set if VM shared between processes */ #define CLONE_FS 0x00000200 /* set if fs info shared between processes */ #define CLONE_FILES 0x00000400 /* set if open files shared between processes */ #define CLONE_SIGHAND 0x00000800 /* set if signal handlers and blocked signals shared */ /* etc. */
-
struct task_struct {
/* stuff omitted */
struct mm_struct *mm; /* address apce */
struct mm_struct *active_mm;
/* stuff omitted */
}
Forking Implementation
Forking
- The behavior for a thread of a process to
fork()is defined as follows:
- it will copy the thread itself, and allocating a separate memory address
What happens exactly is:
-
A thread calls
__do_fork(), which callscopy_process()- remember that a thread and a process to Linux are the same, i.e.
struct task_struct
- remember that a thread and a process to Linux are the same, i.e.
-
inside the
copy_process(), it- creates/allocates a new
task_struct - initializes some fields
- copies information from the previous process, such as
copy_mm()
- creates/allocates a new
-
for example, inside
copy_mm(), if we have setCLONE_VM:-
static int copy_mm(unsigned long clone_flags, struct task_struct *tsk){ /* bunch of codes omitted */ if (clone_flags & CLONE_VM) { mmget(oldmm); mm = oldmm; /* shared address space */ goto good_mm; } /* otherwise, a separate address space */ mm = dup_mm(tsk, current->mm); } -
additionally. with
CLONE_THREAD:if (clone_flags & CLONE_THREAD) { p->exit_signal = -1; /* adds the group leader */ p->group_leader = current->group_leader; p->tgid = current->tgid; } else { if (clone_flags & CLONE_PARENT) p->exit_signal = current->group_leader->exit_signal; else p->exit_signal = args->exit_signal; p->group_leader = p; p->tgid = p->pid; }
-
Group Leader
- By default, each thread/process is its own group leader
- in the end, added to a new
thread_groupof the group leader being itself- e.g. if you
fork(), you are creating a new process/thread, so the new guy will be its own group leader- If you
clone()and configuredCLONE_THREAD, then the new guy will have the calling thread’s group leader as the group leader
- in the end, added to the existing
thread_group- this also populates
siblingandreal_parentand etc.
Threading APIs
Some threading APIs are implemented on the kernel level (results directly in system calls), whereas some are implemented on the user level.
For example, consider the task of calculating:
\[\sum_{i=1}^n i\]- POSIX Pthread
#include <pthread.h>
#include <stdio.h>
int sum; /* this data is shared by the thread(s) */
void *runner(void *param); /* threads call this function */
int main(int argc, char *argv[])
{
pthread t tid; /* the thread identifier */
pthread attr t attr; /* set of thread attributes */
if (argc != 2) {
fprintf(stderr,"usage: a.out <integer value>\n");
return -1;
}
if (atoi(argv[1]) < 0) {
fprintf(stderr,"%d must be >= 0\n",atoi(argv[1]));
return -1;
}
/* get the default attributes */
pthread attr init(&attr);
/* create the thread */
pthread create(&tid,&attr,runner,argv[1]);
/* wait for the thread to exit */
pthread join(tid,NULL);
printf("sum = %d\n",sum);
}
/* The thread will begin control in this function */
void *runner(void *param)
{
int i, upper = atoi(param);
sum = 0;
for (i = 1; i <= upper; i++)
sum += i;
pthread exit(0);
}
Note:
to join multiple threads, use a
forloop:#define NUM THREADS 10 /* an array of threads to be joined upon */ pthread t workers[NUM THREADS]; for (int i = 0; i < NUM THREADS; i++) pthread join(workers[i], NULL);
- Windows Threads
#include <windows.h>
#include <stdio.h>
DWORD Sum; /* data is shared by the thread(s) */
/* the thread runs in this separate function */
DWORD WINAPI Summation(LPVOID Param)
{
DWORD Upper = *(DWORD*)Param;
for (DWORD i = 0; i <= Upper; i++)
Sum += i;
return 0;
}
int main(int argc, char *argv[])
{
DWORD ThreadId;
HANDLE ThreadHandle;
int Param;
if (argc != 2) {
fprintf(stderr,"An integer parameter is required\n");
return -1;
}
Param = atoi(argv[1]);
if (Param < 0) {
fprintf(stderr,"An integer >= 0 is required\n");
return -1;
}
/* create the thread */
ThreadHandle = CreateThread(
NULL, /* default security attributes */
0, /* default stack size */
Summation, /* thread function */
&Param, /* parameter to thread function */
0, /* default creation flags */
&ThreadId); /* returns the thread identifier */
if (ThreadHandle != NULL) {
/* now wait for the thread to finish */
WaitForSingleObject(ThreadHandle,INFINITE);
/* close the thread handle */
CloseHandle(ThreadHandle);
printf("sum = %d\n",Sum);
}
}
-
Java Threading
Since Java does not have a global variable, it uses objects in Heap to share data (you need to pass the object into the thread)
class Sum
{
private int sum;
public int getSum() {
return sum;
}
public void setSum(int sum) {
this.sum = sum;
}
}
class Summation implements Runnable
{
private int upper;
private Sum sumValue;
public Summation(int upper, Sum sumValue) {
this.upper = upper;
this.sumValue = sumValue;
}
public void run() {
int sum = 0;
for (int i = 0; i <= upper; i++)
sum += i;
sumValue.setSum(sum);
}
}
public class Driver
{
public static void main(String[] args) {
if (args.length > 0) {
if (Integer.parseInt(args[0]) < 0)
System.err.println(args[0] + " must be >= 0.");
else {
Sum sumObject = new Sum();
int upper = Integer.parseInt(args[0]);
Thread thrd = new Thread(new Summation(upper, sumObject));
thrd.start();
try {
thrd.join();
System.out.println
("The sum of "+upper+" is "+sumObject.getSum());
} catch (InterruptedException ie) { }
}
}
else
System.err.println("Usage: Summation <integer value>"); }
}
Note
There are two techniques for creating threads in a Java program.
One approach is to create a new class that is derived from the
Threadclass and to override itsrun()method.An alternative —and more commonly used— technique is to define a class that implements the
Runnableinterface. TheRunnableinterface is defined as follows:public interface Runnable { public abstract void run(); }
Thread Pools
The problem with the above essentially free threading is:
-
Creation of each thread takes some time
-
Unlimited threads could exhaust system resources, such as CPU time or memory.
One solution to this problem is to use a thread pool.
- The general idea behind a thread pool is to create a number of threads at process startup and place them into a pool, where they sit and wait for work.
- When a server receives a request, it awakens a thread from this pool—if one is available—and passes it the request for service.
- Once the thread completes its service, it returns to the pool and awaits more work.
- If the pool contains no available thread, the server waits until one becomes free.
OS Control
In the following situations, the OS takes control (i.e. OS code runs, including interrupt handler codes)
- On boot time
- When Interrupt occurs
- also Exceptions
- Dealing with Main Memory
- e.g. setting your program address space to use
addrwithin $base \le addr \le limit$
- e.g. setting your program address space to use
- System Calls (API for outside users, a way to enter the kernel)
- e.g. by using a software interrupt, so that OS can take control in between your program
- jumps to interrupt handler to handle it (OS code)
- e.g. implements using a special
syscallinstruction
- e.g. by using a software interrupt, so that OS can take control in between your program
- CPU modes (e.g. kernel mode)
- dealing with security
Kernel
Relationship between OS and Kernel
Operating System Kernel Operating System is a system software. Kernel is system software which is part of operating system. Operating System provides interface b/w user and hardware. kernel provides interface b/w application and hardware. It also provides protection and security. It’s main purpose is memory management, disk management, process management and task management. All system needs operating system to run. All operating system needs kernel to run. Type of operating system includes single and multiuser OS, multiprocessor OS, real-time OS, Distributed OS. Type of kernel includes Monolithic and Micro kernel. It is the first program to load when computer boots up. It is the first program to load when operating system loads.
Reminder:
The Linux Kernel is the first thing that your OS loads:
System calls provide userland processes a way to request services from the kernel. Those services are managed by operating system like storage, memory, network, process management etc.
- For example if a user process wants to read a file, it will have to make
openandreasystem calls. Generally system calls are not called by processes directly. C library provides an interface to all system calls.
Kernel has a hardware dependent part and a hardware-independent part. Codes on this site: https://elixir.bootlin.com/linux/v5.10.10/source contains:
arch/x86/boot- first codes to be executed- initializes keyboard, heap, etc, then starts the
initprogram
- initializes keyboard, heap, etc, then starts the
arch/x86/entrycontains system call codes- remember, user calling system call = stopping current process and switching/entering to OS control
Kernel System Calls
What Happens when a process execute system call?
Basically, the following graph:
in words, the following happened:
- Application program makes a system call by invoking wrapper function in C library
- This wrapper functions makes sure that all the system call arguments are available to trap-handling routine
- the wrapper function also takes care of copying these arguments to specific registers
- The wrapper function again copies the system call number (of itself) into specific CPU registers
- Now the wrapper function executes trap instruction (int 0x80). This instruction causes the processor to switch from ‘User Mode’ to ‘Kernel Mode’
- The code pointed out by location 0x80 is executed (Most modern machines use
sysenterrather than 0x80 trap instruction)- In response to trap to location 0x80, kernel invokes
system_call()routine which is located in assembler filearch/i386/entry.S- the rest is covered below.
How does the kernel implement/deal with system calls? (reference: http://articles.manugarg.com/systemcallinlinux2_6.html)
- You need to first get into Kernel
- Then locate that system call
- Run that system call
In the past:
- Linux used to implement system calls on all x86 platforms using software interrupts.
- To execute a system call, user process will copy desired system call number to
%eaxand will execute ‘int 0x80’. This will generate interrupt0x80and an interrupt service routine will be called.
- For interrupt 0x80, this routine is an “all system calls handling” routine. This routine will execute in ring 0 (privileged mode). This routine, as defined in the file
/usr/src/linux/arch/i386/kernel/entry.S, will save the current state and call appropriate system call handler based on the value in%eax.
For Modern x86, there is a specific SYSCALL instruction
-
Inside
arch/x86/entry/entry.S-
SYSYCALL begins/enters via the line
ENTRY(entry_SYSCALL_64),where:
entry_SYSCALL_64contains/is initialized with an address to the actual function ofentry_SYSCALL_64- it can take up to 6 arguments/6 registers
and after entering, it needs
- a register containing address of the implemented SYSCALL code
-
-
Inside the
ENTRY(entry_SYSCALL_64)-
after a bunch of stack savings, it does
do_syscall_64where:
- this is when the actual code is executed
do_syscall_64again points to an address of the C functiondo_syscall_64(nr, *regs), withnrwould represent theidfor each system call*regswould contain the arguments for the system call- similar to interrupt handler table, there is a “table” for SYSCALL
asm/syscalls_64.hwhich is generated byarch/x86/entry/syscalls/sysycall_64.tbldynamically depending on the hardware spec- for example, one line inside the
tblhas0 common read __x64_sys_read
- for example, one line inside the
some code there does:
- check
nrbeing a legal system call number in the tablesys_call_table - runs that system call with
sys_call_table[nr](regs), wheresys_call_table[nr]would basically be a function
-
-
Inside
include/linux/syscalls.h- you can find the actual definition of SYSCALL in C, which can be used to find the actual implementation
- for example,
SYSCALL_DEFINE0wrapper for functions that takes0arguments,SYSCALL_DEFINE1, …, up toSYSCALL_DEFINE6 - for example,
sys_read()
- for example,
- you can find the actual definition of SYSCALL in C, which can be used to find the actual implementation
-
Inside
kernel/sys.c- you can find the actual implementations of SYSCALL in C
- for example,
SYSCALL_DEFINE0(getpid), which will get translated to__x64_sys_getpid
- for example,
- you can find the actual implementations of SYSCALL in C
Note
sys_read()would be converted dynamically to__x64_sys_readby using#defineswhich basically adds a wrapper__x86to the functions
- this is configured by the
Kconfigfile, and the wrapper is defined atarch/x86/include/asm/syscall_wrapper.h
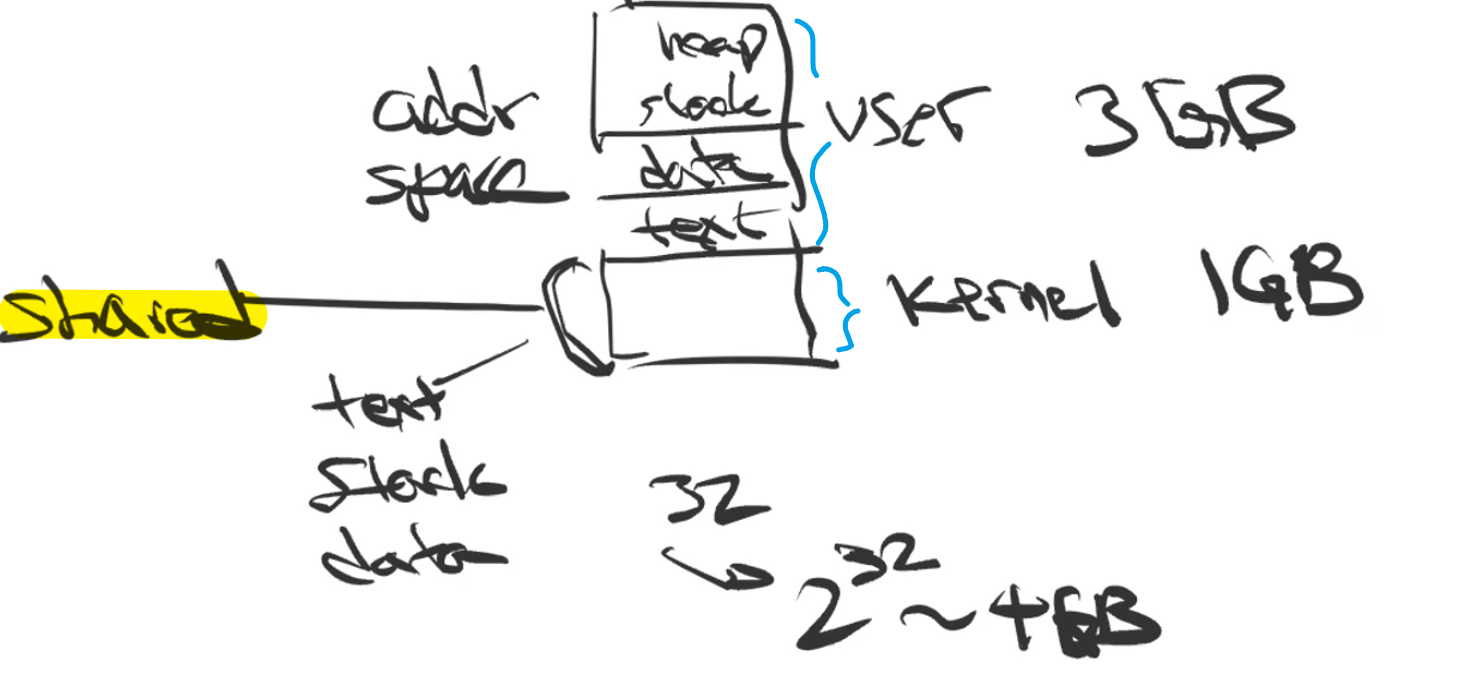
In the View of a Programmer
this is what happens in the virtual memory space:
where:
- every process has a separate/independent user space, but a shared kernel space for system calls (the kernel image is loaded there as well).
- this also means the stack for system call is very limited. So you should not write recursion functions for system calls.
System Call Example
Consider the function gettimeofday
SYSCALL_DEFINE2(gettimeofday, struct timeval __user *, tv,
struct timezone __user *, tz)
{
if (likely(tv != NULL)) {
struct timespec64 ts;
ktime_get_real_ts64(&ts);
if (put_user(ts.tv_sec, &tv->tv_sec) ||
put_user(ts.tv_nsec / 1000, &tv->tv_usec))
return -EFAULT;
}
if (unlikely(tz != NULL)) {
if (copy_to_user(tz, &sys_tz, sizeof(sys_tz)))
return -EFAULT;
}
return 0;
}
where:
- user arguments comes in like
struct timeval __user *, tv__userdenotes that the pointer comes from user spacetvis the variable name
-
since the variables comes from user space, we need to be careful of its validity:
-
struct timespec64 ts; ktime_get_real_ts64(&ts); if (put_user(ts.tv_sec, &tv->tv_sec) || put_user(ts.tv_nsec / 1000, &tv->tv_usec)) return -EFAULT;where we basically create our own structure and copied fields to user’s variable with
put_user()
-
- the error that system call returns is not directly
-1return -EFAULT;- and then a wrapper will populate the error information and then
return -1
Note
- In general, there is no explicit check done by the OS on the number of arguments you passed in for a system call. This means that all you should check in your function are the validity of the arguments you need.
More details on copy_to_user and the other ones:
Copy Data to/from Kernel
Function Description copy_from_user(to, from, n)_copy_from_userCopies a string of n bytes from from (userspace) to to (kernel space). get_user(type *to, type* ptr)_get_userReads a simple variable (char, long, … ) from ptr to to; depending on pointer type, the kernel decides automatically to transfer 1, 2, 4, or 8 bytes. put_user(type *from, type *to)_put_userCopies a simple value from from (kernel space) to to (userspace); the relevant value is determined automatically from the pointer type passed. copy_to_user(to, from, n)_copy_to_userCopies n bytes from from (kernel space) to to (userspace).
Week 5
Process Synchronization
Reminder:
- Cooperating processes can either directly share a logical address space (that is, both code and data) or be allowed to share data only through files or messages.
- The former case is achieved through the use of threads (see Threads and Cores
This chapter addresses how concurrent or parallel execution can contribute to issues involving the integrity of data shared by several processes.
Race Condition and Lock
Consider the case (thread race):
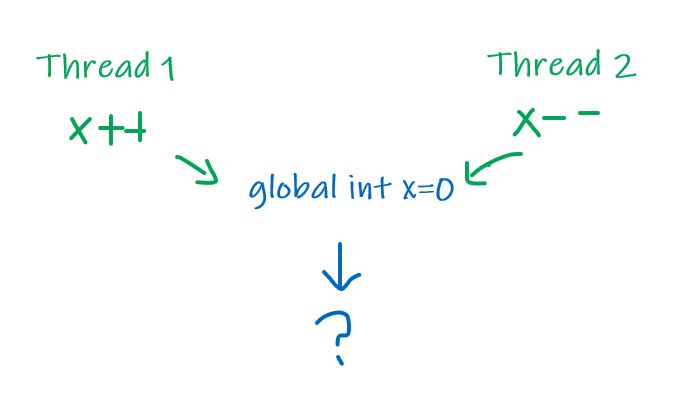
the result has the following possibility:
1, ifT1/T2loadsx=0into register, andT1writes later thanT2back to the memory0, ifT1loadsx=0into register, and writes back to the memory, and thenT2loads and writes back-1, ifT1/T2loadsx=0into register, andT2writes later thanT1back to the memory
This is the problem of none-Atomic operations
- so that the actual operation in CPU has multiple steps
- as a result, you have ambiguity of result when multiple these operations are acting on the same data
Critical Section:
- the critical section is a segment of code that manipulates a data object, which two or more concurrent threads are trying to modify
To guard against the race condition above, we need to ensure that only one process at a time can be manipulating the variable. To make such a guarantee, we require that the processes be synchronized in some way.
- The solution is to get a lock for the critical section:
Lock
so that all operations within a lock will be atomic/mutually exclusive
a lock would have the following property:
- mutual exclusion - only one thread can access the critical section at a time
- forward progress - if no one has the lock for the critical section, I should be able to get it
- bounded waiting - there can’t be an indefinite wait for getting a lock for the critical section
for example, to make
x++atomic with locks:

In general, this is what we need to do:

This is actually very important if you have multiprocessor CPUs:
- since multiple processes can be in the kernel in this case (e.g. calling system calls), they could be manipulating some same kernel data.
- therefore, you need to find a way to lock stuff.
Peterson’s Solution
This is a heuristic solution that:
- demonstrates the idea of a lock
- only works for two processes
- not guaranteed to work on modern computer architectures.

where:
irepresentsProcess i=Process 0jrepresentsProcess j=Process 1
and that:
- Mutual exclusion is preserved.
- $P_0$ and and $P_1$ could not have successfully executed their statements at about the same time 2. The progress requirement is satisfied.
- The bounded-waiting requirement is met.
- There is a bounded waiting, since if one process $P_0=P_i$ is stuck in the loop, the process can get out either by $P_1=P_j$ setting the
flag[j] = falseafter execution or settingturn = i. Both of which guaranteed that $P_0=P_i$ will have at most one wait for one loop in $P_j$
- There is a bounded waiting, since if one process $P_0=P_i$ is stuck in the loop, the process can get out either by $P_1=P_j$ setting the
The actual solution for 2 processes is:

Hardware Implementation
Therefore, one hardware solution to solve this would be:
- disable interrupts, so that once a process is in the critical section, no other process can do work.
- disabling interrupt is atomic itself
However, this is problematic because:
- need privileged instruction (i.e. normal user outside kernel can’t use it directly)
- can only have one lock in the system, since interrupts are disabled for the entire CPU.
- if you have multiple processors, this does not work at all
- need all processors to disable interrupt
- if process $P_0$ is running on $CPU_0$ and process $P_1$ is $CPU_1$. Disabling interrupt on both does not change/interrupt what is already running. Therefore, both $P_0,P_1$ will be running.
The solution for MP (multi-processor) is using:
-
test-and-set (ensured by hardware to be atomic)
boolean test_and_set(boolean *target) { boolean rv = *target; *target = true; return rv; } -
compare-and-swap (ensured by hardware to be atomic)
/* this is made atomic by hardware */ int compare_and_swap(int *value, int expected, int new value) { int temp = *value; if (*value == expected) *value = new value; return temp; }
and implementing:
- spin locks
- blocking blocks
Note:
- under the hood, the code themselves involves more than one instruction. However, this is supported natively by hardware, so that this will be atomic (e.g. locking the communication channel to the main memory when you are loading).
- both lock implementation are:
- busy waiting
- since we have the
whileloop for testing the lock- spin locks
- since we have the
whileloop for waiting- Therefore, both are problematic because spinning locks will be eating up the CPU cycles if there are lots of contentions over a lock
Other Atomic Instructions
For x86 architecture, there are actually a bunch of useful atomic instructions you can use.
For Example:
-
atomic_read(const atomic_t *v) atomic_add(int i, atomic_t *v)- …
- more inside
include/asm-generic/atomic-instrumented.h
Therefore for simple code, you can just use those atomic instructions instead of explicitly grabbing the lock.
Spin Locks
Conventions for Using Spin Locks
the same task that grabs the spin lock should also releases the spin lock
the task that grabs the spin lock cannot sleep/block before releasing it
- otherwise, you might cause deadlock situations
the usual usage of spin locks in code/by programs looks like:
initialize *x; spin_lock(x); /* some work, not sleeping/blocked */ spin_unlock(x);
Advantages of Spin Lock
- No context switch is required when a process must wait on a lock (as compare to a blocking lock), and context switch may take considerable time.
Disadvantages of Spin Lock
- Wastes much of the CPU power if a lot are running for a long time.
Test and Set Spin Lock
Consider the case when you have a global lock of boolean lock=false.
/* this is made atomic by hardware */
boolean test_and_set(boolean *target) {
boolean rv = *target;
*target = true;
return rv;
}
then the spin lock implementation/usage would be:
do {
while (test_and_set(&lock))
; /* do nothing */
/* critical section */
lock = false;
/* remainder section */
} while (true)
where:
test_and_set(&lock)basically locks it by atomically:- letting itself through if
lock=0and assigning it tolock=1to lock it.
- letting itself through if
However, bounded-waiting is not satisfied:
- consider a process that is super lucky and gets to set
lock=1every time before other processes. Then all other processes will have to wait indefinitely.
Compare and Swap Spin Lock
Consider the case when you have a global lock of int lock=0.
/* this is made atomic by hardware */
int compare_and_swap(int *value, int expected, int new value) {
int temp = *value;
if (*value == expected)
*value = new value;
return temp;
}
then the spin lock implementation/usage:
do {
while (compare_and_swap(&lock, 0, 1) != 0)
; /* do nothing */
/* critical section */
lock = 0;
/* remainder section */
} while (true);
where:
- the idea is that the one process will set
lock=1before it enters the critical block, so that other processes cannot enter.
However, bounded-waiting is not satisfied:
- consider a process that is super lucky and gets to set
lock=1every time before other processes. Then all other processes will have to wait indefinitely.
Try Lock
This is basically a lock that, instead of spinning, either:
- obtains the lock
- tries once and stop
Therefore, it is not-spinning, but technically it is not waiting either.
static __always_inline int spin_trylock(spinlock_t *lock)
{
return raw_spin_trylock(&lock->rlock);
}
Kernel Code Examples
First, a couple of code to know:
-
the declaration for
spin_lock()insideinclude/linux/spinlock.h:static __always_inline void spin_lock(spinlock_t *lock) { raw_spin_lock(&lock->rlock); } /* other declarations */ static __always_inline void spin_unlock(spinlock_t *lock) { raw_spin_unlock(&lock->rlock); }which if you dig deep into what it did:
-
spin_lock()eventually calls ` __raw_spin_lock(raw_spinlock_t *lock)` and does 3 thingspreempt_disable();, so that no other process can preempt/context switch this process when it holds the spin lock.- same principle as not sleeping during holding a spin lock
- this has a similar effect (but not as strong) as disabling interrupts
-
` spin_acquire(&lock->dep_map, 0, 0, RET_IP);` grabs the lock
-
LOCK_CONTENDED(lock, do_raw_spin_trylock, do_raw_spin_lock);configures this function into play:static __always_inline void queued_spin_lock(struct qspinlock *lock) { u32 val = 0; /* which in the end is the ATOMIC compare_and_swap in ASSEMBLY CODE */ /* this would happen in __raw_cmpxchg(ptr, old, new, size, lock) */ if (likely(atomic_try_cmpxchg_acquire(&lock->val, &val, _Q_LOCKED_VAL))) return; queued_spin_lock_slowpath(lock, val); }
-
spin_unlock()does the opposite three things:spin_release(&lock->dep_map, 1, _RET_IP_);do_raw_spin_unlock(lock);preempt_enable();
-
-
the declaration for defining your own spin lock is inside
include/linux/spinlock_types.h:#define DEFINE_SPINLOCK(x) spinlock_t x = __SPIN_LOCK_UNLOCKED(x)which if you dig deep into what it did:
- essentially sets a
raw_lock’scountervalue to0
- essentially sets a
-
the declaration for
spin_lock_irq()insideinclude/linux/spinlock.h:- consider the problem that: if a process hold a spin lock
Lis interrupted, and the interrupted handler needs that lockLas well- this causes a deadlock situation, because an interrupted process cannot proceed
- therefore,
spin_lock_irq()in addition disables interrupt
- consider the problem that: if a process hold a spin lock
-
the declaration for
spin_lock_irq_save()insideinclude/linux/spinlock.h:- this solves the problem that if, before calling
spin_lock_irq, the interrupt has already been disabled for other processes. Therefore, here you need to:- save the previous “disabled interrupt’s configuration”
- this solves the problem that if, before calling
Note
- One trick thing that you have to find out yourself is which lock in Kernel to use
- for example,
task_listhas its own lock.- To choose between
spin_lock()andspin_lock_irq(), simply think about:
- will this lock be used by Interrupt Handlers? If not, use
spin_lock()suffices.
For Example:
-
Spin lock used in
/arch/parisc/mm/init.cunsigned long alloc_sid(void) { unsigned long index; spin_lock(&sid_lock); /* some code omitted */ index = find_next_zero_bit(space_id, NR_SPACE_IDS, space_id_index); space_id[index >> SHIFT_PER_LONG] |= (1L << (index & (BITS_PER_LONG - 1))); space_id_index = index; spin_unlock(&sid_lock); return index << SPACEID_SHIFT; } -
Spin lock defined and used
defined inside
arch/alpha/kernel/time.cDEFINE_SPINLOCK(rtc_lock);then, some other code using the lock:
ssize_t atari_nvram_read(char *buf, size_t count, loff_t *ppos) { char *p = buf; loff_t i; spin_lock_irq(&rtc_lock); if (!__nvram_check_checksum()) { spin_unlock_irq(&rtc_lock); return -EIO; } for (i = *ppos; count > 0 && i < NVRAM_BYTES; --count, ++i, ++p) *p = __nvram_read_byte(i); spin_unlock_irq(&rtc_lock); *ppos = i; return p - buf; }
Blocking Locks
Instead of spin lock, we
- send other processes to sleep/blocked when one process is doing critical work.
- wake the waiting process up when the process has finished the work
This implementation in Linux is called mutex, or semaphore.
- mutex may be (often is) implemented using semaphore.
Blocking Semaphore
The blocking semaphore has:
- lock =
P(semaphore)=wait() - unlock =
V(semaphore)=signal()
Idea Behind a Semaphore
Rather than engaging in busy waiting, the process can block itself.
Overall flow of a semaphore:
- places a process into a waiting queue associated with the semaphore
- the state of process s switched to the waiting state.
- Then control is transferred to the CPU scheduler, which selects another process to execute.
- A process that is blocked, waiting on a semaphore S, should be restarted by a
wakeup()operation when some other process executes asignal()operation.- The process is restarted, which changes the process from the waiting state to the ready state. The process is then placed in the ready queue.
so the simple structure of a
semaphorelooks like:typedef struct { int value; struct task_struct *list; } semaphore;
Consider int s=1:
wait(s){
lock();
s--;
while(s < 0){
add current process to queue;
unlock();
block itself;
// next time it wakes up, check again atomically
lock();
}
unlock();
}
where:
- the
lock()andunlock()are just to make the code of the semaphore to be atomic, so they could just betest_and_set()
and then:
signal(s) {
lock();
S->value++;
if (S->value <= 0) {
remove a process P from S->list;
wakeup(P);
}
unlock();
}
Note
- the above implementation allows a negative value semaphore. If a semaphore value is negative, its magnitude is the number of processes waiting on that semaphore
- One way to add and remove processes from the list so as to ensure bounded waiting is to use a FIFO queue
In kernel, the actual implementation are in kernel/locking/semaphore.c
In general:
- to grab a semaphore, use
void down(struct semaphore *sem) - to release a semaphore, use
void up(struct semaphore *sem)
In specific:
-
void down(struct semaphore *sem)looks like:void down(struct semaphore *sem) { unsigned long flags; /* using spin lock to make sure the following code is atomic */ raw_spin_lock_irqsave(&sem->lock, flags); if (likely(sem->count > 0)) sem->count--; else __down(sem); raw_spin_unlock_irqrestore(&sem->lock, flags); }where:
-
if the original
count=1, then this means only one process can obtain the semaphore. This is also called a binary semaphorecountdefines the number of processes allowed to obtain the semaphore simultaneously
-
otherwise, the
__down(sem)basically blocks/sleeps the process and does:static inline int __sched __down_common(struct semaphore *sem, long state, long timeout) { struct semaphore_waiter waiter; /* adds the task to a LIST OF TASK WAITING */ list_add_tail(&waiter.list, &sem->wait_list); waiter.task = current; waiter.up = false; for (;;) { if (signal_pending_state(state, current)) goto interrupted; if (unlikely(timeout <= 0)) goto timed_out; /* sets the state of the task, E>G> TASK_UNINTERRUPTABLE */ __set_current_state(state); /* befores goes to sleep, releases the spin lock from down() */ raw_spin_unlock_irq(&sem->lock); /* sends the process to sleep, also adds a timeout to the sleep. * Then, schedules something else to run */ timeout = schedule_timeout(timeout); /* here, the process woke up */ raw_spin_lock_irq(&sem->lock); /* if you woke up not by the __up() function, then waiter.up = false */ /* then, you will need to loop again and go back to sleep */ if (waiter.up) return 0; } /* some code omitted */ }
-
-
on the other hand,
void up(struct semaphore *sem)does:void up(struct semaphore *sem) { unsigned long flags; raw_spin_lock_irqsave(&sem->lock, flags); /* if wait_list is empty, increase the semaphore */ /* otherwise, wakes up the first process in the wait_list */ if (likely(list_empty(&sem->wait_list))) sem->count++; else __up(sem); raw_spin_unlock_irqrestore(&sem->lock, flags); }where:
-
the
__up(sem)does:static noinline void __sched __up(struct semaphore *sem) { struct semaphore_waiter *waiter = list_first_entry(&sem->wait_list, struct semaphore_waiter, list); list_del(&waiter->list); /* sets the up flag for the __down_common() function */ waiter->up = true; /* wakes up the process */ wake_up_process(waiter->task); }
-
Disadvantage
Because semaphores are stateful (it is not purely
1or0), if you messed up by doing:up(s); /* messed up the state */ /* some code */ down(s); /* some other code */ up(s);then the entire state of semaphore is messed up (i.e. it is broken from that point onward)
However, if you use a
spinlockwhich only has0or1, then messing it up once will still get it to work afterwards.
Mutex Locks
Mutex = Mutual Exclusion
- Basically either the spin lock idea, or the blocking idea (often it refers to the blocking locks).
So that the simple idea is just:
acquire() {
while (!available)
; /* busy wait */
available = false;
}
then
release() {
available = true;
}
For Example
do {
acquire lock
critical section
release lock
remainder section
} while (true);
Priority Inversion
As an example, assume we have three processes— $L$, $M$, and $H$—whose priorities follow the order $L < M < H$. Assume that process $H$ requires resource $R$, which is currently being accessed by process $L$.
- Ordinarily, process $H$ would wait for $L$ to finish using resource $R$.
- However, now suppose that process $M$ becomes runnable, thereby preempting process $L$.
- Indirectly, a process with a lower priority—process $M$—has affected how long process $H$ must wait for $L$ to relinquish resource $R$.
Priority Inversion
- The above problem is solved by implementing a priority-inheritance protocol.
- According to this protocol, all processes that are accessing resources needed by a higher-priority process inherit the higher priority until they are finished with the resources in question. When they are finished, their priorities revert to their original values.
Classical Synchronization Problems
All below mutex locks refer to blocking semaphores.
Bounded Buffer
Basically, consider the case where you have a pool of n buffers, and you want only one process (producer/consumer) to access the pool at the time.
Using a simple semaphore:
-
lock setups:
int n; semaphore mutex = 1; semaphore empty = n; semaphore full = 0;
Producer code:
do {
. . .
/* produce an item in next produced */
. . .
wait(empty);
wait(mutex);
. . .
/* add next produced to the buffer */
. . .
signal(mutex);
signal(full);
} while (true);
Consumer code:
do {
wait(full);
wait(mutex);
. . .
/* remove an item from buffer to next consumed */
. . .
signal(mutex);
signal(empty);
. . .
/* consume the item in next consumed */
. . .
} while (true);
Notice that:
mutexlock ensures only one process into the poolemptysemaphore ensures processes only producing toemptynumber of buffersfullsemaphore ensures processes only consuming tofullnumber of buffers- all three locks combined gives the correct behavior
Reader-Writer Problem
Reader-Writer Problem
- First of all, when we have readers and writers for the same resource, we want to:
- readers to be concurrent
- writers to be mutually exclusive
- The first readers–writers problem, requires that no reader be kept waiting unless a writer has already obtained permission to use the shared object.
- notice that writers may starve here (waiting forever if readers come in a lot)
- The second readers–writers problem requires that, once a writer is ready, that writer perform its write as soon as possible
- notice that readers may starve here (waiting forever if writers come in a lot)
Therefore, in reality, there is often a mixed solution.
The first problem is solved by:
-
semaphore rw_mutex = 1; /* Used by writer (technically used by both) */ semaphore mutex = 1; /* Used by Readers */ int read count = 0;
Writer Process
do {
wait(rw_mutex); /* just simply lock */
. . .
/* writing is performed */
. . .
signal(rw_mutex); /* just simply unlock */
} while (true);
Reader Process
do {
wait(mutex);
read_count++;
if (read_count == 1)
wait(rw_mutex); /* first reader disables write */
signal(mutex);
. . .
/* reading is performed */
. . .
wait(mutex);
read_count--;
if (read_count == 0)
signal(rw_mutex); /* last reader enables write */
signal(mutex);
} while (true);
notice that:
- if a writer appears first, it obtains
rw_mutex, disallows all readers - if a reader appears first:
- the first reader locks the
rw_mutex, disallowing write - the last reader unlucks the
rw_mutex, allowing write
- the first reader locks the
My Idea for the Second Reader-Writer Problem:
variables:
semaphore rw_mutex = 1; /* Used by writer (technically used by both) */ semaphore read_lock = 1; /* Used to stop readers comming */ semaphore mutex = 1; /* Used by Readers */ semaphore r_mutex = 1; /* Used by Writers */ int read count = 0;Writer
do { wait(r_mutex); write_count++; if (write_count == 1) wait(read_lock); /* first writer disables more reader comming */ wait(rw_mutex); signal(r_mutex); . . . /* writing is performed */ . . . wait(r_mutex); if(write_count == 0) signal(read_lock); signal(rw_mutex); signal(r_mutex); } while (true);Reader:
do { wait(read_lock); /* used by writers to disable readers */ wait(mutex); read_count++; if (read_count == 1) wait(rw_mutex); /* first reader disables write */ signal(mutex); signal(read_lock); . . . /* reading is performed */ . . . wait(mutex); read_count--; if (read_count == 0) signal(rw_mutex); /* last reader enables write */ signal(mutex); } while (true);
RCU - Read Copy Update
This is an mechanism in kernel that allows concurrent readers without grabbing locks (saves performance issues)
- this only works if we can do atomic updates (for example, if you are using a linked-list)
RCU
- readers will not have a lock
- in code, there will be a fake lock, which is only used to indicate where the critical section is
- writers will have a spin lock (or any lock)
For Example: Linked-List RCU
Header file:
typedef struct ElementS{
int key;
int value;
struct ElementS *next;
} Element;
class RCUList {
private:
RCULock rcuLock;
Element *head;
public:
bool search(int key, int *value); /* read */
void insert(Element *item, value);
bool remove(int key);
};
implementation:
bool
RCUList::search(int key, int *valuep) {
bool result = FALSE;
Element *current;
rcuLock.readLock(); /* this is FAKE lock */
current = head;
for (current = head; current != NULL;
current = current->next) {
if (current->key == key) {
*valuep = current->value;
result = TRUE;
break;
}
}
rcuLock.readUnlock(); /* this is FAKE lock */
return result;
}
void
RCUList::insert(int key,
int value) {
Element *item;
// One write at a time.
rcuLock.writeLock(); /* this is an actual lock, we are modifying the list */
// Initialize item.
item = (Element*)
malloc(sizeof(Element));
item->key = key;
item->value = value;
item->next = head;
// Atomically update list.
rcuLock.publish(&head, item);
// Allow other writes
// to proceed.
rcuLock.writeUnlock(); /* this is an actual lock */
// Wait until no reader
// has old version.
rcuLock.synchronize();
}
bool
RCUList::remove(int key) {
bool found = FALSE;
Element *prev, *current;
// One write at a time.
rcuLock.WriteLock(); /* this is an actual lock, we are modifying the list */
for (prev = NULL, current = head;
current != NULL; prev = current,
current = current->next) {
if (current->key == key) {
found = TRUE;
// Publish update to readers
if (prev == NULL) {
rcuLock.publish(&head,
current->next);
} else {
rcuLock.publish(&(prev->next),
current->next);
}
break;
}
}
// Allow other writes to proceed.
rcuLock.writeUnlock();
// Wait until no reader has old version.
if (found) {
/* before synchronization, there MAY be an OLD reader looking at the old-TO-BE-REMOVED data, which is current */
rcuLock.synchronize();
/* afterwards, you are SURE no reader will be looking at the old entry. Now you can free */
free(current);
}
return found;
}
where:
- all the actual waiting happens at
synchronize()
the locks implementation:
class RCULock{
private:
// Global state
Spinlock globalSpin;
long globalCounter;
// One per processor
DEFINE_PER_PROCESSOR(
static long, quiescentCount);
// Per-lock state
Spinlock writerSpin;
// Public API omitted
}
void RCULock::ReadLock() {
disableInterrupts(); /* I can't be preempted, but other running processes can run */
}
void RCULock::ReadUnlock() {
enableInterrupts();
}
void RCULock::writeLock() {
writerSpin.acquire(); /* an actual spin lock */
}
void RCULock::writeUnlock() {
writerSpin.release(); /* an actual spin lock */
}
void RCULock::publish (void **pp1,
void *p2){
memory_barrier(); /* make sure memory layout does not change */
*pp1 = p2;
memory_barrier();
}
// Called by scheduler
void RCULock::QuiescentState(){
memory_barrier();
PER_PROC_VAR(quiescentCount) =
globalCounter; /* sets the quiescentCount=globalCounter */
memory_barrier();
}
void
RCULock::synchronize() {
int p, c;
globalSpin.acquire();
c = ++globalCounter;
globalSpin.release();
/* WAIT for EVERY single CPU to schedule something else */
FOREACH_PROCESSOR(p) {
/* true if the scheduler scheduled a NEW process AND called QuiescentState() */
while((PER_PROC_VAR(
quiescentCount, p) - c) < 0) {
// release CPU for 10ms
sleep(10);
}
}
}
so we see that synchronize basically does the waiting such that all data across CPUs would be “correct”.
Kernel Code Examples
Note that
if you want to use a RCU lock for a resource, then obviously you need all of the related operations:
- read
- write/update
to also use RCU
publish/synchronizationmechanism
static int
do_sched_setscheduler(pid_t pid, int policy, struct sched_param __user *param)
{
struct sched_param lparam;
struct task_struct *p;
int retval;
/* some code omitted */
rcu_read_lock(); /* rcu read_lock, not a real lock */
retval = -ESRCH;
p = find_process_by_pid(pid);
if (likely(p))
get_task_struct(p);
rcu_read_unlock();
if (likely(p)) {
retval = sched_setscheduler(p, policy, &lparam);
put_task_struct(p);
}
return retval;
}
Wait Queues
Basically, with this you can:
-
defines a wait queue
- add sleeping
taskto a wait queue - wake up sleeping
tasks from a wait queue (putting back toRUN QUEUE) - …
- more refer to
include/linux/wait.h.
Reminder
- When the task marks itself as sleeping, you wan to:
- puts itself on a wait queue
- removes itself from the red-black tree of runnable (
RUN QUEUE)- calls
schedule()to select a new process to execute.- Waking back up is the inverse:
- The task is set as runnable
- Removed from the wait queue
- Added back to the red-black tree of
RUN QUEUENote that waking up does not call
schedule()
In specific:
-
creating a wait queue:
DECLARE_WAITQUEUE(name, tsk); /* statically creating a waitqueue*/ DECLARE_WAIT_QUEUE_HEAD(wait_queue_name); /* statically creating a waitqueue*/ init_waitqueue_head(wq_head); /* dynamically creating one */where:
-
/* DECLARE_WAITQUEUE(name, tsk) does this */ struct wait_queue_entry name = __WAITQUEUE_INITIALIZER(name, tsk)
-
-
creating a wait_entry statically so that you can
#define DEFINE_WAIT(name) DEFINE_WAIT_FUNC(name, autoremove_wake_function)where:
-
this thing automatically assigns
currentin the private fieldstruct wait_queue_entry name = { .private = current, .func = function, .entry = LIST_HEAD_INIT((name).entry), }
-
-
adding things to a wait queue
extern void add_wait_queue(struct wait_queue_head *wq_head, struct wait_queue_entry *wq_entry); /* or lower level */ static inline void __add_wait_queue(struct wait_queue_head *wq_head, struct wait_queue_entry *wq_entry) { list_add(&wq_entry->entry, &wq_head->head); }notice that all it does is a list_add. This means you might be able to customize itself.
-
adding things to a wait queue to tail
static inline void __add_wait_queue_entry_tail(struct wait_queue_head *wq_head, struct wait_queue_entry *wq_entry) { list_add_tail(&wq_entry->entry, &wq_head->head); } -
actually sending a process to sleep
prepare_to_wait(&pstrace_wait, &wait, TASK_INTERRUPTIBLE); schedule(); -
waking up all things from a wait queue by putting it back to
RUN_QUEUE#define wake_up(x) __wake_up(x, TASK_NORMAL, 1, NULL) -
remove task from
wait_queueafter you are sure that this thing should be running:/** * finish_wait - clean up after waiting in a queue * @wq_head: waitqueue waited on * @wq_entry: wait descriptor * * Sets current thread back to running state and removes * the wait descriptor from the given waitqueue if still * queued. */ void finish_wait(struct wait_queue_head *wq_head, struct wait_queue_entry *wq_entry)
Note
other useful
wake_uporsleeprelated functions can be found inkernel/sched/core.c
wake up a task:
int wake_up_process(struct task_struct *p) { return try_to_wake_up(p, TASK_NORMAL, 0); }
For Example:
DEFINE_WAIT(wait);
struct cx25840_state *state = to_state(i2c_get_clientdata(client));
init_waitqueue_head(&state->fw_wait);
q = create_singlethread_workqueue("cx25840_fw");
if (q) {
/* only changes state */
prepare_to_wait(&state->fw_wait, &wait, TASK_UNINTERRUPTIBLE);
/* kernel run something else, then the task is actually blocked */
schedule();
/* after the task GETS RUNNING AGAIN, this is resumed/called */
finish_wait(&state->fw_wait, &wait);
}
then to have something that wakes the task up, use
static void cx25840_work_handler(struct work_struct *work)
{
struct cx25840_state *state = container_of(work, struct cx25840_state, fw_work);
cx25840_loadfw(state->c);
/* wakes up the task */
wake_up(&state->fw_wait);
}
Note
waking_upthe task does not automatically puts it to running. It only puts it back to theRUN QUEUE. Then, only when some processes calledschedule(), the process might run (exactly which process to run depends on the scheduling algorithm).
For Example:
static ssize_t inotify_read(struct file *file, char __user *buf,
size_t count, loff_t *pos)
{
struct fsnotify_group *group;
DEFINE_WAIT_FUNC(wait, woken_wake_function);
/* initialization is done somewhere else */
add_wait_queue(&group->notification_waitq, &wait);
while (1) {
spin_lock(&group->notification_lock);
kevent = get_one_event(group, count);
spin_unlock(&group->notification_lock);
/* some code omitted */
/* actually schedules a new process */
wait_woken(&wait, TASK_INTERRUPTIBLE, MAX_SCHEDULE_TIMEOUT);
}
/* when woken up, removes from the queue */
remove_wait_queue(&group->notification_waitq, &wait);
return ret;
}
again, this task will be woken up by other functions calling wake_up().
Kernel Schedule Function
This is what happens when the kernel calls schedule (i.e. sleeps a task by switching to let another task run).
Reminder
- When the task marks itself as sleeping, you wan to:
- puts itself on a wait queue
- removes itself from the red-black tree of runnable (
RUN QUEUE)- calls
schedule()to select a new process to execute.- Waking back up is the inverse:
- The task is set as runnable
- Removed from the wait queue
- Added back to the red-black tree of
RUN QUEUENote that waking up does not call
schedule()
Now, the code:
static void __sched notrace __schedule(bool preempt)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
struct rq_flags rf;
struct rq *rq;
int cpu;
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr; /* previous running job = current task of run queue */
/* some code omitted here */
/* picks the next task from the RUN QUEUE */
next = pick_next_task(rq, prev, &rf);
clear_tsk_need_resched(prev);
clear_preempt_need_resched();
if (likely(prev != next)) {
/* if there is only one job, then prev = next since running job
* by default is still on the queue
*/
/* this is when the prev=current job stops running, and the next one starts*/
/* Also unlocks the rq: */
rq = context_switch(rq, prev, next, &rf);
} else {
rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP);
rq_unlock_irq(rq, &rf);
}
balance_callback(rq);
}
Note:
- for Linux kernel, making a task
RUNNINGdoes not remove it from theRUN QUEUE. Therefore, when you pick the next task to run, check that there are more than one task in the queue.- this is done with
likely(prev != next)
- this is done with
- when a task is
context_switched, it is not placed back on theRUN QUEUEautomatically.- It is placed back on the
RUN QUEUEonly when you callwake_up(). - It is then run only when the OS calls
schedule(), and it is its turn (essentially it is the OS’s choice choosing and putting the next process to run)
- It is placed back on the
Monitor
Reminder:
Because semaphores are stateful (it is not purely
1or0), if you messed up by doing:up(s); /* messed up the state */ /* some code */ down(s); /* some other code */ up(s);then the entire state of semaphore is messed up (i.e. it is broken from that point onward).
To deal with such errors, researchers have developed high-level language constructs - the monitor type.
- essentially, the monitor construct ensures that only one process at a time is active within the monitor.
Monitor
monitoris an Abstract Data Type. The aim is that anything done in the monitor is guaranteed to be mutually exclusive.
- therefore, technically it does not exist in kernel, it is just an idea/abstract
Abstract Structure of Monitor
monitor monitor name { /* shared variable declarations */ int a; ... condition x; ... /* operators */ function P1 ( . . . ) { . . . } function P2 ( . . . ) { . . . } . . . function Pn ( . . . ) { . . . } initialization code ( . . . ) { . . . } }where:
- The only operations that can be invoked on a condition variable are
wait()andsignal(), and that the condition variable will have its own wait queueSchematic Idea:
Signal and Wait in Monitor
- Suppose there is some condition
x:
x.wait();means that the process invoking this operation is suspended until another process invokesx.signal();resumes exactly one suspended process. If no process is suspended, then the signal() operation has no effect.- Now, suppose that
x.signal()operation is invoked by a process $P$, there exists a suspended process $Q$ associated with conditionx. Now, both are allowable to run. Then you will have two strategies:
- Signal and wait. $P$ either waits until $Q$ leaves the monitor or waits for another condition.
- this is sometimes adopted since the logical condition for which $Q$ was waiting may no longer hold after $P$ continues and finishes its work.
- Signal and continue. $Q$ either waits until $P$ leaves the monitor or waits for another condition.
For Example
Consider the following monitor:
Monitor bank{
int balance;
condition A; /* associated with A.wait() and A.signal() and its wait queue */
public credit(x){
/* some mutual exclusion code */
balance -= x;
}
public debit(x){
/* some mutual exclusion code */
balance += x;
}
}
so that when doing
creditordebit, those mutual exclusion on processes are guaranteed
then, a simple example using the condition variable:
/* acquire and do work */
lock(mutex);
/* condition_A is checked AGAIN when woken up! */
while(!condition_A)
A.wait();
unlock(mutex)
where, since processes cannot hold locks when asleep, we need to do the following inside A.wait():
-
A.wait(){ set_process_state_to_blocked(); add_process_to_wait_queue(A); // release the lock before going to sleep unlock(mutex); schedule(); // when back, obtain the lock back lock(mutex); }
then, for the other part:
/* release and have done the work */
lock(mutex);
A.signal();
unlock(mutex);
Note
- the above part of using the condition variable is completely general and does not restrict to using it within a
monitor. This means that you can use the condition variable idea above independently in your work.
Deadlocks
Deadlock
- When every process in the set is waiting for an event that can be caused only by another waiting process in the set, we say that a set of processes is in a deadlocked state
For Example
- process $P_1$ grabbed
lock1and attempts to grablock2 - process $P_2$ grabbed
lock2and attempts to grablock1
Conditions for Deadlock
A deadlock situation can arise if the following four conditions hold simultaneously in a system:
- there is some form of mutual exclusion (e.g. locks for a resource)
- there is some form of hold and wait (e.g. holding
lock1and waiting forlock2)
- basically, you are grabbing multiple locks.
- a circular wait (e.g. process $P_1$ waits for $P_2$, and $P_2$ waits for $P_1$)
- in a sense, this implies rule 1 and 2 as well
- no preemption (e.g. timeouts for locks)
If these conditions hold, you can have a deadlock.
Therefore, some rules to avoid deadlocks are:
- try to avoid multiple locks
- if we are grabbing multiple locks, try to grab locks in the same consistent order
Dining Philosophers Problem
Basically we have the setup that:
- there are five philosophers, doing eating and thinking
- but there is one chop stick for each
and:
- dead lock occurs if each person grabs its own chopstick, and is circular waiting others to put it down
System Model
In general, the system is basically doing this to resources:
- Request. The process requests the resource. If the request cannot be granted immediately (for example, if the resource is being used by another process), then the requesting process must wait until it can acquire the resource.
- Use. The process can operate on the resource (for example, if the resource is a printer, the process can print on the printer).
- Release. The process releases the resource.
Examples of such resources include:
- resources may be either physical resources (for example, printers, tape drives, memory space, and CPU cycles)
- logical resources (for example, files, semaphores, and monitors)
In the end, a system table records:
- whether each resource is free or allocated
- for each resource that is allocated, the table also records the process to which it is allocated.
Therefore:
Two Broad Types of Deadlocks
- Deadlocks with same resource type
- process $P_1$ grabbed
resource1_1and attempts to grabresource1_2- process $P_2$ grabbed
resource1_2and attempts to grabresource1_1- Deadlocks with different resource types
- process $P_1$ grabbed
resource1and attempts to grabresource2- process $P_2$ grabbed
resource2and attempts to grabresource1
Resource Allocation Graph
Vertices
- ${P_1, P_2, …, P_n}$, the set consisting of all the active processes in the system
- ${R_1, R_2, …, R_m}$, the set consisting of all resource types
- Since resource type $R_j$ may have more than one instance (e,g, resource type
printermay have 3 actual printers), we represent each such instance as a dotDirected Edges
- A directed edge $P_i → R_j$ is called a request edge ($P_i$ requested resource $R_j$)
A directed edge $R_j → P_i$ is called an assignment edge ($R_j$ is assigned to process $P_i$)
- When this request can be fulfilled, the request edge is instantaneously transformed to an assignment edge
For Example
which is fine
For Example: Dead Lock
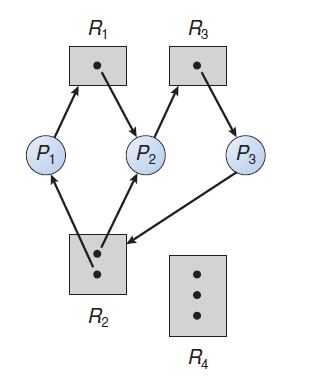
which has a deadlock.
This means
- If the graph contains no cycles, then no process in the system is deadlocked.
- If the graph does contain a cycle, then a deadlock may exist.
- If each resource type has several instances, then a cycle does not necessarily imply that a deadlock has occurred
For Example: Cycle without Deadlock
Handling Deadlocks
For OS
In the OS point of view, we can:
- We can use a protocol to prevent or avoid deadlocks, ensuring that the system will never enter a deadlocked state.
- We can allow the system to enter a deadlocked state, detect it, and recover.
- We can ignore the problem altogether and pretend that deadlocks never occur in the system.
- this is employed by UNIX and Windows
-
Preventing or avoiding deadlocks
-
Deadlock prevention
provides a set of methods for ensuring that at least one of the four necessary conditions for deadlocks cannot hold.
-
Deadlock avoidance
requires that the operating system be given in advance additional information concerning which resources a process will request and use during its lifetime.
-
Midterm Solution
Task
- Use a Ring Buffer to trace all the system calls executed by the OS
Solution
-
To trace it correctly, add it inside
arch/x86/entry/common.c#include <linux/sctrace.h> #ifdef CONFIG_X86_64 __visible void do_syscall_64(unsigned long nr, struct pt_regs *regs) { struct thread_info *ti; enter_from_user_mode(); local_irq_enable(); ti = current_thread_info(); if (READ_ONCE(ti->flags) & _TIF_WORK_SYSCALL_ENTRY) nr = syscall_trace_enter(regs); if (likely(nr < NR_syscalls)) { nr = array_index_nospec(nr, NR_syscalls); regs->ax = sys_call_table[nr](regs); // added here // current information is accessible without passing it in sctrace_add(nr, regs->ax); #ifdef CONFIG_X86_X32_ABI } else if (likely((nr & __X32_SYSCALL_BIT) && (nr & ~__X32_SYSCALL_BIT) < X32_NR_syscalls)) { nr = array_index_nospec(nr & ~__X32_SYSCALL_BIT, X32_NR_syscalls); regs->ax = x32_sys_call_table[nr](regs); // optionally added here sctrace_add(nr, regs->ax); #endif } syscall_return_slowpath(regs); } -
The process of adding the my own
syscallsare omitted, as they are trivial -
Now, the actual program
First, the header file looks like:
#ifndef _INCLUDE_PSTRACE_H #define _INCLUDE_PSTRACE_H #include <linux/atomic.h> struct sctrace { long syscall; long result; pid_t tid; char comm[16]; }; #define SCTRACE_BUF_SIZE 500 /* this is the circular buffer */ struct sctrace_buf { struct sctrace entry[SCTRACE_BUF_SIZE]; bool sctrace_enable; int head, tail; spinlock_t sctrace_lock; bool empty; }; void sctrace_add(long syscall, long result); #endifFirst,
sctrace_addlooks like:#include <linux/atomic.h> #include <linux/sched.h> #include <linux/slab.h> #include <linux/types.h> #include <linux/uaccess.h> #include <linux/syscalls.h> #include <linux/sctrace.h> // a circular buffer /* struct sctrace entry[SCTRACE_BUF_SIZE]; is already initialized in header file*/ struct sctrace_buf sct = { .head = 0, .tail = SCTRACE_BUF_SIZE - 1, .sctrace_lock = __SPIN_LOCK_UNLOCKED(sctrace_lock), .sctrace_enable = false, .empty = true, }; void sctrace_add(long syscall, long result) { int head, tail; struct task_struct *p = current; spin_lock(&sct.sctrace_lock); if (!sct.sctrace_enable) { spin_unlock(&sct.sctrace_lock); return; } head = sct.head; tail = sct.tail; /* wraps around in the CIRCULAR BUFF */ if (tail == SCTRACE_BUF_SIZE - 1) tail = 0; else tail++; sct.tail = tail; /* upon first iteration, @head stays at 0 * when it is full, it wraps arounf and then @head will be @tail+1 */ if (likely(head == tail && !sct.empty)) { head++; sct.head = head == SCTRACE_BUF_SIZE ? 0 : head; } /* always add the data to the tail element */ sct.entry[tail].syscall = syscall; sct.entry[tail].result = result; get_task_comm(sct.entry[tail].comm, p); sct.entry[tail].tid = task_pid_vnr(p); sct.empty = false; spin_unlock(&sct.sctrace_lock); } SYSCALL_DEFINE0(sctrace_start) { int ret; //spin_lock(&sct.sctrace_lock); /* lock not needed since we are READING */ if (sct.sctrace_enable) ret = -EINVAL; else { /* ASSIGNMENT is also atomic */ sct.sctrace_enable = true; ret = 0; } //spin_unlock(&sct.sctrace_lock); return ret; } SYSCALL_DEFINE0(sctrace_stop) { int ret; //spin_lock(&sct.sctrace_lock); if (!sct.sctrace_enable) ret = -EINVAL; else { sct.sctrace_enable = false; ret = 0; } //spin_unlock(&sct.sctrace_lock); return ret; } SYSCALL_DEFINE1(sctrace_dump, struct sctrace __user *, buf) { int ret = 0; struct sctrace *kbuf; int head, tail; bool empty; kbuf = kmalloc(sizeof(struct sctrace) * SCTRACE_BUF_SIZE * 2, GFP_KERNEL); if (!kbuf) return -ENOMEM; /* lock and COPY DATA BACK */ spin_lock(&sct.sctrace_lock); /* copy data from YOUR STACK RB to the MALLOCED data */ /* alternatively, you can just have a loop to copy data back */ memcpy(kbuf, sct.entry, sizeof(struct sctrace) * SCTRACE_BUF_SIZE); memcpy(kbuf + SCTRACE_BUF_SIZE, sct.entry, sizeof(struct sctrace) * SCTRACE_BUF_SIZE); head = sct.head; tail = sct.tail; empty = sct.empty; spin_unlock(&sct.sctrace_lock); /* calculates how many entries copied here, and copies the data back to user */ if (empty) { ret = 0; goto out; } else if (tail + 1 == head) ret = SCTRACE_BUF_SIZE; else ret = tail - head + 1; if (copy_to_user(buf, kbuf + head, sizeof(struct sctrace) * ret)) { ret = -EFAULT; goto out; } out: kfree(kbuf); return ret; } -
Last but not least, the
test.cfile:#include <errno.h> #include <limits.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <unistd.h> #include <wait.h> #include <time.h> #define BUF_SIZE 500 #define __NR_SYSCALL_SCTRACE_START 436 #define __NR_SYSCALL_SCTRACE_STOP 437 #define __NR_SYSCALL_SCTRACE_DUMP 438 struct sctrace { long syscall; long result; pid_t tid; char comm[16]; }; void populate_buffer() { /* will eventually calls a bunch of syscalls */ printf("hello, world\n"); } int main(void) { struct sctrace *buf; int i; int ret; pid_t pid; buf = malloc(sizeof(struct sctrace) * BUF_SIZE); if (!buf) { fprintf(stderr, "error: %s\n", strerror(errno)); return -1; } /* starts tracing */ syscall(__NR_SYSCALL_SCTRACE_START); pid = fork(); if (pid == 0) { /* child populates data */ populate_buffer(); exit(0); } else if (pid < 0) { fprintf(stderr, "error: %s\n", strerror(errno)); free(buf); return -1; } /* parent calls the syscall and gets stuff */ ret = syscall(__NR_SYSCALL_SCTRACE_DUMP, buf); if (ret < 0) { fprintf(stderr, "error: %s\n", strerror(errno)); free(buf); return -1; } for (i = 0; i < BUF_SIZE; i++) { if (buf[i].result >= 0) printf("SYSCALL: %s,%d,%ld\n", buf[i].comm, buf[i].tid, buf[i].syscall); } syscall(__NR_SYSCALL_SCTRACE_STOP); free(buf); return 0; }
Take Away Messages
The Ring Buffer structure using
tailandheadinteger position
The tail pointer and the size increment by one upon insertion of an element.
struct sctrace_buf sct = { .head = 0, .tail = SCTRACE_BUF_SIZE - 1, .sctrace_lock = __SPIN_LOCK_UNLOCKED(sctrace_lock), .sctrace_enable = false, .empty = true, }; void sctrace_add(long syscall, long result) { int head, tail; head = sct.head; tail = sct.tail; /* wraps around in the CIRCULAR BUFF */ if (tail == SCTRACE_BUF_SIZE - 1) tail = 0; else tail++; sct.tail = tail; /* upon first iteration, @head stays at 0 * when it is full, it wraps arounf and then @head will be @tail+1 */ if (likely(head == tail && !sct.empty)) { head++; sct.head = head == SCTRACE_BUF_SIZE ? 0 : head; } /* always add the data to the tail element */ sct.entry[tail].syscall = syscall; sct.entry[tail].result = result; get_task_comm(sct.entry[tail].comm, p); sct.entry[tail].tid = task_pid_vnr(p); sct.empty = false; spin_unlock(&sct.sctrace_lock); }therefore, to figure out the actual size:
if (empty) { ret = 0; goto out; } else if (tail + 1 == head) /* always be the case for full buffer */ ret = SCTRACE_BUF_SIZE; else /* not full buffer, @tail advances when new data added but @head does not move */ ret = tail - head + 1;
Week 6 - Process Scheduling
Process Scheduling
In general, the Linux scheduler (on recent Linux kernels, e.g. 3.0 at least) is scheduling schedulable tasks or simply tasks task_struct.
A task may be :
- a single-threaded process (e.g. created by
forkwithout any thread library) - any thread inside a multi-threaded process (including its main thread), in particular
Posixthreads (pthreads) - kernel tasks, which are started internally in the kernel and stay in kernel land (e.g.
kworker,nfsiod,kjournald,kauditd,kswapdetc etc…)
In other words, threads inside multi-threaded processes are scheduled like non-threaded - i.e. single threaded - processes.
CPU Scheduler
Scheduling
- Short-term scheduler, or CPU scheduler, does the job of:
- maintains a queue of tasks
- Note that the ready queue is not necessarily a first-in, first-out (FIFO) queue. It depends on the algorithm we want to use.
- select a task to run
- in the end, runs it by doing a context switch
- decide how long it will run
- scheduling is called in the following 4 context:
- some running process involuntarily gives up the CPU (e.g. it gets blocked)
- switches from
running->waitingor fromrunning->ready- some running process voluntarily gives up CPU (e.g. it is done)
- switches from
running->terminate- some special “task” becomes runnable
- some special task switches from
waiting->ready- scheduling parameters of the task change (e.g. priority of some task changed)
- You can call a schedule:
- directly
- indirectly by some
NEED_RESCHEDflag (e.g. when a process exits, it checks the flag)
Note
Long-term scheduling involves selecting the processes from the storage pool in the secondary memory and loading them into the ready queue in the main memory for execution.
The long-term scheduler controls the degree of multiprogramming. It must select a careful mixture of I/O bound and CPU bound processes to yield optimum system throughput. If it selects too many CPU bound processes then the I/O devices are idle and if it selects too many I/O bound processes then the processor has nothing to do.
CPU-I/O Burst Cycle
Definition
- process execution consists of a cycle of CPU execution and I/O wait, so that every process alternate between these two states.
- this means that: process execution begins with a burst, then goes to I/O burst, then goes to CPU burst, etc.
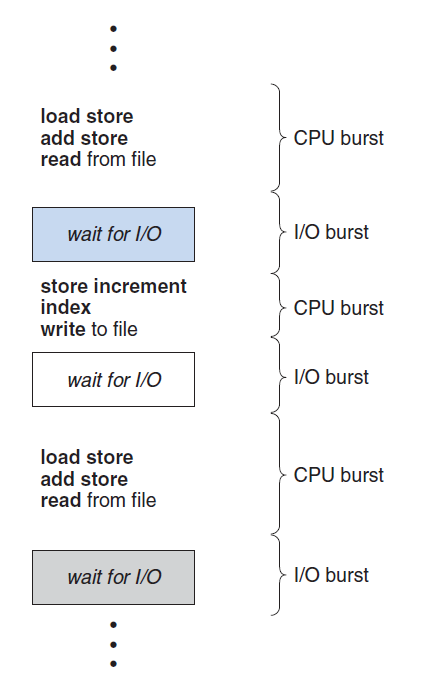
Typically:
- An I/O-bound program typically has many short CPU bursts.
- A CPU-bound program might have a few long CPU bursts.
Preemptive Scheduling
Reminder
Below was the four conditions when CPU scheduling needs to decide what goes next:
- When a process switches from the running state to the waiting state
- When a process switches from the running state to the ready state (for example, when an interrupt occurs)
- When a process switches from the waiting state to the ready state (for example, at completion of I/O)
- When a process terminates
- When scheduling takes place only under circumstances 1 and 4, we say that the scheduling scheme is non-preemptive or cooperative.
- Otherwise, it is preemptive.
Note
- Preemptive scheduling can result in race conditions when data are shared among several processes
- Therefore, sections of code are not accessed concurrently by several processes, they disable interrupts at entry and reenable interrupts at exit
Dispatcher
Dispatcher
- The dispatcher is the module that gives control of the CPU to the process selected by the short-term scheduler.
- This does the following:
- Switching context
- Switching to user mode
- recall that this is also where it checks if there are signals
- Jumping to the proper location in the user program to restart that program
Dispatcher Latency
- The time it takes for the dispatcher to stop one process and start another running is known as the dispatch latency.
Scheduling Criteria
Many criteria have been suggested for comparing CPU-scheduling algorithms
Scheduling Criteria
CPU utilization.
We want to keep the CPU as busy as possible. In a real system, it should range from 40 percent (for a lightly loaded system) to 90 percent (for a heavily loaded system).
Throughput.
If the CPU is busy executing processes, then work is being done. One measure of work is the number of processes that are completed per time unit, called throughput
Turnaround time.
From the point of view of a particular process, the important criterion is how long it takes to execute that process. The interval from the time of submission of a process to the time of completion is the turnaround time.
Waiting time.
The CPU-scheduling algorithm does not affect the amount of time during which a process executes or does I/O. It affects only the amount of time that a process spends waiting in the ready queue
- Shorted-Job/Burst-First minimizes this
Response time.
In an interactive system, often, a process can produce some output fairly early and can continue computing new results. Thus, another measure is the time from the submission of a request until the first response is produced. This measure, called response time, is the time it takes to start responding, not the time it takes to output the response.
Therefore, It is desirable to maximize CPU utilization and throughput and to minimize turnaround time, waiting time, and response time.
- In most cases, we optimize the average measure.
- However, under some circumstances, we prefer to optimize the minimum or maximum values rather than the average.
- For example, to guarantee that all users get good service,we may want to minimize the maximum response time.
Scheduling Algorithms
CPU scheduling deals with the problem of deciding which of the processes in the ready queue is to be allocated the CPU.
The measure of comparison in this section is the average waiting time.
First-Come, First Served Scheduling
The implementation of the FCFS policy is easily managed with a FIFO queue..
Disadvantage
On the negative side, the average waiting time under the FCFS policy is often quite long.
- i.e. the average waiting time under an FCFS policy is generally not minimal and may vary substantially if the processes’ CPU burst times vary greatly.
There is a convoy effect as all the other processes wait for the one big process to get off the CPU.
e.g. all the I/O processes end up waiting in the ready queue until the CPU-bound process is done. Then, when all the I/O-bound processes run, which have short CPU bursts, they execute quickly and move back to the I/O queues. At this point, the CPU sits idle.
This effect results in lower CPU and device utilization than might be possible if the shorter processes were allowed to go first.
For Example
Consider the following set of processes that arrive at time 0, with the length of the CPU burst given in milliseconds:
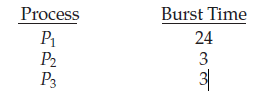
If the processes arrive in the order P1, P2, P3, and are served in FCFS order, we get the result shown in the following Gantt chart (which is a bar chart that illustrates a particular schedule)

where:
- the average waiting time is $(0+24 + 27)/3 = 17$ milliseconds
If the processes arrive in the order P2, P3, P1, however, the results will be as shown in the following Gantt chart

where:
- The average waiting time is now $(6 + 0 + 3)/3 = 3$ milliseconds. This reduction is substantial.
Shortest-Job-First Scheduling
This algorithm associates with each process the length of the process’s next CPU burst.
Shortest-Job-First Scheduling
- When the CPU is available, it is assigned to the process that has the smallest next CPU burst.
- The real difficulty with the algorithm is knowing the length of the next CPU request.
- This is often guessed using the exponential average of the measured lengths of previous CPU bursts
- The SJF algorithm can be either preemptive or non-preemptive.
- The choice arises when a new process arrives at the ready queue while a previous process is still executing. The next CPU burst of the newly arrived process may be shorter than what is left of the currently executing process. A preemptive SJF algorithm will preempt the currently executing process
Exponential Average Method
Let $t_n$ be the length of the $n$-th CPU burst, and let $\tau_{n+1}$ be our predicted value for the next CPU burst. Then, for $\alpha$, $0 \le \alpha \le 1$, define:
\[\tau_{n+1} = \alpha t_n + (1-\alpha)\tau_{n}\]Notice that this means:
- $t_n$ contains our most recent information
- $\tau_n$ stores the past history.
because:
\[\tau_{n+1}=\alpha t_n + \left[(1-\alpha)\alpha t_{n-1}+(1-\alpha)^2\alpha t_{n-2}+...+(1-\alpha)^{n+1}\alpha t_{0}+(1-\alpha)^{n+1} \tau_{0}\right]\]and the initial $\tau_0$ can be defined as a constant or as an overall system average
For Example: Exponential Average
Taking $\alpha=1/2$ and $\tau_0 = 10$
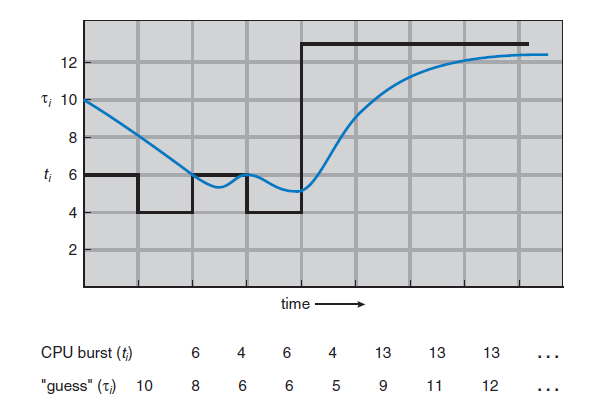
For Example: Preemptive SJF:
Consider the following four processes with next burst time:
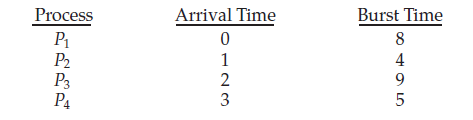
Then, the preemptive SJF will do:

where:
- for example, process $P_2$ arrives at time 1. The remaining time for process $P_1$ (7 milliseconds) is larger than the time required by process $P_2$ (4 milliseconds), so process $P_1$ is preempted, and process $P_2$ is scheduled
- The average waiting time for this example is $[(10 − 1) + (1 − 1) + (17 − 2) + (5 − 3)]/4 = 26/4 = 6.5$milliseconds. Non-preemptive SJF scheduling would result in an average waiting time of $7.75$ milliseconds.
Disadvantages
Obviously one thing is that the prediction might not always be accurate
Some sort of starving might happen
Interactive Processes, such as Web Browsers that will be running for a long time but we would like it to be high responsiveness.
- a solution to this would be to using a multi-level feedback idea, so that if you were blocked (e.g. waiting for I/O), you will get popped up
- but then this does not solve the
Zoomapplication problem. (always running, but also high priority)Therefore, today, many schedulers have removed SJF as a scheduling policy.
Priority Scheduling
Priority Scheduling
- A priority is associated with each process, and the CPU is allocated to the process with the highest priority.
- The SJF algorithm is a special case of the general priority-scheduling algorithm, where priority (p) is the inverse of the (predicted) next CPU burst.
- Priority scheduling can be either preemptive or non-preemptive. When a new process arrives at the ready queue:
- A preemptive priority scheduling algorithm will preempt the CPU if the priority of the newly arrived process is higher than the priority of the currently running process
- A non-preemptive priority scheduling algorithm will simply put the new process at the head of the ready queue.
Priority of a Process
- Priorities can be defined either internally or externally.
- Internally defined priorities use some measurable quantity or quantities to compute the priority of a process. For example, time limits, memory requirements, etc.
- External priorities are set by criteria outside the operating system, such as the importance of the process, the type and amount of funds being paid for computer use, etc.
- Some systems use low numbers to represent low priority; others use low numbers for high priority
- In this text, we assume that low numbers represent high priority
For Example
Consider the following setup, assumed to have arrived at time 0 in the order $P_1, P_2,…, P_5$.

then the Gantt Chart gives:

and the average waiting time is 8.2 milliseconds
Disadvantages
- A major problem with priority scheduling algorithms is indefinite blocking (here it refers to being in the ready queue but never becoming
running), or starvation, i.e. leave some low priority processes waiting indefinitely.
- A solution to this is the method of aging
Aging
- Aging involves gradually increasing the priority of processes that wait in the system for a long time.
- For example, if priorities range from 127 (low) to 0 (high), we could increase the priority of a waiting process by 1 every 15 minutes
Implementation-wise
One problem here is that we might need to search through the array to find the largest priority task. However, since there is a discrete number of priority, this is how it becomes implemented commonly:
where we see that:
- each priority essentially has an array, then it is just a FIFO/Round Robin for each priority level
- additionally, there could be a further optimization of storing an array of bitmap indicating which array has entries
This is the actual idea of
rtscheduling class in Linux
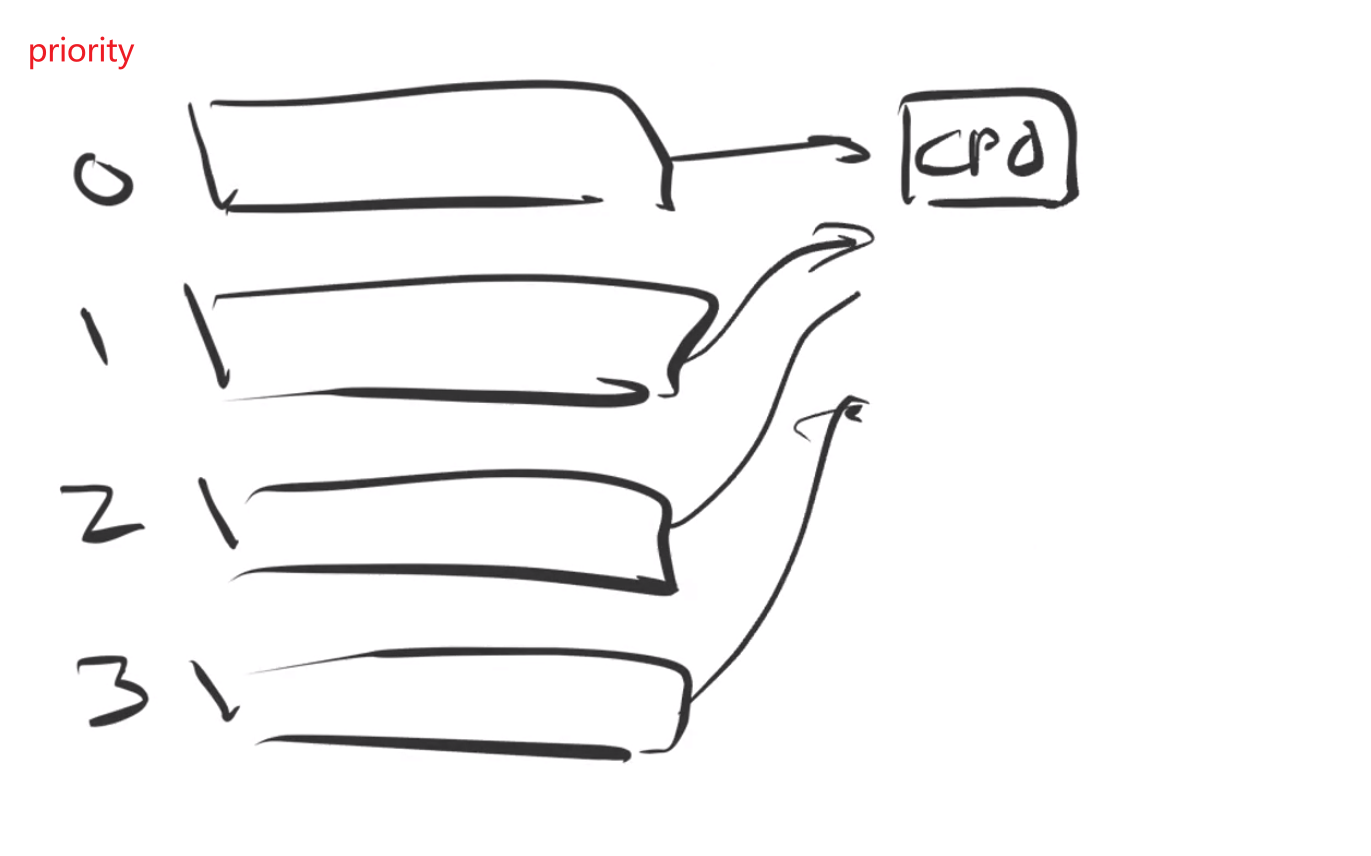
Round-Robin Scheduling
The round-robin (RR) scheduling algorithm is designed especially for timesharing systems.
Time Quantum
- A time quantum is generally from 10 to 100 milliseconds in length. This is generally defined based on how you want to implement it.
Round-Robin Scheduling
Basically, It is similar to FCFS scheduling, but preemption is added to enable the system to switch between processes.
- New processes are added to the tail of the circular ready queue.
- The CPU scheduler picks the first process from the ready queue, sets a timer to interrupt after 1 time quantum, and dispatches the process.
In the RR scheduling algorithm, no process is allocated the CPU for more than 1 time quantum in a row (unless it is the only runnable process)
Notice that the circular ready queue makes it work such that if there is only one runnable process in total, it will “look like” this is happening:

For Example
Consider the following set of processes that arrive at time 0, with the length of the CPU burst given in milliseconds:
If I use a time quantum of 4 seconds:

where:
- $P_1$ waits for 6 milliseconds ($10 - 4$), $P_2$ waits for 4 milliseconds, and $P_3$ waits for 7 milliseconds. Thus, the average waiting time is $17/3 = 5.66$ milliseconds.
For Example
Given three processes of 10 time units each and a quantum of 1 time unit, and they are all submitted at $t=0$, then
- the average turnaround time is $(28+29+30)/3=29$.
If the time quantum is 10, however:
- the average turnaround time drops to $(10+20+30)/3=20$.
Choice for Time Quantum
- If the context-switch time is approximately 10 percent of the time quantum, then about 10 percent of the CPU time will be spent in context switching. Thus
- we want the time quantum to be large with respect to the context switch time.
- however, if the time quantum is extremely large, the RR policy becomes the same as FCFS policy. A rule of thumb is that 80 percent of the bursts should be shorter than the time CPU quantum.
- In practice, most modern systems have time quanta ranging from 10 to 100 milliseconds. The time required for a context switch is typically less than 10 microseconds
Weighted RR and Weighted FQ
Weighted RR
Basically, now the time slice for each running task is calculated based on:
\[\text{time quantum} \times \text{weight}\]where the
weightcould be assigned by a user
Problem with RR and WRR
- In the end, they are similar, and they have the same problem of causing an application to freeze periodically, which would damage interactive-ness
- Also, it might be bugged if a user assigned
weight=3000, which would be problematic
However, the problem of weight=3000 can be solved with Weighted Fair Queue (WFQ):
Weighted Fair Queue
First, we need each task to have
- an execution time
runtime- a weighted associated
weightThen, the algorithm picks the smallest
\[\frac{\text{runtime}}{\text{weight}} = \text{vruntime}\]vruntime:where:
- you will soon notice that the Linux
CFShas its idea based off from here
For Example
Consider at t=0, three processes comes in with weight=3,2,1 respectively:
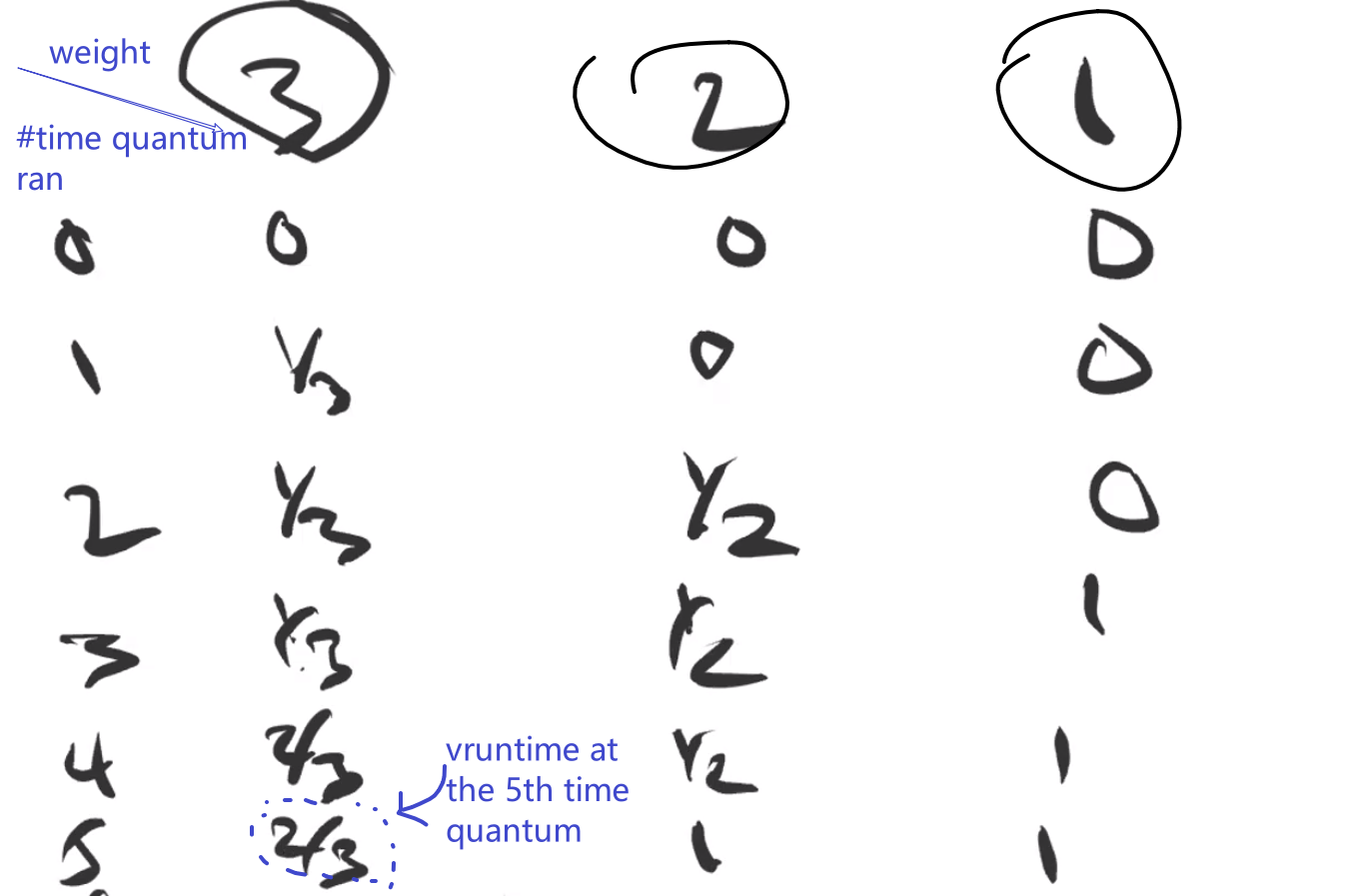
where you will see that:
- the net result over time would be $P_3$ will be ran 3 times more often than $P_2$, and $P_2$ will be ran 2 times more often than $P_1$
- one minor thing in the above is that at
t=0, we don’t know who to run. This is solved by virtual running time
Virtual Running Time
This is defined as:
\[\text{vruntime} + \frac{\text{time quantum time}}{\text{weight}}\]so that even at $t=0$, we have an offset
- so if the
time_quantum = 1, we would have:
- at $t=0$, $P_3 = 1/3, P_2 = 1/2, P_1 = 1$
Nominal Time
- What if after
3000cycles, a new process comes in? Then thevruntimeof the existing process will be already large, such that the new process will basically just run for a lot of cycles in a row- This is solved by assigning a new process with a nominal time as
vruntime
- e.g. the nominal time could be the average of
vruntimes of other processes- e.g. using the
global_virtual_time$\frac{\text{Wall Time}}{\sum \text{weights}}$
Multilevel Queue Scheduling
This class of algorithms has been created for situations in which processes are easily classified into different groups
- e.g. foreground (interactive) processes and background (batch) processes
Multilevel Queue Scheduling
- A multilevel queue scheduling algorithm partitions the ready queue into several separate queues.
- Each queue has its own scheduling algorithm.
- This also means there must be scheduling among the queues:
- commonly implemented as fixed-priority preemptive scheduling.
- For example, the foreground queue may have absolute priority over the background queue
- time-slice among the queues
- For instance, the foreground queue can be given 80 percent of the CPU time for RR scheduling among its processes, while the background queue receives 20 percent of the CPU to give to its processes on an FCFS basis.
- The processes are permanently assigned to one of the queues, generally based on some property of the process, such as memory size, process priority, or process type.
For Example:
A multilevel queue scheduling algorithm with five queues, listed below in order of (fixed) priority:
- System processes
- Interactive processes
- Interactive editing processes
- Batch processes
- Student processes
Then:
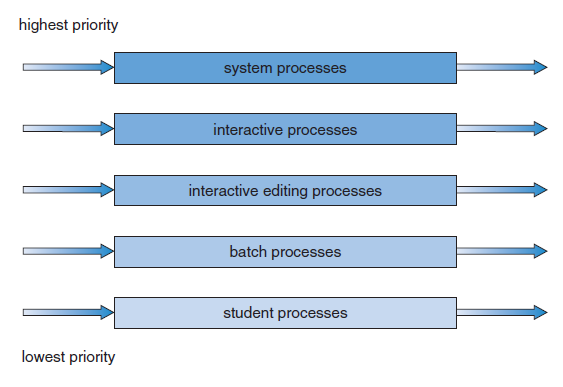
where, in this case of a fixed-priority preemptive scheduling among queues
- No process in the batch queue, for example, could run unless the queues for system processes, interactive processes, and interactive editing processes were all empty.
- If an interactive editing process entered the ready queue while a batch process was running, the batch process would be preempted.
Multilevel Feedback Queue Scheduling
In multilevel queue scheduling, since processes do not change their foreground or background nature, this setup has the advantage of low scheduling overhead, but it is inflexible.
Multilevel Feedback Queue Scheduling
- The multilevel feedback queue scheduling algorithm, in contrast, allows a process to move between queues. The idea is to separate processes according to the characteristics of their CPU bursts.
- If a process uses too much CPU time at once, it will be moved to a lower-priority queue. This scheme leaves I/O-bound and interactive processes in the higher-priority queues.
- a process that waits too long in a lower-priority queue may be moved to a higher-priority queue (so that starvation is prevented)
For Example:
Consider the following setup, with the top queue with the highest priority, and going down:
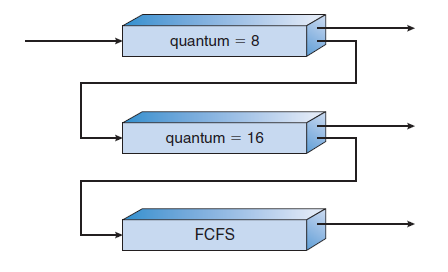
where, same as multilevel queue scheduling:
- processes in queue 2 will be executed only if queues 0 and 1 are empty, and etc.
- a process that arrives for queue 1 will preempt a process in queue 2, and etc.
This scheduling algorithm gives highest priority to any process with a CPU burst of 8 milliseconds or less (e.g. a process that needs 8 ms CPU -> I/O -> 6 ms CPU would also stay here)
- for example, a process entering the ready queue is put in queue 0.
- A process in queue 0 is given a time quantum of 8 milliseconds.
- If it does not finish within this time, it is moved to the tail of queue 1.
- If queue 0 is empty, the process at the head of queue 1 is given a quantum of 16 milliseconds.
- If it does not complete, it is preempted and is put into queue 2
- etc.
Customization
In general, a multilevel feedback queue scheduler is defined by the following parameters:
- The number of queues
- The scheduling algorithm for each queue
- The method used to determine when to upgrade a process to a higher priority queue
- The method used to determine when to demote a process to a lower priority queue
- The method used to determine which queue a process will enter when that process needs service
Thread Scheduling
First, some concepts will help.
Lightweight Process (LWP)
Light-weight process are threads in the user space that acts as an interface for the ULT to access the physical CPU resources. Thread library schedules which thread of a process to run on which LWP and how long.
The number of LWP created by the thread library depends on the type of application.
- in an I/O bound application, the number of LWP is equal to the number of the ULT (because when an LWP is blocked on an I/O operation, then to invoke the other ULT the thread library needs to create and schedule another LWP)
in a CPU bound application, it depends only on the application.
Each LWP is attached to a separate kernel-level thread.
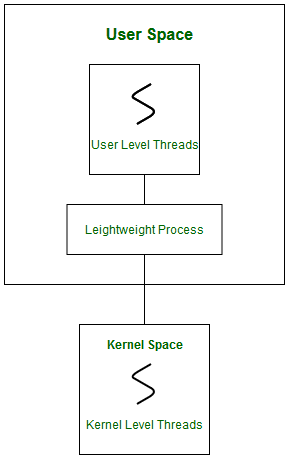
Scheduling of threads involves two boundary scheduling,
- Scheduling of user level threads (ULT) to kernel level threads (KLT) via lightweight process (LWP) by the application developer.
- Scheduling of kernel level threads by the system scheduler to perform different unique OS functions.
Contention Scope
Contention Scope
The word contention here refers to the competition or fight among the User level threads to access the kernel resources. Thus, this control defines the extent to which and where contention takes place.
- Process Contention Scope (PCS) – The contention takes place among threads (ULT) within a same process. The thread library schedules the high-prioritized PCS thread to access the resources via available LWPs (priority as specified by the application developer during thread creation).
- System Contention Scope (SCS) – The contention takes place among all (KLT) threads in the system. In this case, every SCS thread is associated to each LWP by the thread library and are scheduled by the system scheduler to access the kernel resources.
Pthread Scheduling
Pthreads identifies the following contention scope values:
PTHREAD_SCOPE_PROCESSschedules threads using PCS scheduling.PTHREAD_SCOPE_SYSTEMschedules threads using SCS scheduling.
The Pthread IPC (Interprocess Communication) provides two functions for getting and setting the contention scope policy:
pthread_attr_setscope(pthread_attr t *attr, int scope)pthread_attr_getscope(pthread_attr t *attr, int *scope)
where:
- The first parameter for both functions contains a pointer to the attribute set for the thread.
- The second parameter for the
pthread_attr_setscope()function is passed either thePTHREAD_SCOPE_SYSTEMor thePTHREAD_SCOPE_PROCESSvalue, indicating how the contention scope is to be set.- In the case of
pthread_attr_getscope(), this second parameter contains a pointer to an int value that is set to the current value of the contention scope. - If an error occurs, each of these functions returns a nonzero value.
- In the case of
Note
- For example, Linux and Mac OS X systems allow only
PTHREAD_SCOPE_SYSTEM
For Example
#include <pthread.h>
#include <stdio.h>
#define NUM THREADS 5
int main(int argc, char *argv[])
{
int i, scope;
pthread t tid[NUM THREADS];
pthread attr t attr;
/* get the default attributes */
pthread attr init(&attr);
/* first inquire on the current scope */
if (pthread attr getscope(&attr, &scope) != 0)
fprintf(stderr, "Unable to get scheduling scope\n");
else {
if (scope == PTHREAD SCOPE PROCESS)
printf("PTHREAD SCOPE PROCESS");
else if (scope == PTHREAD SCOPE SYSTEM)
printf("PTHREAD SCOPE SYSTEM");
else
fprintf(stderr, "Illegal scope value.\n");
}
/* set the scheduling algorithm to PCS or SCS */
pthread attr setscope(&attr, PTHREAD SCOPE SYSTEM);
/* create the threads */
for (i = 0; i < NUM THREADS; i++)
pthread create(&tid[i],&attr,runner,NULL);
/* now join on each thread */
for (i = 0; i < NUM THREADS; i++)
pthread join(tid[i], NULL);
}
/* Each thread will begin control in this function */
void *runner(void *param)
{
/* do some work ... */
pthread exit(0);
}
Multi-Processor Scheduling
If multiple CPUs are available, load sharing becomes possible - but scheduling problems become correspondingly more complex.
- e.g. consider a system with an device attached to a private bus of one processor I/O
Approaches to Multiple-Processor Scheduling
Asymmetric Multiprocessing
- all scheduling decisions, I/O processing, and other system activities handled by a single processor— the master server. The other processors execute only user code.
- simple because only one processor accesses the system data structures, reducing the need for data sharing.
Symmetric Multiprocessing (SMP)
- each processor is self-scheduling. All processes may be in a common ready queue, or each processor may have its own private queue of ready processes
- if we have multiple processors trying to access and update a common data structure, the scheduler must be programmed carefully. We must ensure that two separate processors do not choose to schedule the same process
Virtually all modern operating systems support SMP, including Windows, Linux, and Mac OS X.
Processor Affinity
Reminder
- The data most recently accessed by the process populate the cache for the processor. As a result, successive memory accesses by the process are often satisfied in cache memory
Now consider what happens if the process migrates to another processor.
- The contents of cache memory must be invalidated for the first processor
- and the cache for the second processor must be repopulated
Therefore most SMP systems try to avoid migration of processes from one processor to another and instead attempt to keep a process running on the same processor.
Processor Affinity
- A process has an affinity for the processor on which it is currently running, i.e. avoid migration of processes from one processor to another
- Processor affinity takes several forms:
- Soft affinity
- Hard affinity
Soft Affinity
- Operating system has a policy of attempting to keep a process running on the same processor, but not guaranteeing that it will do so.
- Here, the operating system will attempt to keep a process on a single processor, but it is possible for a process to migrate between processors
Linux implements soft affinity but it also provides the system call, which supports sched_setaffinity() hard affinity.
Hard Affinity
- allowing a process to specify a subset of processors on which it may run
Load Balancing
Load Balancing
- Load balancing attempts to keep the workload evenly distributed across all processors in an SMP system.
- It is important to note that load balancing is typically necessary only on systems where each processor has its own private queue of eligible processes to execute. (On systems with a common run queue, load balancing is often unnecessary, because once a processor becomes idle, it immediately extracts a runnable process from the common run queue.)
There are two general approaches to load balancing :
- Push Migration – In push migration a task routinely checks the load on each processor and if it finds an imbalance then it evenly distributes load on each processors by moving the processes from overloaded to idle or less busy processors.
- Pull Migration – Pull Migration occurs when an idle processor pulls a waiting task from a busy processor for its execution.
Note
- Load balancing often counteracts the benefits of processor affinity, so that either pulling or pushing a process from one processor to another removes this benefit
Multicore Processors
Reminder
- Each core maintains its architectural state and thus appears to the operating system to be a separate physical processor
- From an operating-system perspective, each hardware thread appears as a logical processor that is available to run a software thread
- Thus, on a dual-threaded, dual-core system, four logical processors are presented to the operating system.
Dual-Threaded Processor Core
- Basically this attempts to solve the problem of a memory stall:
- when a processor accesses memory, it spends a significant amount of time waiting for the data to become available. This situation, known as a memory stall, may occur for various reasons, such as a cache miss
- Therefore, recent hardware designs multithreaded processor cores in which two (or more) hardware threads are assigned to each core. That way, if one thread stalls while waiting for memory
M, the core can switch to another thread.
However, this also means that multithreaded multicore processor actually requires two different levels of scheduling.
- Scheduling decisions that must be made by the operating system as it chooses which software thread to run on each hardware thread (logical processor). Here, operating system may choose any scheduling algorithm that we have discussed before.
- Scheduling specifies how each core decides which hardware thread to run
- for example, the UltraSPARC T3 uses a simple round robin algorithm to schedule the eight hardware threads to each core.
Real-Time CPU Scheduling
Real Time OS
- Real time operating systems (RTOS) are used in environments where a large number of events, mostly external to the computer system, must be accepted and processed in a short time or within certain deadlines.
The real time operating systems can be of 2 types:
-
Hard Real Time operating system:
These operating systems guarantee that critical tasks be completed within a range of time.
For example, a robot is hired to weld a car body, if robot welds too early or too late, the car cannot be sold, so it is a hard real time system that require to complete car welding by robot hardly on the time.
-
Soft real time operating system:
This operating systems provides some relaxation in time limit.
Minimizing Latency
Minimizing Latency
- When an event occurs, the system must respond to and service it as quickly as possible. We refer to event latency as the amount of time that elapses from when an event occurs to when it is serviced
Two types of latencies affect the performance of real-time systems:
- Interrupt latency
- Dispatch latency
Interrupt Latency
- Interrupt latency refers to the period of time from the arrival of an interrupt at the CPU to the start of the routine that services the interrupt
- minimize interrupt latency to ensure that real-time tasks receive immediate attention
- Recall that when an interrupt occurs, the operating system must
- first complete the instruction it is executing
- determine the type of interrupt that occurred
- save the state of the current process
- service the interrupt using the specific interrupt service routine (ISR).
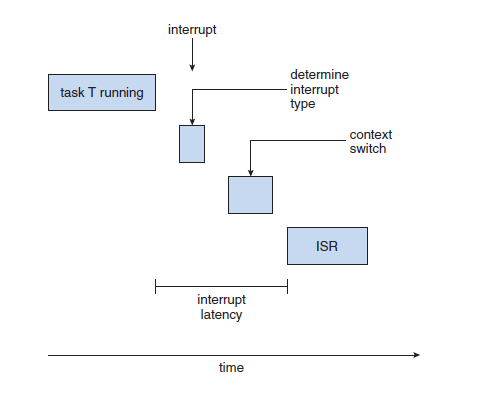
Note
- One important factor contributing to interrupt latency is the amount of time interrupts may be disabled while kernel data structures are being updated. Real-time operating systems require that interrupts be disabled for only very short periods of time.
Dispatch Latency
- The amount of time required for the scheduling dispatcher to stop one process and start another is known as dispatch latency.
- Providing real-time tasks with immediate access to the CPU mandates that real-time operating systems minimize this latency as well.
- The most effective technique for keeping dispatch latency low is to provide preemptive kernels
where the conflict phase of dispatch latency has two components:
- Preemption of any process running in the kernel
- Release by low-priority processes of resources needed by a high-priority process
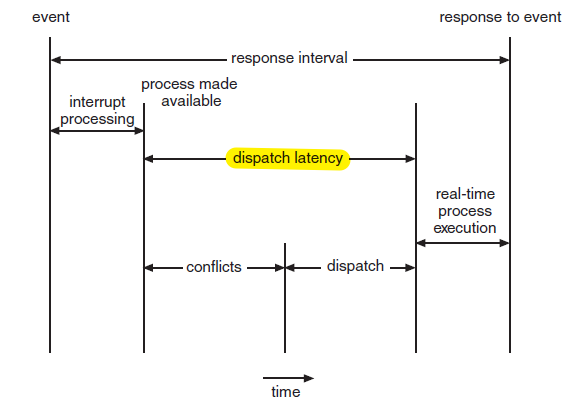
Priority-Based Scheduling
The most important feature of a real-time operating system is to respond immediately to a real-time process as soon as that process requires the CPU.
- As a result, the scheduler for a real-time operating system must support a priority-based algorithm with preemption
- Linux, Windows, and Solaris operating systems, each of these systems assigns real-time processes the highest scheduling priority
Characteristics of Real-Time Processes
First, the processes are considered periodic. That is, they require the CPU at constant intervals (periods).
Once a periodic process has acquired the CPU, it has:
- a fixed processing time $t$
- a deadline $d$ by which it must be serviced by the CPU by the start of its next period
- a period $p$.
The rate of a periodic task is $1/p$.
The relationship of the processing time, the deadline, and the period can be expressed as
\[0 ≤ t ≤ d ≤ p.\]
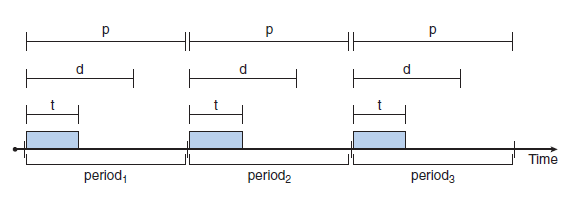
Therefore, this form of scheduling means a process may have to announce its deadline requirements to the scheduler.
Then, using a technique known as an admission-control algorithm, the scheduler does one of two things.
- It either admits the process, guaranteeing that the process will complete on time
- or rejects the request as impossible if it cannot guarantee that the task will be serviced by its deadline.
Rate-Monotonic Scheduling
Rate-Monotonic Scheduling
- The rate-monotonic scheduling algorithm schedules periodic tasks using a static priority policy with preemption
- Upon entering the system, each periodic task is assigned a priority inversely based on its period.
- so, the shorter the period, the higher the priority; the longer the period, the lower the priority
- rate-monotonic scheduling assumes that the processing time of a periodic process is the same for each CPU burst
For Example
We have two processes, P1 and P2.
- The periods for $P_1$ and $P_2$ are $50$ and $100$, respectively—that is, $p_1 = 50$ and $p_2 = 100$.
- The processing times are $t_1 = 20$ for $P_1$ and $t_2 = 35$ for $P_2$.
- The deadline for each process requires that it complete its CPU burst by the start of its next period.
First, we need to consider if it is at all possible.
- If we measure the CPU utilization of a process $P_i$ as the ratio of its burst to its period—$t_i/p_i$ —the CPU utilization of $P_1$ is $20/50 = 0.40$ and that of $P_2$ is $35/100 = 0.35$, for a total CPU utilization of $75$ percent.
- Therefore, it seems we can schedule these tasks in such a way that both meet their deadlines and still leave the CPU with available cycles
Now suppose we use rate-monotonic scheduling, in which we assign $P_1$ a higher priority than $P_2$ because the period of $P_1$ is shorter than that of $P_2$.
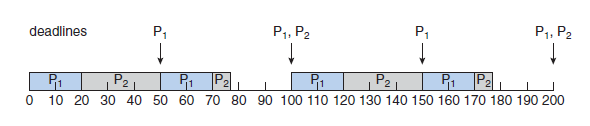
where we see that it works:
- $P_2$ completes its burst at time $75$, also meeting its first deadline. The CPU system is idle until time $100$, when $P_1$ is scheduled again.
Note
Rate-monotonic scheduling is considered optimal in that if a set of processes cannot be scheduled by this algorithm, it cannot be scheduled by any other algorithm that assigns static priorities
Despite being optimal, then, rate-monotonic scheduling has a limitation:
CPU utilization is bounded, and it is not always possible fully to maximize CPU resources. The worst-case CPU utilization for scheduling $N$ processes is
\[N(2^{1/N}-1)\]
Earliest-Deadline-First Scheduling
Earliest-Deadline-First Scheduling
- Earliest-deadline-first (EDF) scheduling dynamically assigns priorities according to deadline (i.e. deadline changes as time proceeds).
- Under the EDF policy, when a process becomes runnable, it must announce its deadline requirements to the system
- theoretically, it can schedule processes so that each process can meet its deadline requirements and CPU utilization will be 100 percent.
- In practice, however, it is impossible to achieve this level of CPU utilization due to the cost of context switching between processes and interrupt handling.
Difference with Rate-Monotonic Algorithm
- Unlike the rate-monotonic algorithm, EDF scheduling does not require that processes be periodic, nor must a process require a constant amount of CPU time per burst.
- The only requirement is that a process announce its deadline to the scheduler when it becomes runnable.
For Example
Consider the setup of
- $P_1$ has values of $p_1 = 50$ and $t_1 = 25$
- $P_2$ has values of $p_2 = 80$ and $t_2 = 35$
- The deadline for each process requires that it complete its CPU burst by the start of its next period
The EDF scheduling of these processes is shown below:
- note that rate-monotonic algorithm actually cannot solve this problem
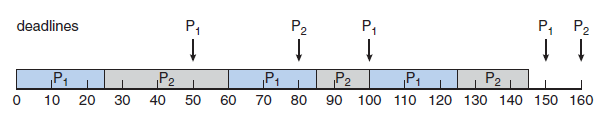
where we see that:
- Process $P_1$ has the earliest deadline, so its initial priority is higher than that of process $P_2$.
- However, whereas rate-monotonic scheduling allows $P_1$ to preempt $P_2$, at the beginning of its next period at time $50$, EDF scheduling allows process P2 to continue running. This is because $P_2$ now has a higher priority than $P_1$ because its next deadline (at time $80$) is earlier than that of $P_1$ (at time $100$).
OS Scheduling Examples
Here, we are In fact describing
- the scheduling of kernel threads with Solaris and Windows systems
- the scheduling of tasks with the Linux scheduler.
Linux Scheduling
In release 2.6.23 of the kernel, the Completely Fair Scheduler (CFS) became the default Linux scheduling algorithm.
Scheduling in Linux
Scheduling in the Linux system is based on scheduling classes.
Each class is assigned a specific priority. By using different scheduling classes, the kernel can accommodate different scheduling algorithms based on the needs of the system and its processes.
(Essentially, it looks like a multi-level queue system)
- To decide which task to run next, the scheduler selects the highest-priority task belonging to the highest-priority scheduling class.
- Standard Linux kernels implement two scheduling classes:
- a default scheduling class using the CFS scheduling algorithm
- a real-time scheduling class.
CFS in Linux
the CFS scheduler assigns a proportion of CPU processing time to each task. This proportion is calculated based on the nice value assigned to each task.
Nice values range from $−20$ to $+19$, where a numerically lower nice value indicates a higher relative priority. (i.e. low nice value means being not “nice” to other processes)
CFS doesn’t use discrete values of time slices and instead identifies a targeted latency, which is an interval of time during which every runnable task should run at least once.
- Therefore, proportions of CPU time are allocated from the value of targeted latency.
The CFS scheduler doesn’t directly assign priorities. Rather, it records how long each task has run by maintaining the virtual run time of each task using the per-task variable
vruntime.
The virtual run time is associated with a decay factor based on the priority (
\[vruntime += timeRanJustNow * decayOrGrowthFactor\]nicevalue) of a task: lower-priority tasks have higher rates of decay than higher-priority tasks.For tasks at normal priority (nice values of 0), virtual run time is identical to actual physical run time.
However, if a lower-priority task runs for 200 milliseconds, its
vruntimewill be higher than 200 milliseconds
In summary:
- proportion of processing time is calculated based on
nicevalue - priority is calculated based on
vruntime, which depends on actual runtime andnicevalue
Since this is priority-based preemption, this is how the processes are structured using a red-black tree (priority queue)
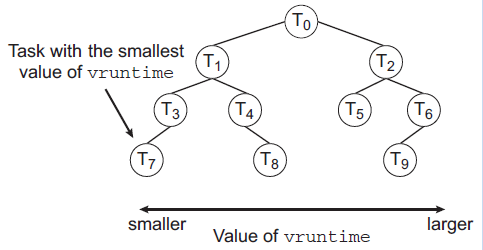
where tasks that have been given more processing time (lower priority) are on the right side
For Example
Assume that two tasks have the same nice values. One task is I/O-bound and the other is CPU-bound.
- Typically, the I/O-bound task will run only for short periods before blocking for additional I/O, and the CPU-bound task will exhaust its time period whenever it has an opportunity to run on a processor.
Therefore, the value of vruntime will eventually be lower for the I/O-bound task than for the CPU-bound task, giving the I/O-bound task higher priority than the CPU-bound task.
At that point, if the CPU-bound task is executing when the I/O-bound task becomes eligible to run (for example, when I/O the task is waiting for becomes available), the I/O-bound task will preempt the CPU-bound task.
Real-Time Tasks In Linux
- Any task scheduled using either the
SCHED_FIFOor theSCHED_RRreal-time policy runs at a higher priority than normal- Linux uses two separate priority ranges, one for real-time tasks and a second for normal tasks.
- Normal tasks are assigned a priority based on their
nicevalues, where a value of $–20$ maps to priority $100$ and a nice value of $+19$ maps to $139$- Real-time tasks are assigned static priorities within the range of $0$ to $99$, and normal (i.e. non real-time) tasks are assigned priorities from $100$ to $139$.

Actual Linux Implementation
Linux Scheduling
In general, the Linux scheduling is done in
kernel/sched/core.c, and it has the functionality of:
- pick the next task to run
- re-order tasks on the run queue
- put tasks on the run queue (e.g. when it is
runnable)- remove tasks from run queue (e.g. when it is
blocked)- have different policies by having different scheduling classes (e.g.
real-timescheduling class as an example for later section)
In terms of code, this is what happened:
-
we start with
schedule()inkernel/sched/core.casmlinkage __visible void __sched schedule(void) { struct task_struct *tsk = current; sched_submit_work(tsk); do { preempt_disable(); /* here it does the main schedule */ __schedule(false); sched_preempt_enable_no_resched(); } while (need_resched()); sched_update_worker(tsk); } EXPORT_SYMBOL(schedule);then Inside
__schedule(): which does:-
gets the run queue as well as the run queue lock
-
picks the next task
static void __sched notrace __schedule(bool preempt) { struct task_struct *prev, *next; unsigned long *switch_count; struct rq_flags rf; struct rq *rq; int cpu; cpu = smp_processor_id(); /* 1. gets the run queue as well as the run queue lock */ /* RUN QUEUE PER CPU! */ rq = cpu_rq(cpu); prev = rq->curr; /* some code omitted */ rq_lock(rq, &rf); /* 2. picks the next task */ switch_count = &prev->nivcsw; if (!preempt && prev->state) { if (signal_pending_state(prev->state, prev)) { prev->state = TASK_RUNNING; } else { /* not runnable tasks are removed */ deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK); if (prev->in_iowait) { atomic_inc(&rq->nr_iowait); delayacct_blkio_start(); } } switch_count = &prev->nvcsw; } /* picks the next task */ next = pick_next_task(rq, prev, &rf); /* some code omitted */ if (likely(prev != next)) { /* if there is only one job, then prev = next since running job * by default is still on the queue */ /* this is when the prev=current job stops running, and the next one starts*/ /* Also unlocks the rq: */ rq = context_switch(rq, prev, next, &rf); } else { rq->clock_update_flags &= ~(RQCF_ACT_SKIP|RQCF_REQ_SKIP); rq_unlock_irq(rq, &rf); } /* some code omitted here */ }then the
pick_next_task()will go to:-
this will call the scheduling algorithm specific to each
sched_classpick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf) { const struct sched_class *class; struct task_struct *p; /* * Optimization: we know that if all tasks are in the fair class we can * call that function directly, but only if the @prev task wasn't of a * higher scheduling class, because otherwise those loose the * opportunity to pull in more work from other CPUs. */ /* this is just optimization since the DEFAULT sched class is CFS * therefore, it picks from this directly if the condition holds */ if (likely((prev->sched_class == &idle_sched_class || prev->sched_class == &fair_sched_class) && rq->nr_running == rq->cfs.h_nr_running)) { /* 1. picks next task by a SCHEDULER CLASS */ p = fair_sched_class.pick_next_task(rq, prev, rf); if (unlikely(p == RETRY_TASK)) goto restart; /* Assumes fair_sched_class->next == idle_sched_class */ if (unlikely(!p)) p = idle_sched_class.pick_next_task(rq, prev, rf); return p; } /* CLASS SPECIFIC LOAD BALANCING before pick_next_task */ for_class_range(class, prev->sched_class, &idle_sched_class) { if (class->balance(rq, prev, rf)) break; } put_prev_task(rq, prev); /* 2. Picks by each SCHEDULER CLASS. MAIN ENTRY POINT */ for_each_class(class) { /* calls the particular class's function */ p = class->pick_next_task(rq, NULL, NULL); if (p) return p; } }where:
- each ` struct sched_class *class
would have its **own scheduling algorithm**class->pick_next_task(rq, NULL, NULL);`, such as based on priority. This allows some customization. - this basically looks like the mechanism of a Multilevel Queue Scheduling
For Example
There is an idle
sched_classwhich basically runs when there is no process running.static struct task_struct * pick_next_task_idle(struct rq *rq, struct task_struct *prev, struct rq_flags *rf) { struct task_struct *next = rq->idle; if (prev) put_prev_task(rq, prev); set_next_task_idle(rq, next); /* basically runs the a PREDEFINED IDLE task */ return next; } /* some code omitted here */ const struct sched_class idle_sched_class = { /* .next is NULL */ /* no enqueue/yield_task for idle tasks */ /* dequeue is not valid, we print a debug message there: */ .dequeue_task = dequeue_task_idle, .check_preempt_curr = check_preempt_curr_idle, /* defined pick_next_task function */ .pick_next_task = pick_next_task_idle, .put_prev_task = put_prev_task_idle, .set_next_task = set_next_task_idle, /* some code omitted here */ }; - each ` struct sched_class *class
-
-
-
When a new task is created, you will need to:
- assign static priority number (which will be later converted to nice values)
- assign scheduling classes
int sched_fork(unsigned long clone_flags, struct task_struct *p) { unsigned long flags; __sched_fork(clone_flags, p); p->state = TASK_NEW; p->prio = current->normal_prio; uclamp_fork(p); /* 1. assign priority/ static priority */ if (unlikely(p->sched_reset_on_fork)) { if (task_has_dl_policy(p) || task_has_rt_policy(p)) { p->policy = SCHED_NORMAL; p->static_prio = NICE_TO_PRIO(0); p->rt_priority = 0; } else if (PRIO_TO_NICE(p->static_prio) < 0) p->static_prio = NICE_TO_PRIO(0); p->prio = p->normal_prio = __normal_prio(p); set_load_weight(p, false); /* * We don't need the reset flag anymore after the fork. It has * fulfilled its duty: */ p->sched_reset_on_fork = 0; } /* 2. assign schedulng class */ if (dl_prio(p->prio)) return -EAGAIN; else if (rt_prio(p->prio)) p->sched_class = &rt_sched_class; else p->sched_class = &fair_sched_class; /* some code omitted htere */ }Note
-
Again, this
sched_forkis called bycopy_process()inkernel/fork.c, which will be called bydo_fork(), fromfork()/clone()static __latent_entropy struct task_struct *copy_process( struct pid *pid, int trace, int node, struct kernel_clone_args *args) { int pidfd = -1, retval; struct task_struct *p; struct multiprocess_signals delayed; struct file *pidfile = NULL; u64 clone_flags = args->flags; /* * Don't allow sharing the root directory with processes in a different * namespace */ if ((clone_flags & (CLONE_NEWNS|CLONE_FS)) == (CLONE_NEWNS|CLONE_FS)) return ERR_PTR(-EINVAL); /* some code omitted here */ /* Perform scheduler related setup. Assign this task to a CPU. */ /* calls sched_fork */ retval = sched_fork(clone_flags, p); /* some code omitted hetre */ /* and then duplicates the data from the other process */ p = dup_task_struct(current, node); /* some code omitted herte */ }and then
dup_task_structwill do:static struct task_struct *dup_task_struct(struct task_struct *orig, int node) { struct task_struct *tsk; unsigned long *stack; struct vm_struct *stack_vm_area __maybe_unused; int err; /* some code omitted here */ err = arch_dup_task_struct(tsk, orig); /* some code omitted here */ }which in turn calls the architecture specific
arch_dup_task_struct:- here, I am looking at the
x86one:
int arch_dup_task_struct(struct task_struct *dst, struct task_struct *src) { /* just does a memory copy */ memcpy(dst, src, arch_task_struct_size); #ifdef CONFIG_VM86 dst->thread.vm86 = NULL; #endif return fpu__copy(dst, src); } - here, I am looking at the
Note
In general (also mentioned above), there will be a private run queue per scheduler
this is very common, because:
- if there is a common run queue for all CPUs, then there is the bottleneck of all reading/editing one run queue -> needs locking - therefore, we need to somehow decide which run queues/CPU a process/task should go to
If a process is created from
fork(), then by default it will inherit the scheduling class of its parent

Related sched.h
In general, you might need to change two sched.h
include/linux/sched.hkernel/sched/sched.h
This section will focus on the example of the real-time scheduling class.
Inside the file kernel/sched/sched.h for scheduling in Linux, which defines most of the structures in an almost Object Oriented Fashion.
Inside kernel/sched/sched.h
-
add the
rt_rqto the per CPUrq -
(if needed) add the
rt_rqand class related initialization code-
this will be called in
void __init sched_init(void)insidekernel/sched/core.cat start upvoid __init sched_init(void) { /* some code omitted here */ for_each_possible_cpu(i) { struct rq *rq; rq = cpu_rq(i); raw_spin_lock_init(&rq->lock); /* initializes RUN QUEUES */ init_cfs_rq(&rq->cfs); init_rt_rq(&rq->rt); init_dl_rq(&rq->dl); /* some code omitted here */ } /* some code omitted here */ /* other initialization */ init_sched_fair_class(); init_schedstats(); psi_init(); init_uclamp(); scheduler_running = 1; }
-
/* defines the highest priority sched class */
#ifdef CONFIG_SMP
#define sched_class_highest (&stop_sched_class)
#else
#define sched_class_highest (&dl_sched_class)
#endif
/* defines the "Parent" sched class structure */
struct sched_class {
/* 1. tells us what is the NEXT scheduling class afterwards */
const struct sched_class *next;
void (*enqueue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*dequeue_task) (struct rq *rq, struct task_struct *p, int flags);
void (*yield_task) (struct rq *rq);
bool (*yield_to_task)(struct rq *rq, struct task_struct *p, bool preempt);
struct task_struct * (*pick_next_task)(struct rq *rq,
struct task_struct *prev,
struct rq_flags *rf);
/* some code omitted here */
};
struct rq {
/* runqueue lock: */
raw_spinlock_t lock;
/* some code omitted here */
/* 1. add the `rt_rq` to the per CPU `rq` */
struct cfs_rq cfs;
struct rt_rq rt; /* scheduling class specific rq */
struct dl_rq dl;
};
/* Real-Time classes' related field in a runqueue: */
struct rt_rq {
/* the actual queue for rt_rq */
struct rt_prio_array active;
/* some code omitted here */
struct rq *rq;
struct task_group *tg;
};
/* 2. rt sched class initialization code */
extern void init_sched_rt_class(void);
where:
- essentially, the per CPU
struct rqis just a nominal placeholder for the different run queues of the differentsched_class
Note
You will see that in many
sched_classimplementations in kernel, not all methods need to be implementedThis also means that sometimes, if the kernel has explicit checks if a method is
null, then it is fine. Some other times, you might need to implement no-op functions.For example:
/* inside idle sched_class */ static void update_curr_idle(struct rq *rq) { }
Now, for implementation, this is more important.
Inside include/linux/sched.h, we need to have:
-
defines the actual structure to be queued in the private run queues. This is because, for group scheduling mechanism in Linux, so that sometimes you can enqueue group of tasks (not required for this course).
struct task_struct { #ifdef CONFIG_THREAD_INFO_IN_TASK /* some code omitted here */ /* 1. defines the actual structure to be queued in the private run queues */ unsigned int rt_priority; /* rt class specific parameters */ const struct sched_class *sched_class; struct sched_entity se; struct sched_rt_entity rt; /* in the rq */ /* some code omitted here */ /* sometimes, a sched class can have MULTIPLE policies * in this case, this thing has to be set */ unsigned int policy; }then, inside the
rt_priority, this is insidekernel/sched/sched.hstruct rt_prio_array { DECLARE_BITMAP(bitmap, MAX_RT_PRIO+1); /* include 1 bit for delimiter */ struct list_head queue[MAX_RT_PRIO]; /* ARRAYS OF QUEUES */ };where:
- it uses an array of run queue because its implementation idea is similar to Priority Scheduling
Real-time sched class Implementation
Last but not least, let us look at the actual implementations for the needed methods
- this is inside
kernel/sched/rt.c
Here, we see that:
-
The implementation of the
sched_classobject:const struct sched_class rt_sched_class = { /* next sched_class */ .next = &fair_sched_class, /* defintely needed, used by activate_task */ .enqueue_task = enqueue_task_rt, /* add a new task into the queue */ /* defintely needed, used by deactivate_task */ .dequeue_task = dequeue_task_rt, .yield_task = yield_task_rt, .check_preempt_curr = check_preempt_curr_rt, /* defintely needed */ .pick_next_task = pick_next_task_rt, /* picks next task */ .put_prev_task = put_prev_task_rt, .set_next_task = set_next_task_rt, #ifdef CONFIG_SMP /* needed if have load balancing */ .balance = balance_rt, /* needed if multiprocessor */ .select_task_rq = select_task_rq_rt, /* decides which CPU to use */ .set_cpus_allowed = set_cpus_allowed_common, .rq_online = rq_online_rt, .rq_offline = rq_offline_rt, .task_woken = task_woken_rt, .switched_from = switched_from_rt, #endif /* needed if have timer interrupts */ .task_tick = task_tick_rt, /* manages time quantum */ .get_rr_interval = get_rr_interval_rt, .prio_changed = prio_changed_rt, .switched_to = switched_to_rt, .update_curr = update_curr_rt, #ifdef CONFIG_UCLAMP_TASK .uclamp_enabled = 1, #endif };Note
- Most of the time, we you enter your scheduling class specific code, a
lockwill have been held already for you.
- Most of the time, we you enter your scheduling class specific code, a
-
The
enqueue_task_rq:/* * Adding/removing a task to/from a priority array: */ static void enqueue_task_rt(struct rq *rq, struct task_struct *p, int flags) { /* ENQUEUES the ENTITY, not the task directly */ struct sched_rt_entity *rt_se = &p->rt; if (flags & ENQUEUE_WAKEUP) rt_se->timeout = 0; enqueue_rt_entity(rt_se, flags); if (!task_current(rq, p) && p->nr_cpus_allowed > 1) enqueue_pushable_task(rq, p); }then, this calls
enqueue_rt_entity:static void enqueue_rt_entity(struct sched_rt_entity *rt_se, unsigned int flags) { struct rq *rq = rq_of_rt_se(rt_se); dequeue_rt_stack(rt_se, flags); /* this loop is to deal with the sched_group */ for_each_sched_rt_entity(rt_se) __enqueue_rt_entity(rt_se, flags); enqueue_top_rt_rq(&rq->rt); }where:
- if we do not need to deal with sched groups, then only a single call to
__enqueue_rt_entity(rt_se, flags)would be fine.
lastly, the
__enqueue_rt_entity:static void __enqueue_rt_entity(struct sched_rt_entity *rt_se, unsigned int flags) { /* first gets the queue */ struct rt_rq *rt_rq = rt_rq_of_se(rt_se); struct rt_prio_array *array = &rt_rq->active; struct rt_rq *group_rq = group_rt_rq(rt_se); struct list_head *queue = array->queue + rt_se_prio(rt_se); /* some code omitted here */ if (move_entity(flags)) { WARN_ON_ONCE(rt_se->on_list); if (flags & ENQUEUE_HEAD) list_add(&rt_se->run_list, queue); else /* add a NEW task to the end of run queue */ list_add_tail(&rt_se->run_list, queue); __set_bit(rt_se_prio(rt_se), array->bitmap); rt_se->on_list = 1; } /* some code omitted here */ }Note
-
this function
enqueue_task_rtgets called by the following mechanism-
First, the scheduler calls in
kernel/sched/core.c:void wake_up_new_task(struct task_struct *p) { struct rq_flags rf; struct rq *rq; raw_spin_lock_irqsave(&p->pi_lock, rf.flags); p->state = TASK_RUNNING; rq = __task_rq_lock(p, &rf); /* some code omitted here */ /* wakes up task from a RUN QUEUE */ activate_task(rq, p, ENQUEUE_NOCLOCK); /* some code omitted here */ task_rq_unlock(rq, p, &rf); }where:
- notice that the
rq_lockis added here already
- notice that the
-
then the
activate_taskgoes tovoid activate_task(struct rq *rq, struct task_struct *p, int flags) { if (task_contributes_to_load(p)) rq->nr_uninterruptible--; /* actual enqueue task */ enqueue_task(rq, p, flags); p->on_rq = TASK_ON_RQ_QUEUED; } -
Lastly, the per scheduling class method is called here:
static inline void enqueue_task(struct rq *rq, struct task_struct *p, int flags) { /* some code omitted here */ uclamp_rq_inc(rq, p); /* per scheduling class method, just using TASK_STRUCT */ p->sched_class->enqueue_task(rq, p, flags); }where:
- this also explained why you need to add some extra information in the task struct
-
- if we do not need to deal with sched groups, then only a single call to
-
Now, we need a
_pick_next_task:static struct task_struct *_pick_next_task_rt(struct rq *rq) { struct sched_rt_entity *rt_se; struct rt_rq *rt_rq = &rq->rt; do { /* the actual algorithm */ rt_se = pick_next_rt_entity(rq, rt_rq); BUG_ON(!rt_se); rt_rq = group_rt_rq(rt_se); } while (rt_rq); return rt_task_of(rt_se); }then, it calls ` pick_next_rt_entity`
static struct sched_rt_entity *pick_next_rt_entity(struct rq *rq, struct rt_rq *rt_rq) { struct rt_prio_array *array = &rt_rq->active; struct sched_rt_entity *next = NULL; struct list_head *queue; int idx; /* looks up the bitmap */ idx = sched_find_first_bit(array->bitmap); BUG_ON(idx >= MAX_RT_PRIO); /* picks the FIRST task from the top priority queue */ queue = array->queue + idx; next = list_entry(queue->next, struct sched_rt_entity, run_list); return next; } -
Now, since
rt_schedhas two policies (FIDO AND round-robin), the round-robin one needs a timer interrupt (since it has a time quantum). This is achieved bytask_tick:- if the policy is not
rr, then do nothing (since FIFO doesn’t care how long it runs) - if it is
rr, then decrement the time slice - lastly, when the time slice reached 0, requeue it, and then
static void task_tick_rt(struct rq *rq, struct task_struct *p, int queued) { struct sched_rt_entity *rt_se = &p->rt; update_curr_rt(rq); update_rt_rq_load_avg(rq_clock_pelt(rq), rq, 1); watchdog(rq, p); /* * RR tasks need a special form of timeslice management. * FIFO tasks have no timeslices. */ if (p->policy != SCHED_RR) /* 1. if the policy is not `rr`, then do nothing */ return; /* 2. decrement the time slice */ if (--p->rt.time_slice) return; /* 3. give it a new time slice, and REQUEUE it */ p->rt.time_slice = sched_rr_timeslice; /* * Requeue to the end of queue if we (and all of our ancestors) are not * the only element on the queue */ for_each_sched_rt_entity(rt_se) { if (rt_se->run_list.prev != rt_se->run_list.next) { /* requeue it by removing and putting it to TAIL */ requeue_task_rt(rq, p, 0); /* attemps to let SCHEDULER to RESCHEDULE for a new TASK by SETTING A SIGNAL FLAG _TIF_NEED_RESCHED */ resched_curr(rq); return; } } }where:
-
the
resched_curractually does not call the scheduler directly (because we are at a Timer Interrupt)- It sets a flag for reschedule for the
currprocess - similar to
SIGPEND, this will be processed at theexit_to_usermode
void resched_curr(struct rq *rq) { struct task_struct *curr = rq->curr; int cpu; lockdep_assert_held(&rq->lock); if (test_tsk_need_resched(curr)) return; cpu = cpu_of(rq); if (cpu == smp_processor_id()) /* 1. sets a flag for reschedule */ set_tsk_need_resched(curr); set_preempt_need_resched(); return; } /* some code omitted here */ }then to be processed:
/* rescheule flag definition */ #define EXIT_TO_USERMODE_LOOP_FLAGS \ (_TIF_SIGPENDING | _TIF_NOTIFY_RESUME | _TIF_UPROBE | \ _TIF_NEED_RESCHED | _TIF_USER_RETURN_NOTIFY | _TIF_PATCH_PENDING) static void exit_to_usermode_loop(struct pt_regs *regs, u32 cached_flags) { /* * In order to return to user mode, we need to have IRQs off with * none of EXIT_TO_USERMODE_LOOP_FLAGS set. Several of these flags * can be set at any time on preemptible kernels if we have IRQs on, * so we need to loop. Disabling preemption wouldn't help: doing the * work to clear some of the flags can sleep. */ while (true) { /* We have work to do. */ local_irq_enable(); /* if need to reschedule, reschedule here */ if (cached_flags & _TIF_NEED_RESCHED) schedule(); } } - It sets a flag for reschedule for the
Note
-
If we need something like a Round-Robin algorithm, we need a timer interrupt. This is achieved by
scheduler_tick()insidekernel/sched/core.c, which eventually calls per sched-classtask_tick:/* * This function gets called by the timer code, with HZ frequency. * We call it with interrupts disabled. */ void scheduler_tick(void) { /* some code omitted here */ sched_clock_tick(); rq_lock(rq, &rf); update_rq_clock(rq); /* calls per sched class task_tick */ curr->sched_class->task_tick(rq, curr, 0); calc_global_load_tick(rq); psi_task_tick(rq); rq_unlock(rq, &rf); perf_event_task_tick(); #ifdef CONFIG_SMP rq->idle_balance = idle_cpu(cpu); trigger_load_balance(rq); #endif }
- if the policy is not
-
To know which CPU to run on (e.g. you need to know which lock/run queue to grab), it uses the:
/* DETERMINES WHICH CPU to RUN ON */ static int select_task_rq_rt(struct task_struct *p, int cpu, int sd_flag, int flags) { struct task_struct *curr; struct rq *rq; /* For anything but wake ups, just return the task_cpu */ if (sd_flag != SD_BALANCE_WAKE && sd_flag != SD_BALANCE_FORK) goto out; rq = cpu_rq(cpu); rcu_read_lock(); curr = READ_ONCE(rq->curr); /* unlocked access */ /* some code omitted here */ rcu_read_unlock(); /* most of the time, the same CPU passed in */ out: return cpu; }Note
-
the
select_task_rq_rtis called in many scenarios (e.g. load-balancing). Here, the example is when a new task is created:void wake_up_new_task(struct task_struct *p) { struct rq_flags rf; struct rq *rq; /* some code omitted here */ /* assigns WHICH CPU to run on */ p->recent_used_cpu = task_cpu(p); __set_task_cpu(p, select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0)); /* some code omitted here */ }where it actually calls the
select_task_rq(p, task_cpu(p), SD_BALANCE_FORK, 0):int select_task_rq(struct task_struct *p, int cpu, int sd_flags, int wake_flags) { lockdep_assert_held(&p->pi_lock); /* calls the scheduler based select_task_rq */ if (p->nr_cpus_allowed > 1) cpu = p->sched_class->select_task_rq(p, cpu, sd_flags, wake_flags); else cpu = cpumask_any(p->cpus_ptr); /* some code omitted here */ return cpu; }
-
-
Additionally, if some initialization is needed for the queue/sched class, you can have:
void init_rt_rq(struct rt_rq *rt_rq) { struct rt_prio_array *array; int i; /* some code omitted here */ }Note
-
this initialization code is called by
void __init sched_init(void)insidekernel/sched/core.c, which is in turn called byinit/main.cat start up of kernelasmlinkage __visible void __init start_kernel(void) { char *command_line; char *after_dashes; /* some code omitted here */ /* * Set up the scheduler prior starting any interrupts (such as the * timer interrupt). Full topology setup happens at smp_init() * time - but meanwhile we still have a functioning scheduler. */ sched_init(); /* some code omitted heret */ }
-
-
More interestingly, if you do load balancing, and the method
balance()will be doing the job:-
in short, the kernel will first do
balance() -> pick_next_taskstatic inline struct task_struct * pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf) { /* some code omitted here */ /* first balance */ for_class_range(class, prev->sched_class, &idle_sched_class) { if (class->balance(rq, prev, rf)) break; } put_prev_task(rq, prev); /* then pick_next_class */ for_each_class(class) { p = class->pick_next_task(rq, NULL, NULL); if (p) return p; } } -
but now, since we are accessing other CPU’s run queues, we need to grab other run queue’s lock, then you might need to deal with deadlock situations
Deadlocks for Load Balancing
-
One possibility is as follows: if
rq1wants to do some load balancing, and at the same timerq2also wants to do some load balancing, this deadlock might happen:
where we see the solution is to grab the lock in the same order:
- release your own lock (if you are not
CPU1/lowest CPU)- so you need to be aware that state might change at the same time
- attempt to grab lock starting from the lowest CPU
- release your own lock (if you are not
-
Now, to the actual definition of
rtclass:- essentially, it calls
pull_rt_task(), which goes through each CPU, and does the Pull Migration
static int balance_rt(struct rq *rq, struct task_struct *p, struct rq_flags *rf) { if (!on_rt_rq(&p->rt) && need_pull_rt_task(rq, p)) { /* * This is OK, because current is on_cpu, which avoids it being * picked for load-balance and preemption/IRQs are still * disabled avoiding further scheduler activity on it and we've * not yet started the picking loop. */ rq_unpin_lock(rq, rf); /* 1. the main entry point */ pull_rt_task(rq); rq_repin_lock(rq, rf); } return sched_stop_runnable(rq) || sched_dl_runnable(rq) || sched_rt_runnable(rq); }-
then the
pull_rt_task()does an iteration for ALL CPU’s RUNQUEUE (now, you need to do the deadlock prevention viadouble_lock_balance()), and then:- select which task to be pulled
- deactivate/remove that task from the
srcrun queue - activate/add that task to the
this_rqrun queue
static void pull_rt_task(struct rq *this_rq) { int this_cpu = this_rq->cpu, cpu; bool resched = false; struct task_struct *p; struct rq *src_rq; int rt_overload_count = rt_overloaded(this_rq); if (likely(!rt_overload_count)) return; /* some code omitted here */ /* LOOPS OVER EACH CPU AND LOAD BALANCE */ for_each_cpu(cpu, this_rq->rd->rto_mask) { /* some code omitted here */ /* * We can potentially drop this_rq's lock in * double_lock_balance, and another CPU could * alter this_rq */ double_lock_balance(this_rq, src_rq); /* 1. DECIDES WHICH TASK TO PULL */ /* * We can pull only a task, which is pushable * on its rq (NOT RUNNING), and no others. */ p = pick_highest_pushable_task(src_rq, this_cpu); /* * Do we have an RT task that preempts * the to-be-scheduled task? */ if (p && (p->prio < this_rq->rt.highest_prio.curr)) { /* some code omitted here */ /* 2. REMOVE A TASK FROM A RUN QUEUE */ deactivate_task(src_rq, p, 0); set_task_cpu(p, this_cpu); /* 3. ADD A TASK TO MY RUN QUEUE */ activate_task(this_rq, p, 0); /* * We continue with the search, just in * case there's an even higher prio task * in another runqueue. (low likelihood * but possible) */ } skip: double_unlock_balance(this_rq, src_rq); } if (resched) resched_curr(this_rq); }where the
double_lock_balancein the end goes to:-
_double_lock_balance:static inline int _double_lock_balance(struct rq *this_rq, struct rq *busiest) __releases(this_rq->lock) __acquires(busiest->lock) __acquires(this_rq->lock) { int ret = 0; /* TRIES LOCK! IF I CAN GRAB IT, I AM DONE, RETURN */ if (unlikely(!raw_spin_trylock(&busiest->lock))) { /* IF I CANNOT, THEN MAKE SURE I GRAB THE LOCK IN THE RIGHT ORDER */ if (busiest < this_rq) { /* if I am grabbing a lower CPU lock, release my lock and then grab */ raw_spin_unlock(&this_rq->lock); raw_spin_lock(&busiest->lock); raw_spin_lock_nested(&this_rq->lock, SINGLE_DEPTH_NESTING); ret = 1; } else /* otherwise, grab it right away */ raw_spin_lock_nested(&busiest->lock, SINGLE_DEPTH_NESTING); } return ret; }where basically we wan to:
- make sure locks of CPUs are in the SAME ORDER (i.e. lowest CPU -> highest CPU)
- this is abstract enough so that other code can also use it
Note
- However, this does not re-check the state of run queue when the lock is released
-
Week 7 - Memory Management
Reminder
- There are two addresses, physical addresses (RAM) and virtual/logical addresses
- Therefore, in the end there is a mapping from the physical to the virtual/logical
- Processes have their own independent (virtual) address spaces
- by default, you are using the virtual addresses
- though there is a way to code to the physical addresses (HW1)
We are using virtual addresses due the following advantages
- don’t need to worry about addresses used by other processes
How do you map the addresses?
Heuristics
- At Compile Time, using compilers. Compiler needs to know ahead of time and map everything correctly
- not a good idea since not all programs will run in the end
- you still need to keep in mind of other programs while writing your own code
- At Load Time, when I actually load the program into RAM.
- this is a better approach, as it solves the previous problems
- to do this, you can do:
- just keep track of the
baseaddress, which will be added to the start of the virtual address of the loaded program, and then update thebase- however, since
stackandheapare dynamic, how would you deal with that?
The solution is to do it during execution time
- when a process is actually running, we map the address to the physical memory while it is running
- however, this needs some special hardware support
Memory Mapping
So, this mapping happens at execution time, and the following happens:
- CPU runs your program, and gets an address (that you need to use)
- You need to map that address to a physical address
General Idea
To do the mapping, a simple idea would be from the load time idea
where:
- we want to keep a sort of
base addressin arelocationregister
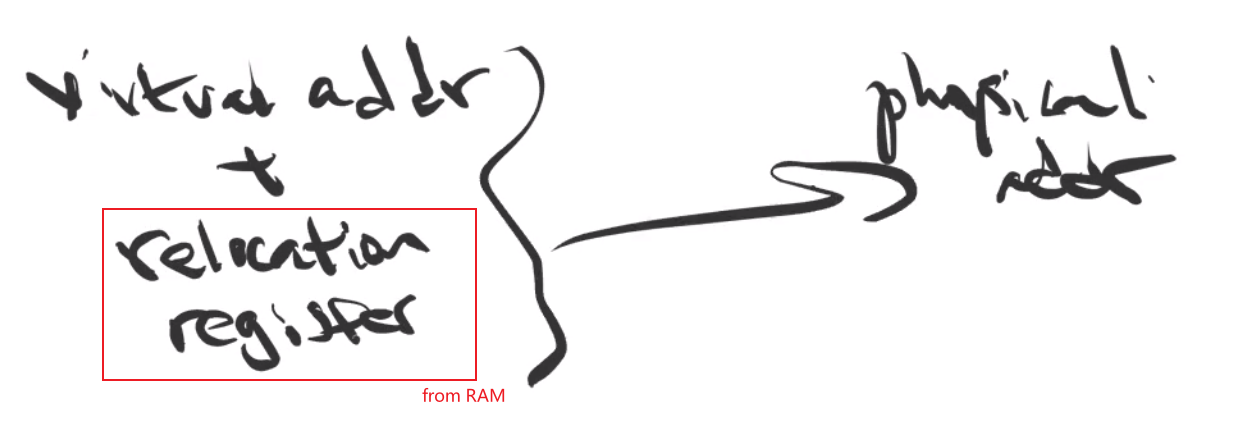
In reality, there is a page table:
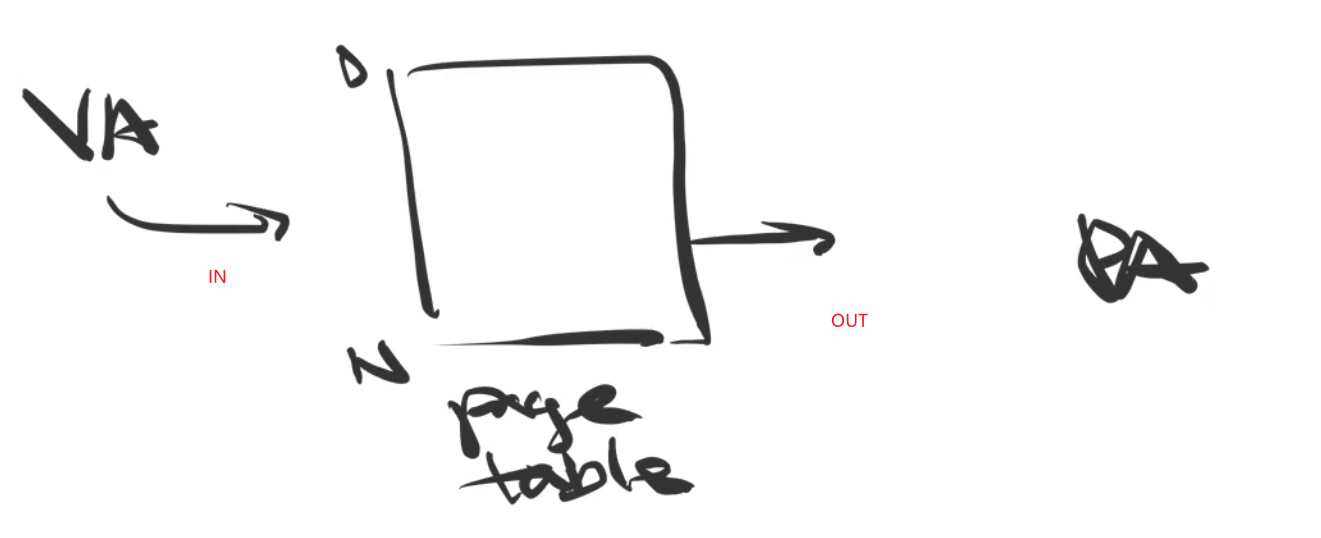
This is actually done in hardware.
- You execute instructions such as
load - CPU processes the instruction by looking up/index into the Page Table
- this Page Table will be stored in hardware
- The Page Table then tells us the physical address
- Then this is finally used
Reminder:
Some basic conversions:
- If Logical Address = 31 bit, then Logical Address Space = 231 words = 2G words (1 G = $2^{30}$)
- If Logical Address Space = 128 M words = $2^7 * 2^{20}$ words, then Logical Address = $log_2(2^{27})$ = 27 bits
Page Table
Since we essentially need to index the virtual address to get a physical address, we need away to TODO?
The virtual address will be split into two parts, page number and offset:
where:
- a
Pageis usually a fixed size (e.g.2^10) of memory- the physical memory will be broken up to
#pagenumber of pages
- in reality, you refer to the
#pageas the#framefor physical address- in reality, you refer to the
#pageas the#pagefor virtual address- usually the
pageandframesize is the same
- so it is just the problem of which
#pagemaps to which#frame- an
offsetis just an offsetThen the actual computation/mapping is this:
- use
#page(top bits of virtual address) to index into Page Table and get the#frame- the
#framewill be the top bits of the physical address- add the
offsetto the#frameto get the actual physical addressAnd since we need to essential solve the problem of two virtual address mapping to different physical address, we have:
- each process has its own DISTINCT page table, so that they are mapped to different areas of RAM
- here, you see the role of the OS
- so at context switches, the
PTBR(CR3inx86) register needs to be re-loaded as well
- so if you are switching to shared
threadsfor shared data, you won’t need to re-load the page table because it is the same for them
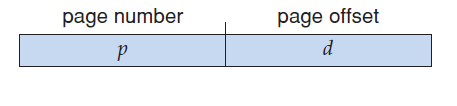
Then, the question remains: who controls the contents of the Page Table?
- the OS puts/loads mapping into the page table (decides)
- the Hardware will use the page table and translate addresses for you (translates)
So a full picture looks like:
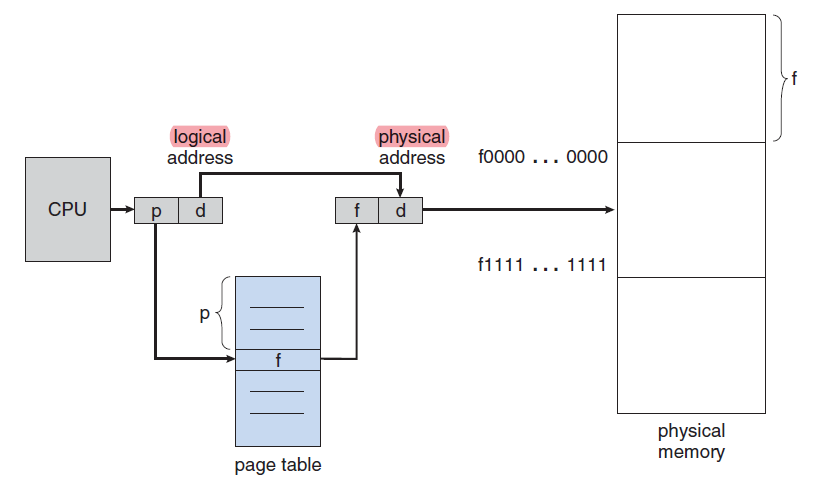
Note
- in the end, the hardware will have a address in
pagetable base register(``PTBR/CR3inx86`)- the OS will load data into that
pagetable- the hardware then will use that address in
pagetable base register
For Example:
Consider the setup:
- logical address with page number of
2 bitsand page offset of2 bits- so the number of entries in a page is $2^2 = 4$
- if each page entry is $1$ byte (size of data contained in each entry of page table)
- the page size is $4*1=4$ bytes
- physical address with total memory of
32 bytes- so the physical address has $log_2 32 = 5$ bits
- since frame size = page size, we have $32/4=8$ frames, which translates to $log_2 8 = 3$ bits for frame number, so $5-3=2$ bits for frame offset
Then the mapping looks like this:
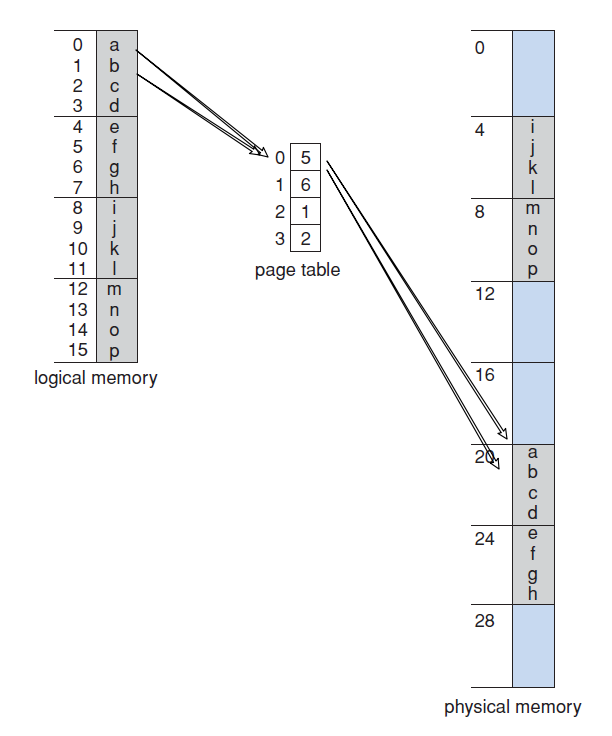
where:
- the virtual address
00 00maps to physical address of 101 00, where a is stored- first, page number $00$ is indexed into page table to get $5 = 101$
- the page offset is $00$
- then, the physical address is assembled $101\,\,00$
- the virtual address
00 01maps to physical address of101 01, where $b$ is stored - etc.
For Example
Consider:
- Page size = 8KB = $2^{13}$ B
- size of a page, not size of page table, two different things.
- Virtual address space size = $2^{46}$ B
- PTE (page table entry) = 4B = $2^2$ B
Then, we can get:
-
Number of pages or number of entries in page table, = (virtual address space size) / (page size) = 2^46 B/2^13 B = 2^33which means that
- we need $2^{33}$ pages,
- or it means we need to be able to index $2^{33}$ different pages, hence we will have $2^{33}$ entries in (a single level) page table
Now, we can also calculate the size of page TABLE:
-
= (number of entries in page table)*(size of PTE) = 2^33 * 2^2 B = 2^35 B
which looks obvious
Now, notice that:
- we have size of page table > page size! This is not ideal.
- hence, we need multilevel paging
Note
this also means that you could map a larger virtual space to a smaller physical space
- in this case, you would need to deal with collisions
- so basically, the concept is the same as the caches in the FUNDI class
for example, typically in modern systems, we have
64bits system (which is big, so usually only 48 bits -> $2^{48}=256 TB$ of space)
however, remember, not all addresses is used in a virtual address space:
where there is a big hole between heap and stack
- this is solved by further breaking up the addresses into a multilevel page table
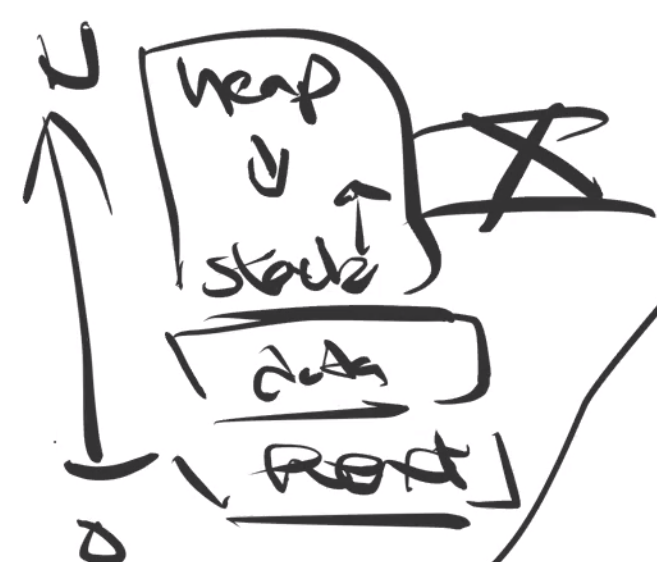
Multilevel Page Table
Multilevel Page Table
the core principle is to keep:
\[\text{size of page table } \le \text{size of page}\]In the end, if we use multilevel page table:
- only one of PAGE TABLE would be in your RAM at a time. If you have indexed and needed the next Page Table, the next one then is loaded in replacement
- this is obviously the advantage of Multi-level Paging
- this would be slow for software to do this. But hardware (Cache/TLB) has support so that memory access will be usually fast
Now, consider the following setup:
- a page size of
4KB= $2^{12}$ bytes - a page entry of
8B= $2^3$ bytes- contains the frame number (e.g. for the next level), and some extra flag information
- a virtual address space of $2^{64}$ bytes
- i.e. 64-bit system
- we need a two level paging

To solve this, always keep this in mind
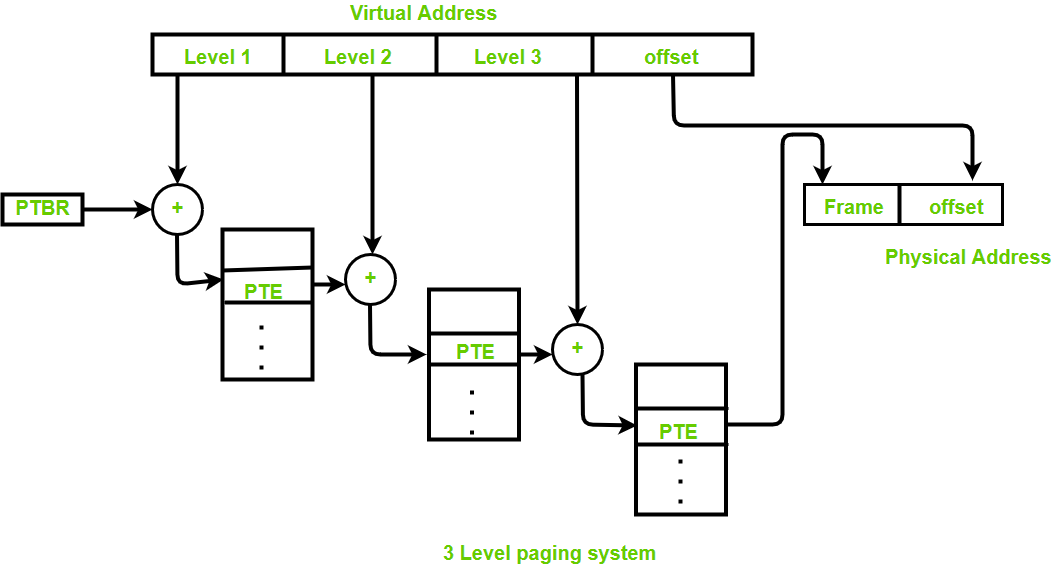
-
first, consider the offset. Basically, at the very last, we need the offset to get the entry of a PAGE, which would be the final place to PUT THE BYTE DATA. Therefore:
- since a page has size of $2^{12}$ bytes, we would need $12$ bits to identify each byte
- hence the offset is $12$ bit
-
then, the second last level. We need to achieve two things:
- the size of the page table needs to be $\le$ size of a page. Hence let us pick size of page table = $2^{12}$ = size of a page
- now, the idea is that each entry in this level page table tells us which (next level) PAGE we need to look at
- think of this level telling us which page to go to, and the offset level tells us which line on this page to go to (like a book)
- now, since size of page table here is $2^{12}$, and a page entry size is mentioned in the prompt ($2^3$), we have $2^{12} / 2^3 = 2^9$ entries. Hence we need $9$ bits to identify each entry
-
Now, we are basically done. We just have $64 - 9 - 12 = 43$ bits left. Check to see if this makes sense:
-
if we have $43$ bits left in in this level, and each page table entry is $2^3$, then we have $2^{46}$ bytes as the size of page table
- hints at the fact that Linux uses more than 2 level of paging (in fact, Linux uses 5 levels)
-
but working from this level (first level paging), we get this:
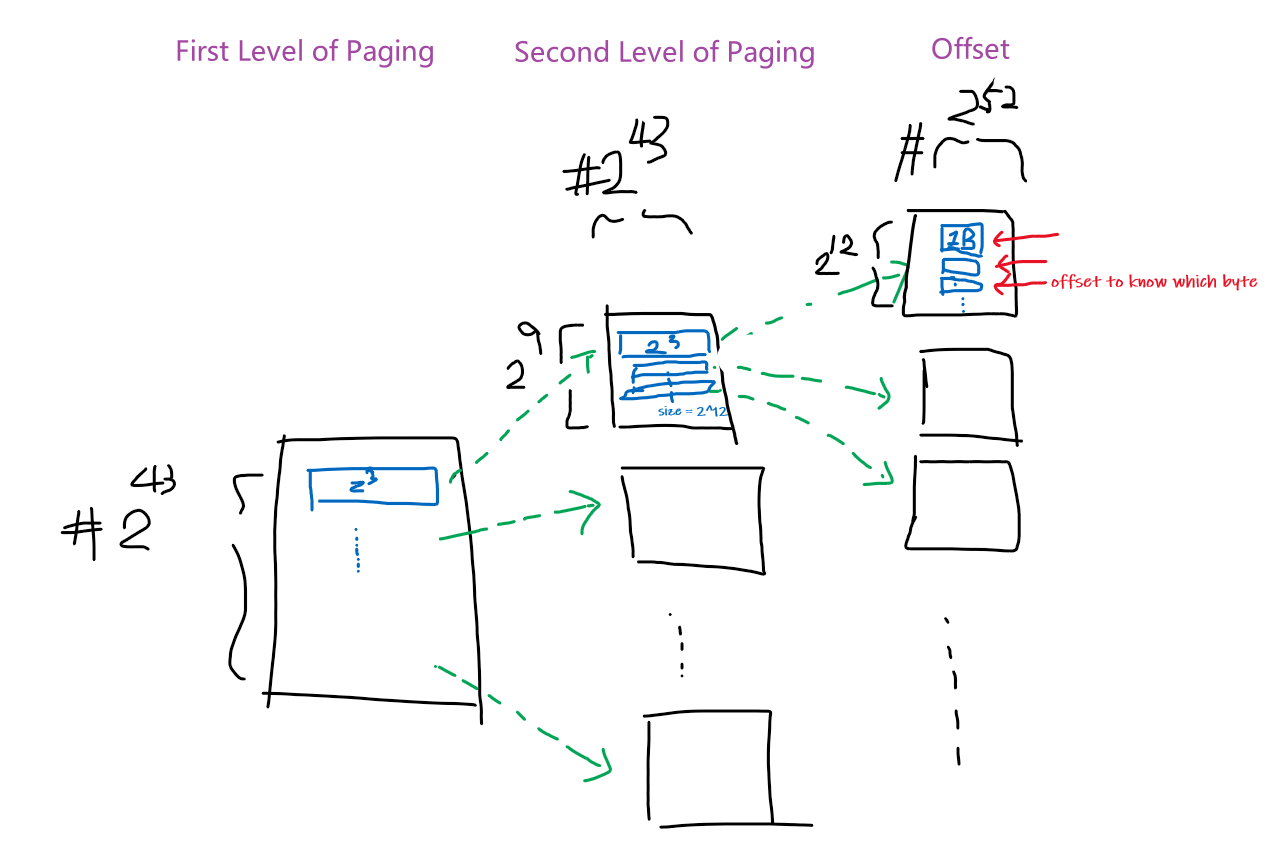
where:
- first, we use $43$ bits to index and get an entry of the first level page table.
- This would contain a frame number, call it $f_1=3$
- use the frame number $f_1$ to know which second level page table to look at. So we are looking at the $f_1=3$-rd second level page table
- then, we use $9$ bits to index and get an entry of the second level page table
- This would contain a frame number, call it $f_2=10$
- use the frame number $f_2$ to know which (last level) PAGE to look at. So we are looking at the $f_2=10$-th page
- finally, we use $12$ bits to index and get the byte stored at that page
Notice that we in the end have covered a total of $43+9+12 = 64$ possible combinations. Hence this is a 64-bit system, as expected
- first, we use $43$ bits to index and get an entry of the first level page table.
-
Potential Problem
- As Linux is having 5 levels of paging, this means you need to index 5 times to get to the actual place. This might make memory access slow and inefficient
- to solve this, we use caching, which is based on the principle of (space and time) locality
- in reality, this works pretty well/most things goes in cache (possibly even higher than $95\%$ hit rate)
Cache/TLB
Now, to solve the above problem, I can cache my most recent virtual address -> physical address translation
- otherwise, I would need to look at the actual page tables
- this cache is known as the translation lookaside buffer (TLB)
Cache
- Cache is also known as static RAM, or SRAM, which is faster than the usual RAM, which is technically called dynamic RAM, or DRAM
- Since Cache is usually small in storage size but FAST, the following happens:
- first, the CPU asks the cache if it has the translation for a virtual address
- if not, CPU then redo the indexing in DRAM and finds the address
- All of the above is done in hardware
For Example
Consider a setup of:
- 2 level of paging
- DRAM access time of 100 ns
- SRAM access time of 10 ns
- $99\%$ cache hit rate
Then we have the long term memory access time of:
\[0.99(10+100) + 0.01(10+100+100+100)=112ns\]where:
- the $10+100$ comes from a hit in cache (10) (got the address), and then accessing the address (100)
- the $10+100+100+100$ comes from a miss in cache (10), and then indexing twice to get the Page (100+100), and finally accessing the address (100)
Flushing TLB
Now, suppose process $A$ has a virtual address $0x5$, and then process $B$ gets context switched in. Then, you need to flush the TLB
- all the old entries are invalid since the cached address is per process
if we are switching between threads, which shares the same address space, then we don’t need to flush
- However, this can be optimized using tagging
Or, consider when we are updating the Page Table
- then we would need to flush for updates since the mapping is no longer valid
TLB Optimization
Tagging
- basically, we have an address space identifier $ASID$ to identity each TLB entry to a process
- so that we can save all the flushing and cache misses for context switches
- obviously, this would then help the performance
For Example
- if we have a process $A$ with $pid=1$, and process $B$ with $pid=5$
- process $A$ had a virtual address of $0x5$ translated to $0x9$
- this entry would have $ASID=pid=1$
- process $B$ had a virtual address of $0x5$ translated to $0x19$
- this entry would have $ASID=pid=5$
Note
- now, we only need to flush the TLB when we are updating the PAGE TABLE
- this would mean that we need to increase the TLB sizes (for $ASID$)
Accessing Memory
For a user, we use the memory by:
malloc()mmap()
Malloc
What happens when a user in his/her program does malloc()?
malloceventually goes tosbrkin the system call, which would:- increases your Heap by moving up the pointer if needed (because
free()actually does not decrease the Heap)- so
malloc()will first see if there are some spaces in your Heap left. If not, increases the space.
- so
- done
- increases your Heap by moving up the pointer if needed (because
- all it says is that “you can use more virtual addresses”. It does not actually assign any physical memory to you
- there will not be a place in your Page Table that translates these virtual address
- only at the point when you are storing data, they physical memory is assigned
- but first, a page fault will happen (see below)
Page Fault and Memory Access
now, consider if you did:
x = malloc(...); /* e.g. address 0x10 */ y = *x;then,t the following would happen:
mallocdoes not actually assign you physical address, i.e. there is no entry for that address $0x10$ in page table- the hardware will get page fault while trying to translate the address $0x10$
- the OS traps the exception, looks at it, and realizes that $0x10$ is valid for you to use (you have
malloced), so it now assigns you the physical address by adding entry in page table:
- this means that the OS assigns you physical address on the fly
- restart the instruction
- then everything would work
Read Fault and Write Fault
Basically when a memory is already given to you by
malloc(), it is not yet created physically, so it would have no page table entries
then, attempting to write into it would generate a write fault, after which you will have data actually written and protection bits looking like
young (access) bit dirty bit write bit user bit 1 1 1 1 or, if you attempted to read, it will generate a read fault, and the page table entries will also be initialized and you would have:
young (access) bit dirty bit write bit user bit 1 0 1 1
Mmap
mmap again allocates virtual address space, but you have more controls
- e.g. you can control at what (range of)
addressof the virtual memory you will be given - e.g. you can specify permissions, such as read-only
PRUT_READ - e.g. what type of memory you are given, such as the normal memory
MAP_ANONUMOUS, or an actual file
Note
- this means that your Heap does not grow contiguously
- this would be useful when you need some precise control on what memory address you get
Kernel Space Memory
The story is a little bit different in kernel memory than dealing with user space memory
- since physical memories are already mapped in for kernel,
kmalloc()actually gives you physical memory- as compared to the user space, where addresses are not backed with physical memory at first
Similar to user space, we are:
- allocating/using kernel space memory in terms of a page/frame. Additionally, the kernel is/should be able to allocate physically contiguous memories.
- one need for this would be doing large amount of
I/Owhere DMA/Direct Memory Access is used, so that the device can store/pullI/Odata in a large amount at once without going to the CPU each time - in general, the kernel does this by trying to save large areas of memory to be free (i.e. if you needed it later), by giving you the smallest area of memory that fits your need
- one need for this would be doing large amount of
Buddy Algorithm
This is the algorithm for kernel to achieve that large areas of memory are saved for future uses
Buddy Algorithm
TODO
- split into pieces and gives you the smallest amount
- buddy algorithm will keep track of the spitted, free memory, each chunk being $2^n$, for $n$ being the order
- e.g. $2^0=1$ means allocation of one page of memory
- a
- when you allocate and free, the memory with its order will be updated
- when it is possible to merge some unused areas, the kernel will do so by:
- merge the area
- put the area back to the correct order

Now, besides allocating space in kernel space, you might want to deal with the case that
- sometimes, you don’t need a
pagesize of space. For example, you might just need one byte. - this is optimized by a page cache, which basically stores some (partially) free pages for use later
Slab
Slab in Page Cache
- There is a slab allocator for the page cache
- A slab is a contiguous region of physical memory given from the buddy allocator to the page cache
- then, in the end, instead of going every time to construct a page, you just need to ask the slab allocator if there is some
pageleft in the slab for use.
- in general, this would be more efficient due to the overhead of doing the walk every time
Page Replacement
This is something that occurs when the system has low memory, so that it wants to reclaim memory
- it needs to decide which already using
pageto free (needs an algorithm) - writing those data to disk (i.e. we are swapping to disk)
- free the page/frame
- assign it to the new process
Alike scheduling algorithm, there are many possible solutions:
- FIFO - replacing the first memory allocated
- LRU
- LRU Approximation
In kernel
- the entire page replacement job is done by the process
kswapd
- periodically woken up when a zone of memory drops below the watermark/threshold
- then does the page replacement when needed
FIFO
Consider the case that we have

where:
1Fmeans accessing1, and having aPage_Fault
Belady’s Anomaly
- with certain algorithm, if you increase the amount of memory, you increase the amount of Page Faults
- this basically says that those algorithms are bad algorithms
Furthest In the Future
Best Algorithm
- cannot perform better than this
- but we do not know the future

where notice that we no longer has Belady’s Anomaly.
Therefore, instead, we should try:
- look in the past, and replace the furthest in the past, i.e. least recently used
Least Recently Used
This is basically based on the idea of furthest in the future

where:
- there is no Belady’s Anomaly
- this is not commonly used even though it is good. Because we essentially need to store what has been accessed, which is some big overhead
In General
- the behavior that is the same across algorithms is: when the memory of goes low, this will cause many page faults
LRU Approximation
We can’t keep track of all the information, e.g. a timestamp, there will be an access bit
- goes from $0 \to 1$ if it is accessed, and the hardware will set the bit
Then the algorithm is called the second chance. If you needed some memory replacement, you would loop over the pages and:
- see if accessed (i.e.
accessbit = 1),- if yes, clear the bit
- else, (i.e. the access bit for a memory is not set) replace this page
Note
- this means only
1bit of information. However, this can be improved if we in the OS, store the last access bit
- then we now have a
2bit information

Thrashing
As a result, we see that low memory -> memory replacement -> page faults.
Thrashing
- processes spend more time doing page faulting (e.g. due to page replacement) than executing programs.
- the result is to hear your disks spinning very fast
The main solution is to reduced the number of processes:
- swap the entire process with its memory out to disk (i.e. that process is consuming much memory)
- kill processes
To know which process to kill/swap:
Working Set
- Measure of how much memory a process needs.
- Some approximation/calculation of it would be:
- using page fault rate
Improve Page Performance
Increase Page Performance
- increase page size - larger page given to you when you have a page fault (so overhead of doing page faults are lower)
- using
huge_page- downside is that you might just waste those space => causing more page replacement -> page faults
- pre-paging - doing page faults ahead of time, so that when you actually need it, no overhead
- rather than getting the memory on demand
- downside is that
- same phenomena of wasting those space
- if your
I/Obandwidth is limited, then pre-paging/fetching data from RAM = causesI/Ousage could limitI/Oof other processes- program structure
- see below, basically could affect cache misses
For Example: Program Structure
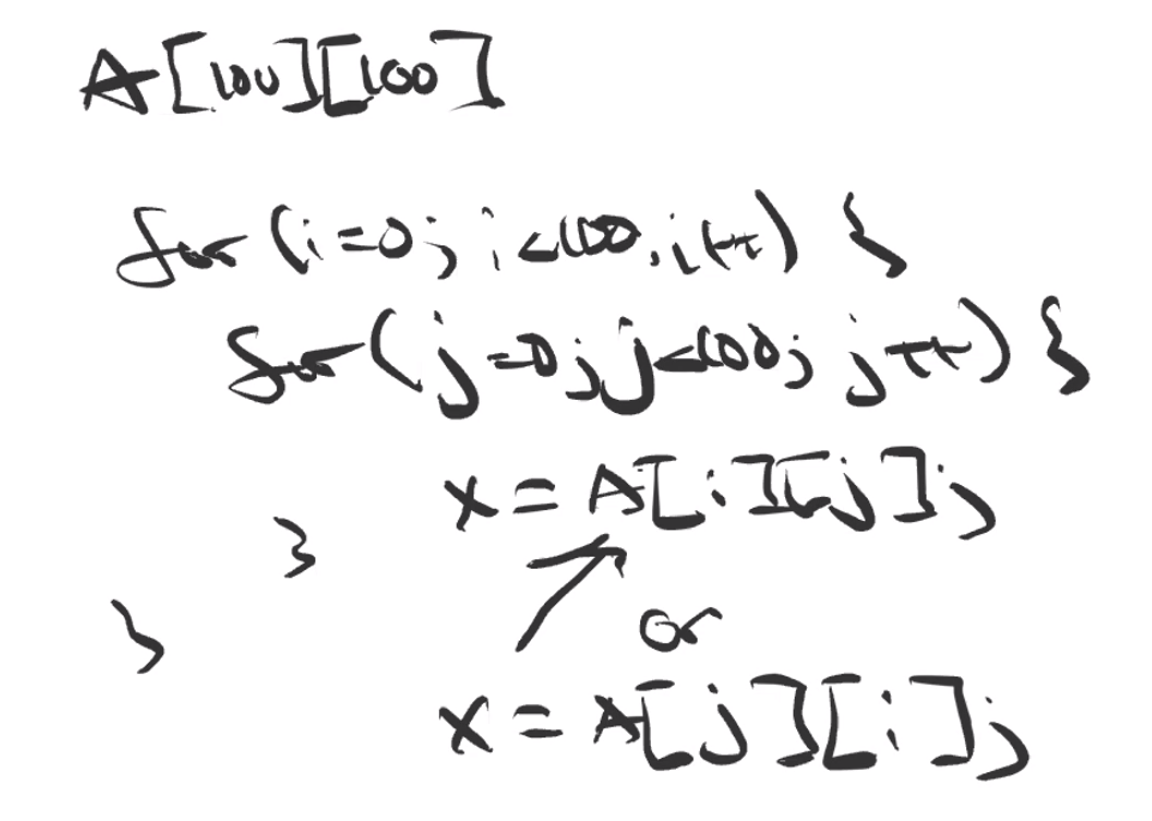
where the number needs of accessing different pages (could also increase page faults if limited memory left/cache miss) is different depending on:
- if the
A[0][0]’s address is right next toA[0][1]orA[1][0], i.e. whether they are one the same page
Actual Linux Implementation
Linux Memory Management
In short, everything will be in /mm, and recall that:
-
inside
task_struct, we have:struct task_struct{ /* some code omitted here */ struct mm_struct *mm; struct mm_struct *active_mm; /* some code omitted here */ }
Some Really Useful Documents
- https://www.kernel.org/doc/gorman/html/understand/understand006.html
struct mm_struct
Inside include/linux/mm_types.h
struct mm_struct {
struct {
struct vm_area_struct *mmap; /* list of VMAs = VM Area; pointer to the first vm_area_struct */
/* each continguous address in use */
struct rb_root mm_rb; /* vma in rb-tree, for faster access */
/* some code omitted here */
pgd_t * pgd; /* base address of the highest level page table */
/* this will get linked to other levels such as p4d, pte, etc. */
}
}
where:
-
struct vm_area_struct *mmapis contiguous, so that-
every time you are mallocing, this would be likely the place where it increases
-
so we have the field
vm_startandvm_endstruct vm_area_struct { /* The first cache line has the info for VMA tree walking. */ unsigned long vm_start; /* Our start address within vm_mm. */ unsigned long vm_end; /* The first byte after our end address within vm_mm. */ pgprot_t vm_page_prot; /* Access permissions of this VMA. */ unsigned long vm_flags; /* e.g. mmap specifies read-only */ /* some code omitted here */ }in fact, the kernel also does some optimization of merging neighboring, contiguous
vm_areas- note that the
unsigned long vm_flagandpgprot_t vm_page_prottells you permissions
- note that the
-
Note
recall that the virtual address space also contains the kernel portion (shared among all processes). This means that the kernel itself is using the virtual address space, and has its own page table for accessing physical addresses
however, for modern
64bit systems (though only48bits are used for most systems), we have around256TBof virtual memory, and that:
- half of it
128TBis given to kernel- other half to user
Therefore, in the end, since your RAM is most likely no
128TB, you will end up having all your RAM already mapped into the kernel’s virtual space
- therefore,
kmalloc()in kernel would actually assign you with physical addresses- the field
pgd_t * pgdis technically virtual address of kernel space, but its entry is always available in page table, mapping to a physical address
struct pgd_t
this is the field in mm_struct where you actually find the page tables
- first,
typedef struct { pgdval_t pgd; } pgd_t; - essentially, this is the address of the starting entry of a page table
Note
- since this is hardware dependent, we look at the
x86one inside the directory/arch/x86/include/asm/pgtable_types.h- the below is a structure of the entire, single page table
Reminder
the Main Memory is divided into parts called as ‘Frames’ and the process’s virtual memory is divided into ‘Pages’
A Page Table keeps track of the pages and where they are present in the Main Memory.
The pages can be present in any frame. The frames need not be contiguous.
Page Size = Frame Size.
and that the entry looks like:

/* basically, those are associated to the frame number of an entry */
#define _PAGE_BIT_PRESENT 0 /* if that page/frame of the entry is present */
#define _PAGE_BIT_RW 1 /* writeable */
#define _PAGE_BIT_USER 2 /* userspace addressable */
#define _PAGE_BIT_PWT 3 /* page write through */
#define _PAGE_BIT_PCD 4 /* page cache disabled */
#define _PAGE_BIT_ACCESSED 5 /* was accessed (raised by CPU) */
#define _PAGE_BIT_DIRTY 6 /* was written to (raised by CPU) */
Note
- essentially, the
permissionflags ofvm_area_structis independent of the permissions of the page table entry. So that you could have:
- a writable
vm_area_struct, so OS allows it (i.e. for virtual address space)- a not-writable
page_table_entry, so hardware will not write it (i.e. for physical address space)- then you will get a page fault
- those bits are essentially stored in the lower 12 bits of the
pteentry
- basically stored like a bit map, so that
000000000101means present and user accessible- makes sense since the page offset (in the frame/page) is
12bits
struct page
this is how the kernel mages the frame for each actual address
struct page {
unsigned long flags; /* Atomic flags, some possibly
* updated asynchronously */
/*
* Five words (20/40 bytes) are available in this union.
* WARNING: bit 0 of the first word is used for PageTail(). That
* means the other users of this union MUST NOT use the bit to
* avoid collision and false-positive PageTail().
*/
union {
struct { /* Page cache and anonymous pages */
/**
* @lru: Pageout list, eg. active_list protected by
* pgdat->lru_lock. Sometimes used as a generic list
* by the page owner.
*/
struct list_head lru;
/* See page-flags.h for PAGE_MAPPING_FLAGS */
struct address_space *mapping;
pgoff_t index; /* Our offset within mapping. */
/**
* @private: Mapping-private opaque data.
* Usually used for buffer_heads if PagePrivate.
* Used for swp_entry_t if PageSwapCache.
* Indicates order in the buddy system if PageBuddy.
*/
unsigned long private;
};
/* some code omitted here */
};
}
func do_page_fault()
when a page fault happens, it within instruction, namely, an exception/trap (instead of an interrupt)
-
similar to interrupt handlers, those traps also have handlers
idtentry page_fault do_page_fault has_error_code=1
then the do_page_fault does:
static noinline void
__do_page_fault(struct pt_regs *regs, unsigned long hw_error_code,
unsigned long address)
{
prefetchw(¤t->mm->mmap_sem);
if (unlikely(kmmio_fault(regs, address)))
return;
/* Was the fault on kernel-controlled part of the address space? */
if (unlikely(fault_in_kernel_space(address)))
do_kern_addr_fault(regs, hw_error_code, address);
else
do_user_addr_fault(regs, hw_error_code, address); /* most likely */
}
then the do_user_addr_fault(); knows:
- what is the error code
-
which address this is happening
-
and then does:
- gets the process that causes this
- does some checks and append a few flags to the error code based on what is done
- finds the
vm_areaassociated with that address- if no
vm_areareturns, then it means this address is not granted at all
- if no
- memory is valid, now check if we have some access errors
- e.g. trying to do a write, but
vm_areais not writable
- e.g. trying to do a write, but
- handles the fault with
handle_mm_fault()
/* Handle faults in the user portion of the address space */ static inline void do_user_addr_fault(struct pt_regs *regs, unsigned long hw_error_code, unsigned long address) { struct vm_area_struct *vma; struct task_struct *tsk; struct mm_struct *mm; vm_fault_t fault, major = 0; unsigned int flags = FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_KILLABLE; /* 1. gets the task of problem, and its memory space */ tsk = current; mm = tsk->mm; /* 2. does some checks and append a few flags to the error code */ if (hw_error_code & X86_PF_WRITE) flags |= FAULT_FLAG_WRITE; /* 3. finds the `vm_area` associated with that address */ vma = find_vma(mm, address); /* essentially traverses the rb-tree in logN */ /* 3.1 if this address is not *granted at all* */ if (unlikely(!vma)) { bad_area(regs, hw_error_code, address); return; } /* some code omitted here */ /* * Ok, we have a good vm_area for this memory access, so * we can handle it.. */ good_area: /* 4. memory is valid, now check if we have some access errors */ if (unlikely(access_error(hw_error_code, vma))) { bad_area_access_error(regs, hw_error_code, address, vma); return; } /* * If for any reason at all we couldn't handle the fault, * make sure we exit gracefully rather than endlessly redo * the fault. Since we never set FAULT_FLAG_RETRY_NOWAIT, if * we get VM_FAULT_RETRY back, the mmap_sem has been unlocked. * * Note that handle_userfault() may also release and reacquire mmap_sem * (and not return with VM_FAULT_RETRY), when returning to userland to * repeat the page fault later with a VM_FAULT_NOPAGE retval * (potentially after handling any pending signal during the return to * userland). The return to userland is identified whenever * FAULT_FLAG_USER|FAULT_FLAG_KILLABLE are both set in flags. */ /* 5. handles the fault with `handle_mm_fault()` */ fault = handle_mm_fault(vma, address, flags); major |= fault & VM_FAULT_MAJOR; /* some code omitted here */ }then the
handle_mm_fault()does:-
` __handle_mm_fault(vma, address, flags);`, which does:
- we have already get the error, and done some basic checks
- actually go to the
page_table_entryto see what has gone wrong, by walking through the multilevel page table- e.g. need physical memory assignment
- finally, when the walk is done, we do
handle_pte_fault()
/* * By the time we get here, we already hold the mm semaphore * * The mmap_sem may have been released depending on flags and our * return value. See filemap_fault() and __lock_page_or_retry(). */ static vm_fault_t __handle_mm_fault(struct vm_area_struct *vma, unsigned long address, unsigned int flags) { /* 1. has already done some checks, now want to check page table */ struct vm_fault vmf = { .vma = vma, .address = address & PAGE_MASK, .flags = flags, .pgoff = linear_page_index(vma, address), .gfp_mask = __get_fault_gfp_mask(vma), }; unsigned int dirty = flags & FAULT_FLAG_WRITE; struct mm_struct *mm = vma->vm_mm; pgd_t *pgd; p4d_t *p4d; vm_fault_t ret; /* 2. walk through the pgd and p4d */ pgd = pgd_offset(mm, address); /* indexes */ p4d = p4d_alloc(mm, pgd, address); /* 3. finally, when the *walk is done*, we do `handle_pte_fault()` */ return handle_pte_fault(&vmf); }where:
- the
pgd_offsetcomputes by:- taking the base address of the page table by
mm->pgd - adding the indexed address
pgd_index(address)+ base address, which gives you the actual address for the next page tablepgd_index(address)takes the top levels of the faulted address, and indexes into the page table
- taking the base address of the page table by
Note
- note that we are assuming that a semaphore is already grabbed. which will be typically used for memory accesses.
then, inside
handle_pte_fault()we do-
gets the
pteentry -
if the
pteentry is empty, namely no physical address assigned in the end- if the memory is anonymous, this means now the memory is
malloc()ed but not assigned actual physical page/address. then we dodo_anonymous_page() - a not-anonymous memory would be memories backed by a file
static vm_fault_t handle_pte_fault(struct vm_fault *vmf) { /* some code omitted here */ else { /* See comment in pte_alloc_one_map() */ if (pmd_devmap_trans_unstable(vmf->pmd)) return 0; /* * A regular pmd is established and it can't morph into a huge * pmd from under us anymore at this point because we hold the * mmap_sem read mode and khugepaged takes it in write mode. * So now it's safe to run pte_offset_map(). */ /* 1. gets the `pte` entry */ vmf->pte = pte_offset_map(vmf->pmd, vmf->address); vmf->orig_pte = *vmf->pte; /* * some architectures can have larger ptes than wordsize, * e.g.ppc44x-defconfig has CONFIG_PTE_64BIT=y and * CONFIG_32BIT=y, so READ_ONCE cannot guarantee atomic * accesses. The code below just needs a consistent view * for the ifs and we later double check anyway with the * ptl lock held. So here a barrier will do. */ barrier(); if (pte_none(vmf->orig_pte)) { pte_unmap(vmf->pte); vmf->pte = NULL; } } /* 2. if the `pte` entry is empty */ if (!vmf->pte) { if (vma_is_anonymous(vmf->vma)) return do_anonymous_page(vmf); else return do_fault(vmf); } }then, inside
do_anonymous_page()we have-
allocate a
page- Linux uses
struct pageto keep track of each frame of memory (smallest unit)
- Linux uses
-
make the
pteentry of the above createdpage-
now, the idea is to store the physical address of the
pageto apte, such that the hardware next time can translate and get the data. So we need to basically create something like:[frame_numer ..] | [physical address]so in code, it does:
#define mk_pte(page, pgprot) pfn_pte(page_to_pfn(page), (pgprot))
-
-
after that, you put the
pteentry into the page tablestatic vm_fault_t do_anonymous_page(struct vm_fault *vmf) { /* 1. allocate a `page` */ page = alloc_zeroed_user_highpage_movable(vma, vmf->address); /* 2. **make the `pte` entry** of the above *created* `page` */ entry = mk_pte(page, vma->vm_page_prot); if (vma->vm_flags & VM_WRITE) entry = pte_mkwrite(pte_mkdirty(entry)); setpte: /* 3. put the `pte` entry into the page table */ set_pte_at(vma->vm_mm, vmf->address, vmf->pte, entry); }
- if the memory is anonymous, this means now the memory is
Now, this example shows how Page_Fault due to missing pte works, There could be other cases where Page_Fault occurs
Access Error
Note
another case is for
access_error(), so that inside ` do_user_addr_fault` we checked:if (unlikely(access_error(hw_error_code, vma))) { bad_area_access_error(regs, hw_error_code, address, vma); return }then inside the
access_error(), it does:
if
vm_areais writable, but there ispteentry is write protected, return0= not access errorif (error_code & X86_PF_WRITE) { /* write, present and write, not present: */ if (unlikely(!(vma->vm_flags & VM_WRITE))) return 1; return 0; }
Reminder
in the section
funccopy_process(), we see that when we arecopy_process()a new process, we essentially copied over theptes but not the actualpage, and then made bothpteentries write protected.
this means that the
vm_areais writable, but thepteand its underlyingpageis write protectedin fact, the protection bit will look like this:
young (access) bit dirty bit write bit user bit 0 0/1 0 1 so that it’s cleaned in the sense of
write_bit/access_bitis set to 0
Now, if we have the above case, our code still goes to handle_pte_fault() eventually:
-
now it is the case of
vmf->flags & FAULT_FLAG_WRITE, we would like to actually copy over the underlyingpagesbydo_wp_page(vmf);static vm_fault_t handle_pte_fault(struct vm_fault *vmf) { /* some code omitted here */ if (vmf->flags & FAULT_FLAG_WRITE) { ret |= do_wp_page(vmf); if (ret & VM_FAULT_ERROR) ret &= VM_FAULT_ERROR; goto out; } }then inside
do_wp_page(vmf):- finally, does the copy via
wp_page_copy(vmf);
- finally, does the copy via
func copy_process()
Note
- this is used, for example, at the creation of a new process via
fork()->do_fork()->copy_process()
Reminder
- recall that the kernel also is a virtual memory space. The difference with a user’s process’s virtual memory space is that everything is already mapped to physical address for the kernel
Starting with kernl/fork.c, we have copy_process, which
-
does a bunch of initialization, including
copy_mm()static __latent_entropy struct task_struct *copy_process( struct pid *pid, int trace, int node, struct kernel_clone_args *args) { /* some code omitted here */ retval = copy_mm(clone_flags, p); if (retval) goto bad_fork_cleanup_signal; }then inside
copy_mm()-
check if it is shared
mmviaclone_flags -
if we want to create a new
mm, thendup_mm(tsk, current->mm)static int copy_mm(unsigned long clone_flags, struct task_struct *tsk) { /* 1. check if it is shared `mm` via `clone_flags` */ if (clone_flags & CLONE_VM) { mmget(oldmm); mm = oldmm; goto good_mm; } retval = -ENOMEM; /* 2. if we want to create a new `mm`, then `dup_mm(tsk, current->mm)` */ mm = dup_mm(tsk, current->mm); if (!mm) goto fail_nomem; good_mm: tsk->mm = mm; /* some code omitted here */ }then, inside
dup_mm(), we do:-
create a
mm_structviaallocate_mm -
copies all the
oldmminto this newmmcreated -
initializes the new memory struct
static struct mm_struct *dup_mm(struct task_struct *tsk, struct mm_struct *oldmm) { struct mm_struct *mm; int err; /* 1. *create* a `mm_struct` via `allocate_mm` */ mm = allocate_mm(); if (!mm) goto fail_nomem; /* 2. *copies all the* `oldmm` into this new `mm` created */ memcpy(mm, oldmm, sizeof(*mm)); /* 3. *initializes* the new memory struct */ if (!mm_init(mm, tsk, mm->user_ns)) goto fail_nomem; /* 4. does a `dup_mmap()`, which is covered below */ err = dup_mmap(mm, oldmm); if (err) goto free_pt; }then inside the
mm_init(), we do:-
a bunch of initializations
-
allocates a
pgdfor this newmm, including configuring the kernel portion of this new address spacestatic struct mm_struct *mm_init(struct mm_struct *mm, struct task_struct *p, struct user_namespace *user_ns) { /* some code omitted here */ /* 2. *allocates* a `pgd` for this new `mm` */ if (mm_alloc_pgd(mm)) goto fail_nopgd;then inside the
mm_alloc_pgd(), we dopgd_alloc(),-
which goes to
x86specific version, and does_pgd_alloc(), and finally_pgd_malloc()and gives one page of memory -
does a
pgd_ctor, which for page level $\ge 4$ (true), goes toclone_pgd_rangewhich copies:if (CONFIG_PGTABLE_LEVELS == 2 || (CONFIG_PGTABLE_LEVELS == 3 && SHARED_KERNEL_PMD) || CONFIG_PGTABLE_LEVELS >= 4) { clone_pgd_range(pgd + KERNEL_PGD_BOUNDARY, swapper_pg_dir + KERNEL_PGD_BOUNDARY, KERNEL_PGD_PTRS); }the aim of this is to configure the kernel portion of the page table of the process, (recall that the virtual address space has two parts, user’s stack/heap/etc, and kernel), by copying over all the page table entries which points to the kernel’s space.
The effect is that now it points to the kernel’s address space, and that this address will be the same for all other processes, making the
kernelportion being shared across processes.Note
- this explains better what happens when a system call of a user program happens. Essentially, we are still running in the user’s process’s address space, but that we are now using the kernel portion of it, which will point to the kernel’s
pteand code essentially
-
the new
mmspace frompgd + KERNEL_PGD_BOUNDARY#define KERNEL_PGD_BOUNDARY pgd_index(PAGE_OFFSET)basically
pgd_index(address)takes the top bits of the address, and indexes into the page table:- the
PAGE_OFFSETis the starting address of kernel space (e.g. it may start at128G) - indexes into the Page Table and find out the start of the kernel’s address space
- the
-
the old
mmspace is fromswapper_pg_dir + KERNEL_PGD_BOUNDARY- where
swapper_pg_diris the Page Tables of the initial page table of theinit_mm, which is themmof the first task - hence
swapper_pg_dir + KERNEL_PGD_BOUNDARYgives the kernel portion of the page table
- where
- this explains better what happens when a system call of a user program happens. Essentially, we are still running in the user’s process’s address space, but that we are now using the kernel portion of it, which will point to the kernel’s
-
-
-
does a
dup_mmap(), which does:-
a loop using the
old->mmap(i.e. iterates over itsvm_area_struct)- recall that
struct vm_area_struct *mmap;is pointer to the firstvm_area_structof amm
- recall that
-
and does a
copy_page_rangeof copy over the page table entries from the old one into the new one- so that its state is the same
static __latent_entropy int dup_mmap(struct mm_struct *mm, struct mm_struct *oldmm) { /* some code omitted here */ prev = NULL; /* 1. a loop using the `old->mmap` */ for (mpnt = oldmm->mmap; mpnt; mpnt = mpnt->vm_next) { struct file *file; if (mpnt->vm_flags & VM_DONTCOPY) { vm_stat_account(mm, mpnt->vm_flags, -vma_pages(mpnt)); continue; } charge = 0; /* some code omitted here */ /* 2. does a `copy_page_range` of copy over the *page table entries* */ if (!(tmp->vm_flags & VM_WIPEONFORK)) retval = copy_page_range(mm, oldmm, mpnt); } }the
copy_page_range()does:-
gets the pointer to the process’s first using page table entry in the
pgdviapgd_offset#define pgd_offset_pgd(pgd, address) (pgd + pgd_index((address)))which basically start with the address of first page table entry of the
pgd, and then add the offset ofpgd_index((address)to get the address of thataddress’s page table entry in thepgd -
do the same for getting the target
pdgaddress to copy to (i.e. the newly created process) -
loop over and
copy_p4d_range, which is the next level of the page tableint copy_page_range(struct mm_struct *dst_mm, struct mm_struct *src_mm, struct vm_area_struct *vma) { /* 2. do the same for getting the target `pdg` address to copy to */ dst_pgd = pgd_offset(dst_mm, addr); /* 1. gets the pointer to the *process's first using page table entry* */ src_pgd = pgd_offset(src_mm, addr); /* 3. loop over and `copy_p4d_range` */ do { next = pgd_addr_end(addr, end); /* computes the virtual addr correspond to the NEXT src_pgd */ if (pgd_none_or_clear_bad(src_pgd)) continue; if (unlikely(copy_p4d_range(dst_mm, src_mm, dst_pgd, src_pgd, vma, addr, next))) { ret = -ENOMEM; break; } } while (dst_pgd++, src_pgd++, addr = next, addr != end); /* some code omitted here */ return ret; }then the next thing is
copy_p4d_range(), which basically continues the same idea:- get the source
p4dand find out the address of the first using page table entry - for the destination
p4dof the new process, we now need to allocate new spaces
Reminder:
- we did not need to allocate the
pgdbefore. This is because thepgdis already allocated at creation of the process.
-
loop over all the
p4ds, and do the same for the next level,pudstatic inline int copy_p4d_range(struct mm_struct *dst_mm, struct mm_struct *src_mm, pgd_t *dst_pgd, pgd_t *src_pgd, struct vm_area_struct *vma, unsigned long addr, unsigned long end) { p4d_t *src_p4d, *dst_p4d; unsigned long next; /* 2. for the destination `p4d` of the new process, we now *need to allocate new spaces* */ dst_p4d = p4d_alloc(dst_mm, dst_pgd, addr); if (!dst_p4d) return -ENOMEM; src_p4d = p4d_offset(src_pgd, addr); /* 3. loop over all the `p4d`s, and do the same for the *next level*, `pud` */ do { next = p4d_addr_end(addr, end); if (p4d_none_or_clear_bad(src_p4d)) continue; if (copy_pud_range(dst_mm, src_mm, dst_p4d, src_p4d, vma, addr, next)) return -ENOMEM; } while (dst_p4d++, src_p4d++, addr = next, addr != end); return 0; }then this continues (essentially the same pattern) until
copy_pte_range(), which is the bottom level of the page table, which finallycopy_one_pte()for each:-
if it s a
cow_mapping, then give a write protect to bothpteentry we have just created and the one we are copying fromcowstands for copy on write
-
get the
pageof the source’s underlyingpte -
put the address of that
pageinto the targetpteviaset_pte_at-
#define set_pte_at(mm, addr, ptep, pte) native_set_pte_at(mm, addr, ptep, pte) static inline void native_set_pte(pte_t *ptep, pte_t pte) { WRITE_ONCE(*ptep, pte); }Note
- we see that we at the beginning are not copying the contents of the memory, but only copying the address of the
page, such that eventually the translation of an address of the new process will hit the same memory of the old process - however, since the
fork()ed process is independent of the parent, what happens is that only if one of the two processes are writing to the page table, we then copy the actualpageinstead of just the addresses- this is also why we have set the write protect to both pages in step 1
- the actual copying when a write error happened is explained in Access Error
Reminder
- the smallest unit for kernel to allocate new memory is a
page, i.e., when you domalloc(), you are basically creatingpages
- we see that we at the beginning are not copying the contents of the memory, but only copying the address of the
static inline unsigned long copy_one_pte(struct mm_struct *dst_mm, struct mm_struct *src_mm, pte_t *dst_pte, pte_t *src_pte, struct vm_area_struct *vma, unsigned long addr, int *rss) { /* 1. if it s a `cow_mapping`, then give a **write protect** to both `pte` entry */ if (is_cow_mapping(vm_flags) && pte_write(pte)) { ptep_set_wrprotect(src_mm, addr, src_pte); pte = pte_wrprotect(pte); } /* * If it's a shared mapping, mark it clean in * the child */ if (vm_flags & VM_SHARED) pte = pte_mkclean(pte); pte = pte_mkold(pte); /* 2. get the `page` of the source's underlying `pte` */ page = vm_normal_page(vma, addr, pte); if (page) { get_page(page); page_dup_rmap(page, false); rss[mm_counter(page)]++; } else if (pte_devmap(pte)) { page = pte_page(pte); } out_set_pte: /*3. put the *address of that `page`* into the **target** `pte` via `set_pte_at`*/ set_pte_at(dst_mm, addr, dst_pte, pte); return 0; } -
-
- get the source
-
-
-
func create_huge_pud()
Huge Page
- this is available on systems such as
x86, where instead of a regular page4K, you can have a2Mpage..- therefore, instead of
ptepointing to thepage, we have the upper levelpudpointing to the page
This is used in __handle_mm_fault
-
if we wanted to create a huge page, go to
create_huge_pmd()static vm_fault_t __handle_mm_fault(struct vm_area_struct *vma, unsigned long address, unsigned int flags) { /* some code omitted here */ if (pmd_none(*vmf.pmd) && __transparent_hugepage_enabled(vma)) { ret = create_huge_pmd(&vmf); if (!(ret & VM_FAULT_FALLBACK)) return ret; } }then
create_huge_pmddoes:- in the end does
do_huge_pmd_anonymous_page()and finally creates a new, huge page
- in the end does
Linux Page Replacement
Reminder
- the execution of the below would be done by the process
kswapd
Buddy Algorithm
In short, this is happening inside the call alloc_pages()->alloc_pages_current(gfp_mask, order)
Reminder
- one use case of this would stem from
do_anonymous_page(), which would be used when user needs some new physical memory allocated (after a page fault). Eventually, this function goes toalloc_pages()
- in fact, the above would go to
alloc_pages_current(gfp_mask, 0)with order of 0, meaning one page of allocation
Some concepts to know beforehand:
Memory Node and Zone
- some terms you will see are
NUMA, which means non-uniform memory access. This is the case for a large computer architecture, where there is some significant difference for a CPU to access a memory (close to it) and another memory (far away).
- then a
nodewhich represent memory in a particular region- within a
node, there arezonesof memory
- e.g. a zone could be the
DMA(forI/O).
Consider the function alloc_pages_current(), which eventually calls __alloc_pages_nodemask(), which does:
-
gets the page from the free list
struct page * __alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order, int preferred_nid, nodemask_t *nodemask) { struct page *page; unsigned int alloc_flags = ALLOC_WMARK_LOW; gfp_t alloc_mask; /* The gfp_t that was actually used for allocation */ struct alloc_context ac = { }; /* some code omitted here */ /* 1. gets the page *from the free list* */ page = get_page_from_freelist(alloc_mask, order, alloc_flags, &ac); if (likely(page)) goto out; }then inside the
get_page_from_freelist(), we do:-
actually getting the page via
rmqueue()/* * get_page_from_freelist goes through the zonelist trying to allocate * a page. */ static struct page * get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags, const struct alloc_context *ac) { /* 1. actually getting the page via `rmqueue()` */ if (likely(order == 0)) { page = rmqueue_pcplist(preferred_zone, zone, gfp_flags, migratetype, alloc_flags); goto out; } /* 2. if the order is not 0 */ do { /* some code omitted here */ if (!page) page = __rmqueue(zone, order, migratetype, alloc_flags); } while (page && check_new_pages(page, order)); }then in
rmqueue(), we do:-
if
order=0, i.e. we need 1 page, thenrmqueue_pcplist()/* * Allocate a page from the given zone. Use pcplists for order-0 allocations. */ static inline struct page *rmqueue(struct zone *preferred_zone, struct zone *zone, unsigned int order, gfp_t gfp_flags, unsigned int alloc_flags, int migratetype) { unsigned long flags; struct page *page; /* some code omitted here */ if (likely(order == 0)) { /* 1. if `order=0`, i.e. we need **1 page**, */ page = rmqueue_pcplist(preferred_zone, zone, gfp_flags, migratetype, alloc_flags); goto out; } }then in
rmqueue_pcplist(), which does__rmqueue_pcplist(), which then does:-
gets the page from a
list -
update the
pcpcount/number of available pages in that liststatic struct page *__rmqueue_pcplist(struct zone *zone, int migratetype, unsigned int alloc_flags, struct per_cpu_pages *pcp, struct list_head *list) { do { if (list_empty(list)) { /* some code omitted here */ } /* 1. gets the page from a `list` */ page = list_first_entry(list, struct page, lru); list_del(&page->lru); /* update the `pcp` count/number of available pages in that list */ pcp->count--; } while (check_new_pcp(page)); return page; }
/* * get_page_from_freelist goes through the zonelist trying to allocate * a page. */ static struct page * get_page_from_freelist(gfp_t gfp_mask, unsigned int order, int alloc_flags, const struct alloc_context *ac) { /* 1. actually getting the page via `rmqueue()` */ if (likely(order == 0)) { page = rmqueue_pcplist(preferred_zone, zone, gfp_flags, migratetype, alloc_flags); goto out; } /* 2. if the order is not 0 */ do { /* some code omitted here */ if (!page) page = __rmqueue(zone, order, migratetype, alloc_flags); } while (page && check_new_pages(page, order)); } -
-
if
orderis not0, then in the more general case, it calls__rm_queue(), which does a__rmqueue_smallest(), which then does:-
find the appropriate
zonein the memory to have this data stored -
start from the size of
current_order, and try to get apagethere- if not, it goes to the
next_orderof body list - note that you are just obtaining the first page of the contiguous pages. e.g. If you needed $2^2$ pages, then this would return you the first page of the four pages
- if not, it goes to the
-
once obtained the page, delete it from the list
/* * Go through the free lists for the given migratetype and remove * the smallest available page from the freelists */ static __always_inline struct page *__rmqueue_smallest(struct zone *zone, unsigned int order, int migratetype) { unsigned int current_order; struct free_area *area; struct page *page; /* 2. start from the size of `current_order`, and try to get a `page` there */ for (current_order = order; current_order < MAX_ORDER; ++current_order) { /* 1. find the appropriate `zone` in the memory to have this data stored */ area = &(zone->free_area[current_order]); page = get_page_from_free_area(area, migratetype); if (!page) continue; /* 3. once obtained the page, delete it from the list */ del_page_from_free_area(page, area); /* 4. afterwards, **expand/merge** the pages in the rest of the buddy list */ expand(zone, page, order, current_order, area, migratetype); set_pcppage_migratetype(page, migratetype); return page; } return NULL; }then inside
get_page_from_free_area(), we just have:-
get the
struct pagefrom the list (does notlist_del)static inline struct page *get_page_from_free_area(struct free_area *area, int migratetype) { return list_first_entry_or_null(&area->free_list[migratetype], struct page, lru); }
-
-
afterwards, expand/merge the pages in the rest of the buddy list
inside
expand(), we are doing:-
if
low=the #pages we needed $<$high=order of page in the region -
we want to merge the unused parts in this region back to other lists of smaller order
- e.g. if we needed
2^0, but we are at2^2, then 1 page of size=order=1 will be placed back, and 1 page of order=size 2 will be placed back
static inline void expand(struct zone *zone, struct page *page, int low, int high, struct free_area *area, int migratetype) { unsigned long size = 1 << high; /* 1. if `low`=the #pages we needed $<$ `high`=order of page in the region */ while (high > low) { area--; high--; size >>= 1; /* some code omitted here */ /* 2. we want to **merge the unused parts** in this region back to *other lists of smaller order* */ add_to_free_area(&page[size], area, migratetype); set_page_order(&page[size], high); } } - e.g. if we needed
-
-
-
-
translations between different structs
page_to_pfnThis is useful if we want to **translate from a page to a physical frame number **(there is also the reverse)page_to_physthis translates from a page to physical address (there is also the reverse)page_to_virtthis translates from a page to a virtual address (there is also the reverse)- for example, if you want to read the data in the actual page, you could first translate the page to virtual address, and then read it from the pointer
func dup_task_struct
This is used for illustrating the use of a slab allocator and a page cache in kernel, so that every time a new process is coming out, we would have the memory needed cached already
This example starts from dup_task_struct(), which goes alloc_task_struct_node(node)
-
which in turns goes to
kmem_cache_alloc_node();, which is going to get the memory of sizestruct task_structfrom cache,-
which then goes to:
kmem_cache_alloc(s, flags);-
which then goes to
slab_alloc()-
which then essentially does
objp = __do_cache_alloc(cachep, flags);-
which does
____cache_alloc(cache, flags);-
gets the
array_cachewhich represents an array of cachesstruct array_cache { unsigned int avail; /* NUMBER of available units/entries */ unsigned int limit; unsigned int batchcount; unsigned int touched; void *entry[]; }; -
check if there it is available = has at least one not used unit inside
-
if yes, gets that memory, decrease the
avail, and done -
if not, I need to refill the cache with memory by
cache_alloc_refill()static inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags) { void *objp; struct array_cache *ac; check_irq_off(); /* 1. gets the `array_cache` */ ac = cpu_cache_get(cachep); /* 2. check if there it is available = has at least one not used unit inside */ if (likely(ac->avail)) { ac->touched = 1; /* 3. if yes, gets that memory, decrease the `avail`, and done */ objp = ac->entry[--ac->avail]; STATS_INC_ALLOCHIT(cachep); goto out; } /* 4. if not, I need to *refill the cache with memory* by `cache_alloc_refill()` */ objp = cache_alloc_refill(cachep, flags); /* some code omitted here */ return objp; }then in
cache_alloc_refill(), which goes tocahce_grow_begin(), which then goes to:kmem_getpages(), which finally goes to__alloc_pages_node()which does__alloc_pages(), back to the path of actually allocating pages in the buddy allocator
-
-
-
-
-
Note
- if you free, then it will just put the memory back to the slab, and then increment the
avail
func __do_kmalloc
This is the path eventually from calling kmalloc(), which you will soon see that it also uses the page cache and the slab allocator
Starting with __do_kmalloc(), it goes to:
-
kmalloc_slab(), which gets thekmalloc_caches -
then, we use the
cacheand callslab_alloc()static __always_inline void *__do_kmalloc(size_t size, gfp_t flags, unsigned long caller) { struct kmem_cache *cachep; void *ret; /* 1. `kmalloc_slab()`, which *gets the `kmalloc_caches`* */ cachep = kmalloc_slab(size, flags); if (unlikely(ZERO_OR_NULL_PTR(cachep))) return cachep; /* 2. use the `cache` and call `slab_alloc()` */ ret = slab_alloc(cachep, flags, caller); /* some code omitted here */ return ret; }then,
slab_alloc()calls:-
__do_cache_alloc(), which then calls-
___cache_alloc(), which is the same as above, where it:-
checks if there is some available memory in the cache
-
if yes, gives you that and decrease
availstatic inline void *____cache_alloc(struct kmem_cache *cachep, gfp_t flags) { void *objp; struct array_cache *ac; ac = cpu_cache_get(cachep); /* 1. checks */ if (likely(ac->avail)) { ac->touched = 1; /* 2. gets the cached memory */ objp = ac->entry[--ac->avail]; STATS_INC_ALLOCHIT(cachep); goto out; } /* some code omitted here */ }
-
-
-
Week 8 - 10 - File System
Basically file is an abstraction of a persistent, non-volatile storage of information
- the opposite would be processes. which are gone when powered off
Some file systems FS include:
- Disk Based FS
- persists even when you reboot
- needs to deal with both in-memory representation and disk representation. Because when you use it, it first gets loaded into memory, and when you write to it, it first write to memory and then writes/syncs to the disk
- In-Memory FS
- when you power off, they are gone.
- e.g. for some system
/tmp
Virtual File System
Some Useful References:
- https://www.kernel.org/doc/html/latest/filesystems/index.html
To support all the different file systems, there is a common abstraction called the virtual file system
- i.e. provides API for different implementations of FS
Note
- in a sense, this will be similar to the Linux scheduler, in the sense that:
- when you call a generic
read(), it will go tovsf_read(), which then calls the file system specificread()- just like scheduler calling the scheduling class specific
pick_next_task()
This section therefore talks about:
read()write()open()close()mount()- mounting File System for a directory of files
Objects in VFS
Below are some main objects that Linux keeps track of.
- Super Block - metadata/info for a mounted file system
- i.e. all file systems will have a super block
- both in memory and also has a Disk Version
- inode - index node, metadata for an actual file
- both in-memory and also has a Disk Version
- file struct - interaction of a process with an opened file
- i.e. the
FILE *that you see in C, or basically file descriptors - no Disk Version, only represented in memory
- i.e. the
- d-entry - directory entry linked between a file name and a
inode- e.g. file name could be
hello/foo.txt, and if you have made somelinksin your FS, then you will have two different file name, but pointing to the sameinode - this is typically cached, as directory navigation happens often
dentryis are all components in a path, including files.- e.g.
/bin/vihasdentryobject of/,bin, andvi, even ifviis a regular file
- e.g.
- e.g. file name could be
Similarly, a process keeps track of:
- file table - an array of file descriptors/
fdarray- from that
fd, you will have the file object -> d-entry -> inode & super block and actually access your file data & fie system related info
- from that
Relationship between
superblock/inode/dentry
superblockcontains information on which validinodes we are using- each
inodecontains data for a specific file/directory
- for example, stored in the inode are the attributes of the file or directory: permissions, owner, group, size, access/modify times, etc.
- VFS often needs to perform directory-specific operations, such as path name lookup. Path name lookup involves translating each component of a path, including the file
- for example.
/bin/vi, whereviis the file, then you need to first perform a pathname look up- therefore, this is the use of a
dentryobject,dentryis a specific component in a path. Using the previous example,/,bin, andviare alldentryobjects.
Note
- the actual implementation of the above is in the directory
/fsin kernel code
Zero Page
If you need the returned page filled with zeros, use the function:
unsigned long get_zeroed_page(unsigned int gfp_mask)
This function works the same as __get_free_page(), except that:
- the allocated page is then zero-filled—every bit of every byte is unset.
Note
- This is useful for pages given to userspace because the random garbage in an allocated page is not so random; it might contain sensitive data. All data must be zeroed or otherwise cleaned before it is returned to userspace to ensure system security is not compromised.
Disk and Disk I/O
On a large picture, we are dealing with:
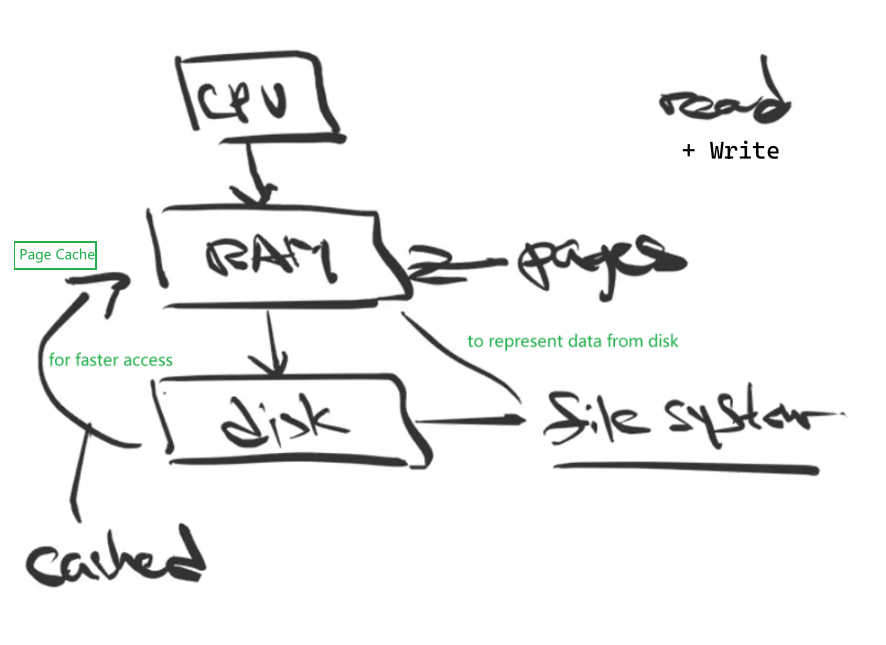
where:
-
CPU gets data from RAM, which is stored in terms of frames/pages
- if we want to do a
read()from disk, it will first look at the Page Cache in RAM (because access from disk is slow) - when we do a
write()to disk, it will also write to Page Cache in RAM, and some time later, writes are sent to disk together
Note
since we are writing to Page Cache before actually to disk, this means that abnormally shutting your system down could lead to some data missing because they are not yet flushed to disk from RAM
Therefore, there are usually system threads that periodically do those flushes. So if you do a proper shutdown, those threads would be waken up and flush things to disk.
In fact:
unsigned int dirty_writeback_interval = 5 * 100; /* centiseconds */which mean basically every 5 seconds, and that:
int dirty_writeback_centisecs_handler(struct ctl_table *table, int write, void __user *buffer, size_t *length, loff_t *ppos) { unsigned int old_interval = dirty_writeback_interval; int ret; ret = proc_dointvec(table, write, buffer, length, ppos); /* * Writing 0 to dirty_writeback_interval will disable periodic writeback * and a different non-zero value will wakeup the writeback threads. * wb_wakeup_delayed() would be more appropriate, but it's a pain to * iterate over all bdis and wbs. * The reason we do this is to make the change take effect immediately. */ if (!ret && write && dirty_writeback_interval && dirty_writeback_interval != old_interval) wakeup_flusher_threads(WB_REASON_PERIODIC); return ret; }
Hard Disk Mechanics
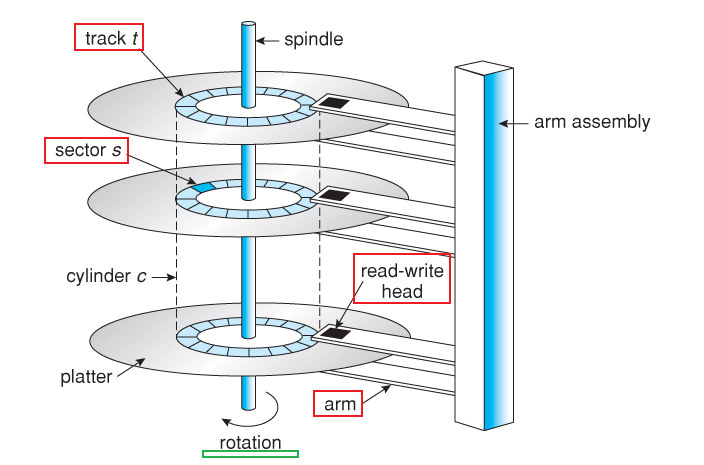
where some components include:
- a disk arm that slides back and forth to read data from disk
- this is known as disk seek
- since it is mechanical, this is slow
- a track is the circular part, and it has many sectors
- sector is the minimal unit of a hard disk. Each sector stores a fixed amount of user-accessible data, traditionally 512 bytes for hard disk drives.
Note
- this is the normal hard disk drive, also called HDD.
- modern SSD would be having a different design, i.e. using flash, which turns out to be much faster than the normal hard disk
I/O Request
When you do a read() or write(), if you needed something from the disk, Linux will do it by submitting an I/O Request
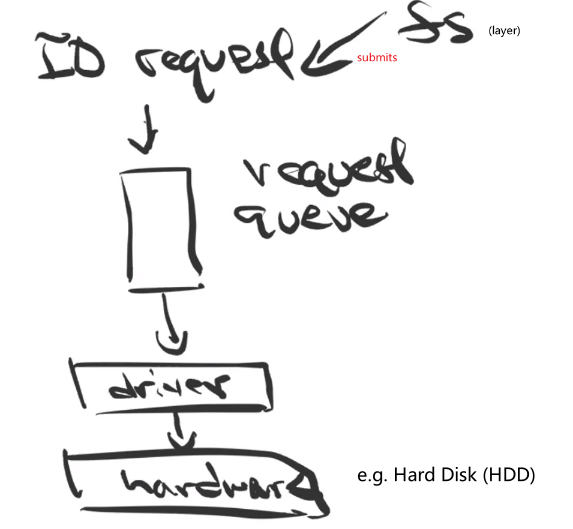
where:
- we do this because I/O from disks are usually slow, as the mechanism is purely mechanical (disk arm)
- this also means that, as
write()usually first goes to the Cache in RAM,read()might be slower thanwrite()because it might need to go to the Disk
- this also means that, as
- we want to optimize it by possibly merging requests and attempt to maximize data locality
- merge the requests if possible
- if the contents to be read is contiguous for two requests
- if not, sort the requests
- if the contents to be read is close to each other but not contiguous, put/sort the two requests close to each other (so I can handle nearby requests)
- then, you also have to solve the problem of starvation
- merge the requests if possible
Therefore, again we need some sort of “scheduling” policies for those requests.
- the main reason is that hard disk seeks are expensive
Deadline Elevator I/O Scheduling
Deadline Elevator
An overall sorted queue in block order (data block to be read would be next to each other)
Distinguishes between read and write requests, by having a separate read queue and a write queue
the requests in those two queues are pulled from the sorted queue
requests on those two queue are ordered by their deadlines
deadline is computed from $\text{submission time}+\Delta$. Some example $\Delta$ values are:
where we are basically dealing with
read()more often, because they are the time consuming ones that would block the programIf the deadline of a request in either the read queue or the write queue has expired
- then the read queue or write queue would pull those requests in instead of pulling from the sorted queue
Therefore, the above mechanism makes sure that:
- the problem of starvation is solved (by deadlines and pulling from expired deadlines)
However, the satisfice is:
- if there are expired requests, you would end up having disk arm jumping again, since they are not in block order. Once those requests are done, the disk arm needs to jump back to serve those ordered requests
Anticipatory I/O Scheduling
Anticipatory I/O Scheduling
- requests are sorted by deadline + anticipation
- this is to solve the problem of disk arm jumping back and forth
- after jumped and before going back to pull from sorted queue, check if there are some nearby block requests and service those
CFQ Elevator I/O Scheduling
Completely Fair Queue
maintains a request queue per process
maintains an overall round-robin request queue
- which pulls I/O request from process request queues in a round-robin way
- there could be some level of sorting done here

Eventually, this is dealing with:
- some processes are generating too much I/Os, being unfair to other processes
Solid State Disk Mechanis
The difference with HDD is that:
- there is no disk arm
- all made from using solid state/using electrons
- much faster than HDD:
- SSD in magnitude of $10\mu s$ and HDD in magnitude of $10ms$
- RAM is in magnitude of $10ns$
Therefore:
- a random access (jumping to a block position) has speed $\approx$ a sequential access
Therefore
- we don’t need to worry about disk seeks, i.e. attempting to order request by locality
Problem
the problem is now that, since I/O are faster with SSD, and we only had a single shared I/O queue, we need to face the problem of much time spending on lock contention
where:
- before with HDD, we can’t serve that much requests anyway, so this is a smaller problem
- now it becomes a similar problem as process scheduling
Therefore, the natural solution (e.g. from process scheduling) is to have private I/O queues per CPU
which is now an OK approach because
-
lock contention is solved
-
every time we pull from each CPU’s queue $\to$ no more block ordering for requests $\to$ doesn’t matter much since random access in SSD is about as fast as sequential access anyway
Data Organization on HDD
Logical Disk Block
- The one-dimensional array of logical blocks is mapped onto the sectors of the disk sequentially. Sector 0 is the first sector of the first track on the outermost cylinder, etc,
- By using this mapping, we can—at least in theory—convert a logical block number into an old-style disk address that consists of a cylinder number, a track number within that cylinder, and a sector number within that track.
Much of the illustration below will use a logical disk block.
Physical Disk Block
- Physical addressing gets into the nitty gritty of how the data is physically stored in the device, so it’s dependent on the physical attributes of the device. Spinning disk hard drives have to understand where on a platter to retrieve data, where as solid state hard drives deal with chips, tape drives have their own encoding for distance and position, etc.
Consider a file:
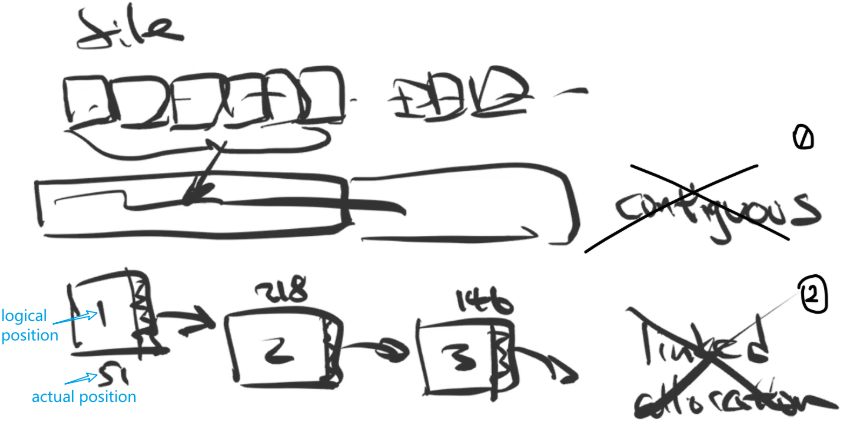
Some ways to store data on disk that does not work are
- allocate a contiguous block for file data $\iff$ doesn’t work since size might change (e.g. append stuff)
- each block stores a pointer linked to the next block of the file $\iff$ doesn’t work since losing one block would lose the entire file
File Allocation Table
FAT
Instead of having the linked list in each block, keep a global table that stores all links
where:
- this was used by the Windows system
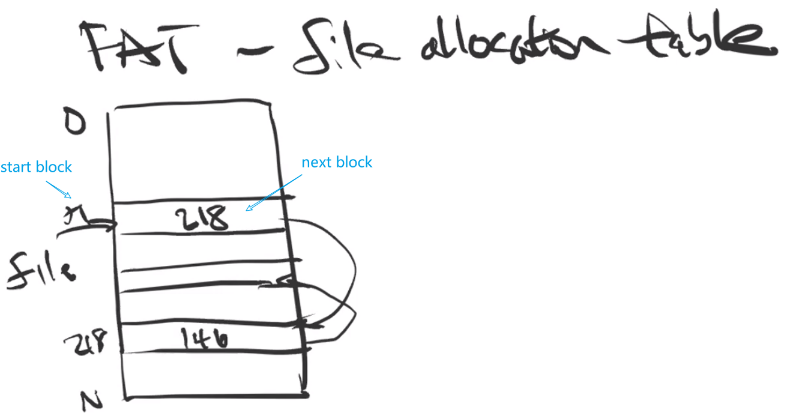
Now, the problem becomes:
- losing FAT loses all information
However, this turns out to be a good idea because:
- centralized important information $\to$ RAM can keep a copy of this in Cache $\to$ RAM knows block addresses in advance
Index Node
inode
- For each file, we have an inode, which contains many entries
- each entry points to a block of data on disk
- all the “links” of a file is stored in the inode
- then to keep a large amount of data, we use indirect blocks (on disk)
- an entry could point to an indirect block on disk
- an indirect block contains “links” to the next level/actual disk blocks
- therefore you can have multilevel indirect blocks
- single level indirect contains entries pointing to a disk block
- second level indirect contains entries pointing to the next level indirect
- etc.
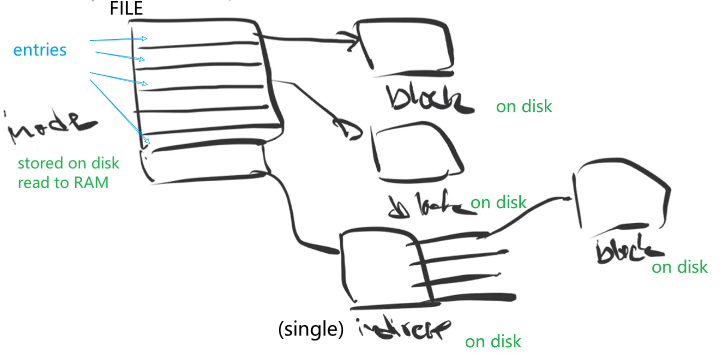
Note
- Everything in a Unix file system has a unique
inodenumber per file system that manages the storage and attributes for that thing: every file, directory, special file, etc.
- 2 files can have the same inode, but only if they are part of different file system. On each file system, there is a
superblockthat tells the system whichinodes are used, which are free- Files and directories are both managed with
inodes.
This implies that:
- the multilevel indirection then basically looks like a page walk $\to$ access might be slower for large files
Relationship between
superblock/inode/dentry
superblockcontains information on which validinodes we are using- each
inodecontains data for a specific file/directory- VFS often needs to perform directory-specific operations, such as path name lookup. Path name lookup involves translating each component of a path, including the file
- for example.
/bin/vi, whereviis the file, then you need to first perform a pathname look up- therefore, this is the use of a
dentryobject,dentryis a specific component in a path. Using the previous example,/,bin, andviare alldentryobjects.
Examples of Unix File Systems
*For Example: S5 File System*
This is the initial Linux File System, S5FS.
Usually, this is how it looks like on Disk
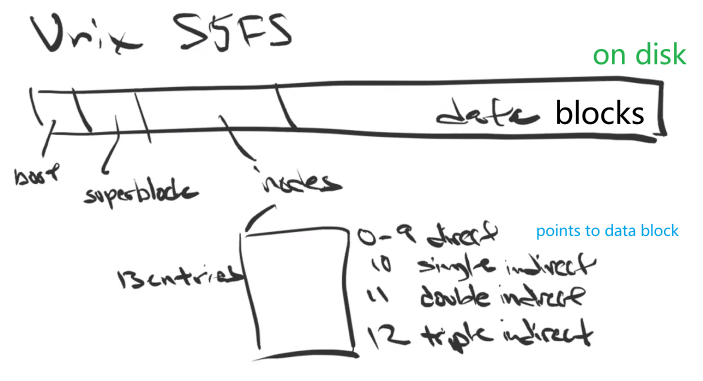
where:
- some space will be left for
superblockandinodes- the
superblockhere would tell you information such as the start/end of theinodes, etc.
- the
bootblock tells us how we boot this disk
Problem
- now, the most important information is the
superblock. So if you lose it, you lose everything.
For Example: Fast FS
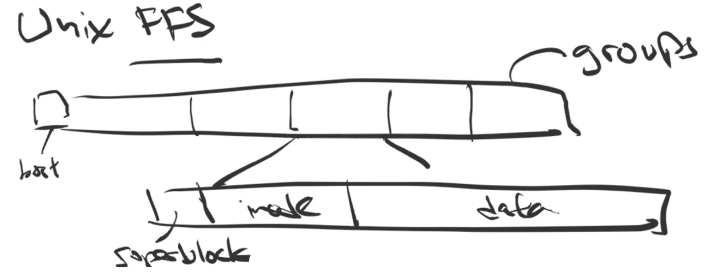
where:
- each group contains:
- a copy of the
superblock - the
inode - the
data blocks
- a copy of the
This also has a performance boost since:
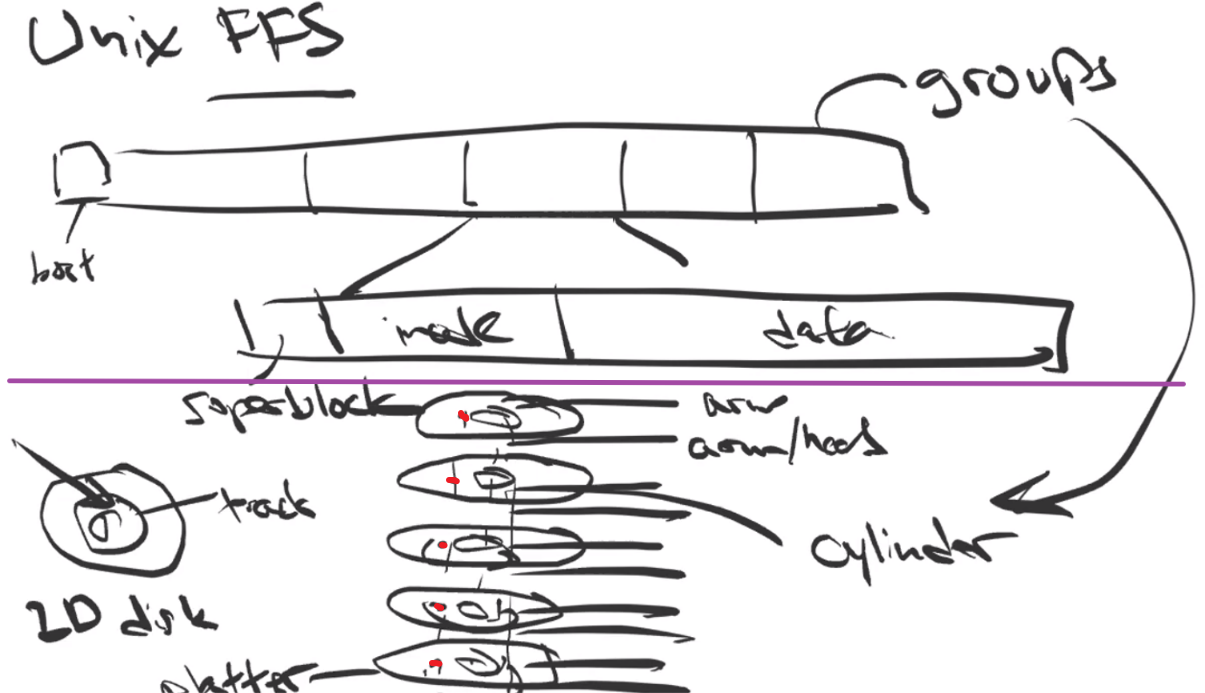
where:
-
while the disk spins, it can read a cylinder of data without disk arm moving
-
each group maps to a cylinder in disk
- therefore, this is locality $\to$ fast
For Example: EXT3/4

where:
- now the problem is we need three operations to update when a file is created, but only one write is atomic
- this was “remedied” by a File System Checker FSCK for a while (in
EXT2), but as Disks are larger, this is too slow
This problem of checking if updates are consistent in Disk is solved by using a journal.
Journaling
This is to solve the file system consistency problem, which is necessary since, e.g. creating a file means (not in order):
- update
inodebitmap - update
inode - update
dentryof parent
So we need consistency of all of them somehow updated, or none of them happened.
Journaling
Journaling filesystems write metadata (i.e., data about files and directories) into the journal/log that is flushed to the HDD before each command returns. When the update is done, a commit will be made.
if there is a corruption/pressed power off without syncing, then we would:
- go to the last commit
- check the data in journal before that last commit, if they are in sync with disk
- all the stuff after the commit is considered garbage
- if something is not correct, roll back to previous commit (i.e. second last commit of data consistency)
used for
EXT3/EXT4file system updates in Linux

Therefore, when you do a write (e.g. creating a file) to disk, your OS will do:
- write some update metadata/data in chronological order
- write a commit for an entire operation to the journal
- actually flush to disk
Disadvantage
- since we need to record our writes in journal, this means we need to “update” both the journal and the disk when we are doing some writes. This is some extra work/space.
Solution
- only record meta-data as a compromise. So that we might have data-inconsistency, but at least file system is consistent
Log Structured File System
This calls for a file system which focusses on write performance, makes use of the sequential bandwidth, and works efficiently on both disk writes as well as metadata updates.
Basically, the idea is:
- the Journaling idea itself becomes the file system mechanism, where we are reading/writing to
Log Structured FS - LFS
- Sequential, chronological ordering of all writes
- Avoid seek time for writes, since we are just appending
Disadvantage
- updates are hard, since you then need to find the data to update. Therefore, the approach is to just write a new one and rewire the
inode
- producing extra unneeded data
- for reads, you will need to keep an
inode-map, which tells you where theinodes are
- stored on RAM
inode-mapis periodically written to log- also, recall that most
reads are satisfied via Page Cache, so we don’t often go to Disk anyway
So the main problem is the update, which will chew up your memory very fast.
Cleaning/Compaction
- periodically cleans up unneeded data of a region of the memory
- try to do this when
fsis not busy

More advantages of this:
Snapshots of File System
- basically, you will just have a marker in your log-structured file system, so that every time you need to roll-back, roll-back to that marker
- so this is easy to do with this file system
Data Organization on SSD
For HDD, we wanted to minimize seek time. However, for SSD, recall that random seek time $\approx$ sequential seek time!
Problem of SSD
- know that random seek time is fast, but erase time is slow
- for HDD, we can just overwrite it. However for SSD using flash, we need to erase first
- e.g. when we update something, need to erase it and rewrite it.
- each disk block on SSD has a finite number of erases that you can do
- that disk block will wear out physically for large amount of erases
- this is also called wear leveling
- the lock contention for multi-CPU would be also a problem (mentioned before)
- needed private I/O queues
Now, what is a good file system that suits the SSD?
Log-Structured File System - LFS !
- write something new everytime for updates!
- wear leveling is solved
- since erasing is slow, we can just wipe a large block together IN ADVANCE
HDD and RAID
In reality, since HDD is cheaper, we still use HDD for storing large amount of data
HDD Reality
- can have large platter, can store lots of data
- large platter to move around, mechnically complicated and harder to make
- what if instead of a large disk, have many small platters instead
- mean time to failure MTTF is the same for disk regardless of the size (usually)
- lower reliability
- the solution is RAID
The aim is to:
- makes use of a combination of multiple disks instead of using a single disk for increased performance, data redundancy or both.
RAID - Redundant Array of Inexpensive/Independent Disk
RAID 0 - Striping but No Redundancy - bad idea
speads your data of the same file across disks, so that we can increase parallel reads
no copies of disks. Failure is not prevented/remedied at all.
where:
each block corresponds to a disk block
a horizontal strip is from the “same file”
RAID 1 - Mirroring: simply make a copy of the disk!
higher availability/reliability
higher I/O throughput since we can read same data from multiple disks
- sometimes, the same file might be saved on multiple disks so that we can have higher parallel read performances
doubling the writes/space
if you convert a SSD from RAID 1 to any other version, then your data is all over the place!
RAID 3 - Parity Disk
recover from any one disk failure (good assumption since they are independent)
if one disk failed, we can figure out what is missing deducting from looking at the parity disk + other disks
an simple example would be:
then, the problem becomes that you need to update the parity disk every time a disk is updated!
- eventually writes to parity disk becomes the bottleneck
RAID 5
striping/spreading the parity across disks
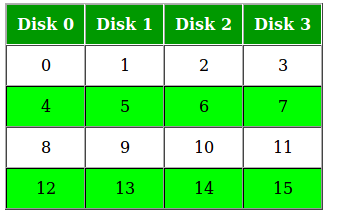
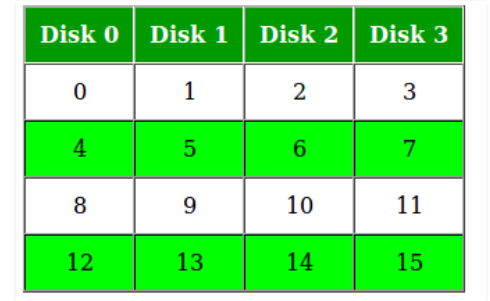


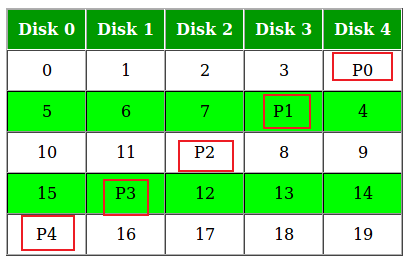
File System Review
fork()
- When we did
fork()for a program, the following happens:
- traps to kernel
- create
task struct- create
struct mm, i.e. address space
- copies all the vma
- for each addresses inside the vma, do a page walk and do a copy-on-write mapping for all the pages
- wakes up the task
- set the task to
runnnable- enqueue into the run queue
- if it gets picked by the scheduler, your
forked program is now runningforked program is running
- if it is writing to the page, a page fault happens
- traps back to the kernel
- walk page table
- realize it is cow mapping, then actually copies the page table
- restart the instruction
When a program is running
- there will be a timer for a program
->timer interrupts - als other scheduling class dependent stuff
exec()
- under the hood, it does:
- gets the
executableyou specified by translating/waling the file path- replace the content of this executable with the currently running process
- by something similar to
cfs/open.c- followed by a
readto load the program, seecfs/read_write.c
- if not on RAM, submits a disk I/O request
- the callback will wake the process back up after I/O is done
Actual Linux Implementation
Linux File System
The below code is stored un der the /fs directory, which contains:
- essentially each subdirectory represents a different file system (e.g.
ramfsandproc) - the files not in subdirectories represent file system generic code
Note
- there are actually some sample codes that shows you how a basic file system can be written. This is the
fs/ramfs/inode.c
struct inode (in memory)
This is in-memory inode, defined in include/linux/fs.h
/*
* Keep mostly read-only and often accessed (especially for
* the RCU path lookup and 'stat' data) fields at the beginning
* of the 'struct inode'
*/
struct inode {
umode_t i_mode;
unsigned short i_opflags;
kuid_t i_uid;
kgid_t i_gid;
unsigned int i_flags;
/* some code omitted here */
/* file related information */
union {
const struct file_operations *i_fop; /* former ->i_op->default_file_ops */
void (*free_inode)(struct inode *);
};
}
struct file (in memory)
This is in-memory file defined in include/linux/fs.h
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;
/* inode linked to the file */
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
}
where we see:
inodelinked to the file
struct superblock (in memory)
struct super_block {
/* some code omitted here */
struct list_head s_mounts;
} __randomize_layout;
struct dentry (in memory)
This is essentially linked to a inode
struct dentry {
/* some code omitted here */
struct hlist_bl_node d_hash; /* lookup hash list */
struct dentry *d_parent; /* parent directory */
struct qstr d_name;
/* which links to an inode */
struct inode *d_inode;
} __randomize_layout;
struct task_struct (in memory)
This is obviously in memory, but it actually contains
- file system related data
files_structopen files
struct task_struct{
/* some code omitted here */
struct fs_struct *fs;
/* Open file information: */
struct files_struct *files;
}
where:
-
the
fs_structcontains:struct fs_struct { int users; spinlock_t lock; seqcount_t seq; int umask; int in_exec; /* a root PATH */ struct path root, pwd; } __randomize_layout; -
the
files_structessentially contains an array offds, and thenext_fdmeans the next availablefdthat the next opened file is going to usestruct files_struct{ unsigned int next_fd; /* some code omitted here */ struct file __rcu * fd_array[NR_OPEN_DEFAULT]; };
c libfs.c (generic)
This is inside fs/libfs.c, which contains many file system generic operations
In fact
- the comment at the top of the file says that this is a library for file system writers
For Example
Accessing something like /usr/bin/vi means:
- OS creates
dentryfor/,usr,bin,vito get the actualinode/file - then it will cache those
dentries - so the next time we access
/, it will directly get theinodefrom the cache
struct dentry *simple_lookup(struct inode *dir, struct dentry *dentry, unsigned int flags)
{
if (dentry->d_name.len > NAME_MAX)
return ERR_PTR(-ENAMETOOLONG);
if (!dentry->d_sb->s_d_op)
d_set_d_op(dentry, &simple_dentry_operations);
d_add(dentry, NULL);
return NULL;
}
EXPORT_SYMBOL(simple_lookup);
/* dcache is basically the directory cache */
int dcache_dir_open(struct inode *inode, struct file *file)
{
file->private_data = d_alloc_cursor(file->f_path.dentry);
return file->private_data ? 0 : -ENOMEM;
}
/* some code omitted here */
func simple_fill_super()
This is used for file systems such as debug_fs
/*
* the inodes created here are not hashed. If you use iunique to generate
* unique inode values later for this filesystem, then you must take care
* to pass it an appropriate max_reserved value to avoid collisions.
*/
int simple_fill_super(struct super_block *s, unsigned long magic,
const struct tree_descr *files)
{
struct inode *inode;
struct dentry *root;
struct dentry *dentry;
int i;
/* 1. sets up some super block related field */
/* equivalent to what ramfs_fill_super() did */
s->s_blocksize = PAGE_SIZE;
s->s_blocksize_bits = PAGE_SHIFT;
s->s_magic = magic;
s->s_op = &simple_super_operations;
s->s_time_gran = 1;
if (!root)
return -ENOMEM;
for (i = 0; !files->name || files->name[0]; i++, files++) {
/* some code omitted here */
/* 2. sets up super block related operations */
/* equivalent to what ramfs_get_inode() did */
inode->i_mode = S_IFREG | files->mode;
inode->i_atime = inode->i_mtime = inode->i_ctime = current_time(inode);
inode->i_fop = files->ops;
inode->i_ino = i;
d_add(dentry, inode);
}
s->s_root = root;
return 0;
out:
d_genocide(root);
shrink_dcache_parent(root);
dput(root);
return -ENOMEM;
}
func simple_lookup()
This would be used, for example, by an open() system call, which would needed to find the dentry path from a string (by doing a path walk)
- for example,
ramfshas its directory operation havingsimple_lookup()
Inside simple_lookup(), we have:
-
looks the entry up and return the
dentry -
add this translation to
dcachestruct dentry *simple_lookup(struct inode *dir, struct dentry *dentry, unsigned int flags) { if (dentry->d_name.len > NAME_MAX) return ERR_PTR(-ENAMETOOLONG); if (!dentry->d_sb->s_d_op) d_set_d_op(dentry, &simple_dentry_operations); /* 2. add this translation to **`dcache`** */ d_add(dentry, NULL); return NULL; }
c init.c
Basically, come relavant functions are are to deal with
- file system initialization, including registration of a file system
func vfs_caches_init()
This is the entry point/initialization of kernel files system, which takes place in init.c, and goes to vfs_caches_init()
void __init vfs_caches_init(void)
{
names_cachep = kmem_cache_create_usercopy("names_cache", PATH_MAX, 0,
SLAB_HWCACHE_ALIGN|SLAB_PANIC, 0, PATH_MAX, NULL);
dcache_init();
inode_init();
files_init();
files_maxfiles_init();
/* mnt_init */
mnt_init();
}
which then goes to mnt_init for mount:
-
initializes
sys_fs, which will be used by the kernel in the beginningvoid __init mnt_init(void) { /* some code omitted here */ kernfs_init(); /* some code omitted here */ err = sysfs_init(); }which then calls
sysfs_init(), and does:-
registers file system, which registers the FILE SYSTEM’s TYPE with the system (i.e. this type
sysfsis now usable for future)- you will also see this in
init_ramfs_fsfor starter code
int __init sysfs_init(void) { int err; /* some code omitted here */ /* 1. registers file system */ err = register_filesystem(&sysfs_fs_type); if (err) { kernfs_destroy_root(sysfs_root); return err; } return 0; } - you will also see this in
-
Note
- for all cases, before using a file system, the first thing is to register it
- then you would need to mount
func arch_call_rest_init()
This then initializes things such as registering some other file systems
- this is also called in
init.c
arch_call_rest_init() just calls rest_init(), which then:
- creates a
kernel_threadto runkernel_init
noinline void __ref rest_init(void)
{
/* 1. creates a kernel_thread to run kernel_init */
pid = kernel_thread(kernel_init, NULL, CLONE_FS);
/* some code omitted here */
}
where that kernel_init does:
-
kernel_init()which goes todo_basic_setup(), then thendo_initcalls()calls stuff such as:init_ramfs_fs()and a bunch of otherinitcalls
static int __ref kernel_init(void *unused) { /* 1. this eventually goes to do_basic_setup */ kernel_init_freeable(); /* some code omitted here */ }
func do_mount()
This is eventually called by the system call mount().
Reminder
To use a file system in Linux, we would need to:
- register it
- mount it
Inside do_mount(), we are doing:
-
start a new mount with
do_new_mountlong do_mount(const char *dev_name, const char __user *dir_name, const char *type_page, unsigned long flags, void *data_page) { if /* some code omitted here */ else /* 1. start a new mount with `do_new_mount` */ retval = do_new_mount(&path, type_page, sb_flags, mnt_flags, dev_name, data_page); }then the
do_new_mount()does:-
gets the file system type
-
gets the file system context
-
has a bunch of stuff/metadata associated with a mounted file system
-
in code, it will go to
alloc_fs_context, and then attempts to get ainit_fs_contextOF THAT FILE SYSTEM- i.e. this is a field of a file system type
- for old/legacy file systems, this will be empty, so it will give it a
legacy_fs_context
static struct fs_context *alloc_fs_context() { /* attemps to get the file system's associated context */ init_fs_context = fc->fs_type->init_fs_context; if (!init_fs_context)/* if none, assign a legacy one */ init_fs_context = legacy_init_fs_context; ret = init_fs_context(fc); /* some code omitted here */ }and eventually, the
legacy_init_fs_contextwill containfc->ops = &legacy_fs_context_ops;, which looks like:const struct fs_context_operations legacy_fs_context_ops = { .free = legacy_fs_context_free, .dup = legacy_fs_context_dup, .parse_param = legacy_parse_param, .parse_monolithic = legacy_parse_monolithic, .get_tree = legacy_get_tree, .reconfigure = legacy_reconfigure, };Note
-
An example that has the context would be the
ramfs, which is in-memory:static struct file_system_type ramfs_fs_type = { .name = "ramfs", .init_fs_context = ramfs_init_fs_context, /* has a context */ .parameters = &ramfs_fs_parameters, .kill_sb = ramfs_kill_sb, .fs_flags = FS_USERNS_MOUNT, };
-
-
sets up the superblock for the file system, which will call the file system specific operation of
get_tree -
do the actual mount when everything setup (see very below)
static int do_new_mount(struct path *path, const char *fstype, int sb_flags, int mnt_flags, const char *name, void *data) { if (!fstype) return -EINVAL; /* 1. gets the file system type */ type = get_fs_type(fstype); /* 2. gets the file system context */ fc = fs_context_for_mount(type, sb_flags); put_filesystem(type); if (IS_ERR(fc)) return PTR_ERR(fc); /* some code omitted here */ if (!err && !mount_capable(fc)) err = -EPERM; if (!err) /* 3. stes up the superblock */ err = vfs_get_tree(fc); if (!err) /* 4. do the actual mount */ err = do_new_mount_fc(fc, path, mnt_flags); put_fs_context(fc); return err; }where the
vsf_get_tree()will:-
call the file system specific
get_tree()operation which would be contained in thecontextReminder:
-
the context looks like:
struct fs_context { const struct fs_context_operations *ops; /* some code omitted here */ }and the operation looks like:
struct fs_context_operations { void (*free)(struct fs_context *fc); int (*dup)(struct fs_context *fc, struct fs_context *src_fc); int (*parse_param)(struct fs_context *fc, struct fs_parameter *param); int (*parse_monolithic)(struct fs_context *fc, void *data); int (*get_tree)(struct fs_context *fc); /* the operation we are looking at now */ int (*reconfigure)(struct fs_context *fc); };
int vfs_get_tree(struct fs_context *fc) { struct super_block *sb; int error; if (fc->root) return -EBUSY; /* Get the mountable root in fc->root, with a ref on the root and a ref * on the superblock. */ /* 1. call the file system specific `get_tree()` operation */ error = fc->ops->get_tree(fc); /* some code omitted here */ }here, I will use the example of
ramfsto proceed-
this is actually a generic call for setting up the super block of a file system which has no underlying device
static int ramfs_get_tree(struct fs_context *fc) { return get_tree_nodev(fc, ramfs_fill_super); }which eventually goes to
vfs_get_super()-
find or create the superblock for the file system!
-
which then goes to
sget_fc()and actually allocates/create the super block viaalloc_super()struct super_block *sget_fc(struct fs_context *fc, int (*test)(struct super_block *, struct fs_context *), int (*set)(struct super_block *, struct fs_context *)) { /* some code omitted here */ s = alloc_super(fc->fs_type, fc->sb_flags, user_ns); }
-
-
then, if
rootis none, we want tofill_super()i.e. fill in metadata for the super block- which again calls the file system specific
fill_super()
int vfs_get_super(struct fs_context *fc, enum vfs_get_super_keying keying, int (*fill_super)(struct super_block *sb, struct fs_context *fc)) { /* some code omitted here */ /* 1. find or *create* the superblock for the file system! */ sb = sget_fc(fc, test, set_anon_super_fc); if (IS_ERR(sb)) return PTR_ERR(sb); if (!sb->s_root) { /* 2. then, if `root` is none, we want to `fill_super()` */ err = fill_super(sb, fc); } }where the
ramfs_fill_super()looks like:-
sets up some fields
-
create the root
inodeof the file system (everything has a file representation) -
makes the above
inodethe rootstatic int ramfs_fill_super(struct super_block *sb, struct fs_context *fc) { struct ramfs_fs_info *fsi = sb->s_fs_info; struct inode *inode; sb->s_maxbytes = MAX_LFS_FILESIZE; sb->s_blocksize = PAGE_SIZE; sb->s_blocksize_bits = PAGE_SHIFT; sb->s_magic = RAMFS_MAGIC; /* a magnic number */ sb->s_op = &ramfs_ops; sb->s_time_gran = 1; /* 2. create the **root `inode` of the file system** */ inode = ramfs_get_inode(sb, NULL, S_IFDIR | fsi->mount_opts.mode, 0); /* 3. makes the above `inode` the root */ sb->s_root = d_make_root(inode); if (!sb->s_root) return -ENOMEM; return 0; }where
ramfs_get_inodegets passed theS_IFDIRand does:-
sets up
inoderelated operations (similar to the file system operations) -
sets up the
inodefile related operations- if it is a regular file, it has
S_IFREG - if it is a directory, it goes to
S_IFDIR(our case)
struct inode *ramfs_get_inode(struct super_block *sb, const struct inode *dir, umode_t mode, dev_t dev) { /* some code omitted here */ switch (mode & S_IFMT) { case S_IFREG: inode->i_op = &ramfs_file_inode_operations; inode->i_fop = &ramfs_file_operations; break; case S_IFDIR: inode->i_op = &ramfs_dir_inode_operations; /* inode related */ inode->i_fop = &simple_dir_operations; /* file related */ } } - if it is a regular file, it has
-
- which again calls the file system specific
-
-
-
-
do the mount in
do_new_mount()when everything has been setup
-
func legacy_get_tree()
This is when, for example, in do_mount(), we needed to call the file system specific get_tree(). However, some legacy file system does not define those operations, therefore, legacy_get_tree() will be used in the context.
Reminder:
- for
ramfs, theget_tree()basically does:
- sets up the superblock for the file system
- fill in the super block with related operations
Inside legacy_get_tree(), we have:
-
directly
mountthe file systemstatic int legacy_get_tree(struct fs_context *fc) { /* some code omitted here */ root = fc->fs_type->mount(fc->fs_type, fc->sb_flags, fc->source, ctx->legacy_data); if (IS_ERR(root)) return PTR_ERR(root); /* some code omitted here */ return 0; }in this example, we use the
debug_fsspecificmount, which then doesstatic struct dentry *debug_mount(struct file_system_type *fs_type, int flags, const char *dev_name, void *data) { return mount_single(fs_type, flags, data, debug_fill_super); }
then, in the mount_single(), we are passing in the debug_fill_super() function, which does:
-
fills in the superblock using
simple_fill_super()- see section
funcsimple_fill_super()
- see section
-
overwrite some fields set up by the
simple_fill_super()call (library function), for customization purposesstatic int debug_fill_super(struct super_block *sb, void *data, int silent) { /* some code omitted here */ err = simple_fill_super(sb, DEBUGFS_MAGIC, debug_files); if (err) goto fail; /* 2. overwrites some fields for customization */ sb->s_op = &debugfs_super_operations; sb->s_d_op = &debugfs_dops; }
c fs/open.c
This basically demonstrate how an open() call is served.
First of all, the syscall definition of open() looks like:
SYSCALL_DEFINE3(open, const char __user *, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
/* AT_FDCWD means at current working directory location, used later */
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
func do_sys_open
This is called for the open() system call
Basically it does:
-
finds the file to be opened
-
find an unused
fdto be associated with that filelong do_sys_open(int dfd, const char __user *filename, int flags, umode_t mode) { /* 1. finds the file to be opened */ tmp = getname(filename); if (IS_ERR(tmp)) return PTR_ERR(tmp); /* 2. find an *unused* `fd` to be **associated with that file** */ fd = get_unused_fd_flags(flags); if (fd >= 0) { /* 3. open the file */ struct file *f = do_filp_open(dfd, tmp, &op); if (IS_ERR(f)) { put_unused_fd(fd); fd = PTR_ERR(f); } else { fsnotify_open(f); /* 4. install the file * to the found fd of the process */ fd_install(fd, f); } } putname(tmp); return fd; }then,
get_unused_fd_flags()will allocate a file descriptor using__alloc_fd():int get_unused_fd_flags(unsigned flags) { /* current->files points to the ARRAY OF OPEN FILES of this process */ return __alloc_fd(current->files, 0, rlimit(RLIMIT_NOFILE), flags); }and it does:
-
get the file descriptor table of the process
-
start with
0, and find the next available file descriptor- recall that this is kept in a single field
next_fd
- recall that this is kept in a single field
-
sets up the next file descriptor (for the next call)
int __alloc_fd(struct files_struct *files, unsigned start, unsigned end, unsigned flags) { /* some code omitted here */ fd = start; if (fd < files->next_fd) fd = files->next_fd; if (fd < fdt->max_fds) fd = find_next_fd(fdt, fd); }
-
-
actually open the file with
do_filp_open, which does:-
sets up a metadata
nameidatawhich stores the pathname and etc. -
open the path
struct file *do_filp_open(int dfd, struct filename *pathname, const struct open_flags *op) { /* some code omitted here */ set_nameidata(&nd, dfd, pathname); filp = path_openat(&nd, op, flags | LOOKUP_RCU); }which goes to
path_openat()and does:-
path_initwhich does sets up the starting point of path walk-
if the pathname starts with
/, then it is absolute path -
otherwise, if it is relative to current working directory
- this is actually setup by the system call
do_sys_open(AT_FDCWD, filename, flags, mode);
if (*s == '/') { set_root(nd); if (likely(!nd_jump_root(nd))) return s; return ERR_PTR(-ECHILD); } else if (nd->dfd == AT_FDCWD) { /* some code omitted here */ } - this is actually setup by the system call
-
-
link_path_walkdoes the actual path walk-
for the string path given, convert it into the
dentryrepresentation viawalk_component, and either does alookup_fastor alookup_slow-
look up fast looks like, and basically goes to the
dcacheto look upstatic int lookup_fast(struct nameidata *nd, struct path *path, struct inode **inode, unsigned *seqp) { /* some code omitted here */ dentry = __d_lookup_rcu(parent, &nd->last, &seq); } -
look up slow does a
__lookup_slow(), which does:- allocate a
dentry - call the file system specific
inodeoperation oflook_up()- for
ramfs, it actually becomes thesimple_lookupoflibfs
- for
/* Fast lookup failed, do it the slow way */ static struct dentry *__lookup_slow(const struct qstr *name, struct dentry *dir, unsigned int flags) { dentry = d_alloc_parallel(dir, name, &wq); if{ /* some code omitted here */ } else { /* 2. file system specific lookup */ old = inode->i_op->lookup(inode, dentry, flags); d_lookup_done(dentry); if (unlikely(old)) { dput(dentry); dentry = old; } } }```
- allocate a
-
```
-
-
-
do_last, now all dentries are walked. So we look at theinodeon the last part of the path, by doing avfs_open(), which does ado_dentry_open()by passing in the actual file’sinodeand does:-
if no
openfunction is passed in, use the file/inode’sopenfunction infile->f_op->open-
for
ramfs, if this is a directory, it does asimple_dir_operations->openwhich is adcache_dir_open()int dcache_dir_open(struct inode *inode, struct file *file) { file->private_data = d_alloc_cursor(file->f_path.dentry); return file->private_data ? 0 : -ENOMEM; }```
```
-
so now you have the file pointer setup
static struct file *path_openat(struct nameidata *nd, const struct open_flags *op, unsigned flags) { if{ /* some code omitted here */ } else { const char *s = path_init(nd, flags); /* 1. sets up the starting point of path walk */ while (!(error = link_path_walk(s, nd)) && /* 2. does the walk */ (error = do_last(nd, file, op)) > 0) { /* 3. open the file */ nd->flags &= ~(LOOKUP_OPEN|LOOKUP_CREATE|LOOKUP_EXCL); s = trailing_symlink(nd); } terminate_walk(nd); } } -
-
-
once we have obtained the file pointer, install it to the
fdwe found, and doesfd_install, and basically does:-
use the array of
fds of the process -
index into to the array using out found
fs -
put the file pointer into that position
void __fd_install(struct files_struct *files, unsigned int fd, struct file *file) { struct fdtable *fdt; rcu_read_lock_sched(); /* some code omitted here */ /* coupled with smp_wmb() in expand_fdtable() */ smp_rmb(); fdt = rcu_dereference_sched(files->fdt); BUG_ON(fdt->fd[fd] != NULL); /* 1.2.3. use the array of `fd`s of the process and puts the pointer in */ rcu_assign_pointer(fdt->fd[fd], file); rcu_read_unlock_sched(); } void fd_install(unsigned int fd, struct file *file) { /* passing in */ __fd_install(current->files, fd, file); }
-
func dcache_dir_open
Linux
cdinto a Directory
- What happens in terminal when you
cdinto a directory would be (for some genericopen/read_dir):
- the
dcache_dir_opengets calleddcache_readdirdcache_dir_close
Starting off form the top, dcache_dir_open does:
-
allocate cursors, creates a
dentryby "cloning itself" that ‘s not linked to any inode and itsd_subdirare initialized with only itself in it-
this in turn calls
d_alloc_cursor, which goes tod_alloc_anon, then to__d_alloc_anon(sb, NULL) -
set up the
dentryto some “special state”struct dentry *__d_alloc(struct super_block *sb, const struct qstr *name) { /* some code omitted here */ dentry->d_name.len = name->len; dentry->d_name.hash = name->hash; /* 1. set up the dentry to some "special state" */ dentry->d_inode = NULL; dentry->d_parent = dentry; dentry->d_sb = sb; dentry->d_op = NULL; INIT_LIST_HEAD(&dentry->d_subdirs); /* subdirs is empty */ }
-
int dcache_dir_open(struct inode *inode, struct file *file)
{
/* 1. allocate cursors = a cloned dentry of itself @file->f_path.dentry */
file->private_data = d_alloc_cursor(file->f_path.dentry);
return file->private_data ? 0 : -ENOMEM;
}
The upshot is that we are hiding some data (
cursor) in theprivatefield of the file
func dcache_readdir
Linux
cdinto a Directory
- What happens in terminal when you
cdinto a directory would be (for some genericopen/read_dir):
- the
dcache_dir_open
- placed some
curosrdentry into thefile->private_dataof the current directorydcache_readdirdcache_dir_close
Starting from:
-
gets the cursor from
private_data -
creates the
./and../directory on the fly
-
eventually they will call
dir_emit_dotanddir_emit_dot_dot, the former does:-
assigns something to the
ctxfieldstatic inline bool dir_emit_dot(struct file *file, struct dir_context *ctx) { /* 1. assigns something to the `ctx` field */ return ctx->actor(ctx, ".", 1, ctx->pos, file->f_path.dentry->d_inode->i_ino, DT_DIR) == 0; }
-
-
iterates over the sub-directories using
scan_positives, and show them up usingdir_emit-
which does:
-
looking for the
@count-th positivedentryafter the passed in@p, by iterating over allsub_dirs -
skip cursors
-
return the found
dentry(i.e. sub-dir) if it ispositive-
the positive test essentially just does
d_really_is_positive:-
checks if this
dentryhas aninodeor not.static inline bool d_really_is_positive(const struct dentry *dentry) { return dentry->d_inode != NULL; }
-
static struct dentry *scan_positives(struct dentry *cursor, struct list_head *p, loff_t count, struct dentry *last) { struct *found = NULL; struct dentry *dentry = cursor->d_parent; /* 1. iterate over reall subdirs * - first (fake) sub_dir is @dentry->d_subdirs * - next dir to emit is @p->next, @p starts with ../ */ while ((p = p->next) != &dentry->d_subdirs) { /* @d_child = child of parent list */ struct dentry *d = list_entry(p, struct dentry, d_child); // 2. we must at least skip cursors, to avoid livelocks if (d->d_flags & DCACHE_DENTRY_CURSOR) continue; /* 3. spits out REAL directories */ if (simple_positive(d) && !--count) { /* some code omitted here */ if (simple_positive(d)) found = dget_dlock(d); if (likely(found)) break; count = 1; } } spin_unlock(&dentry->d_lock); dput(last); /* possibly kill previous directory */ return found; } -
-
int dcache_readdir(struct file *file, struct dir_context *ctx) { struct dentry *dentry = file->f_path.dentry; /* current dir */ /* 1. gets the cursor */ struct dentry *cursor = file->private_data; /* fake sub_dirs */ struct list_head *anchor = &dentry->d_subdirs; /* real sub_dirs */ struct dentry *next = NULL; struct list_head *p; /* 2. creates the ./ and ../ directory on the fly */ if (!dir_emit_dots(file, ctx)) return 0; if (ctx->pos == 2) p = anchor; /* real sub_dirs */ else if (!list_empty(&cursor->d_child)) p = &cursor->d_child; else return 0; /* 3. dir_emit real @p=anchor directories */ while ((next = scan_positives(cursor, p, 1, next)) != NULL) { if (!dir_emit(ctx, next->d_name.name, next->d_name.len, d_inode(next)->i_ino, dt_type(d_inode(next)))) break; ctx->pos++; p = &next->d_child; } spin_lock(&dentry->d_lock); dput(next); return 0; }funcd_alloc_name() -
adds a dentry to to the parent, i.e. adds a subdirectory
eventually calls:
struct dentry *d_alloc(struct dentry * parent, const struct qstr *name)
{
struct dentry *dentry = __d_alloc(parent->d_sb, name);
if (!dentry)
return NULL;
spin_lock(&parent->d_lock);
/*
* don't need child lock because it is not subject
* to concurrency here
*/
__dget_dlock(parent);
dentry->d_parent = parent;
list_add(&dentry->d_child, &parent->d_subdirs); /* how things are added */
spin_unlock(&parent->d_lock);
return dentry;
}
snippet sub-dir iteration
struct dentry *dentry; /* parent dentry */
spin_lock(&dentry->d_lock);
cursor = &dentry->d_subdirs; /* start to sub_dir */
while ((cursor = cursor->next) != &dentry->d_subdirs) {
/* gets the sub_dir dentry and inode */
struct dentry *d = list_entry(cursor, struct dentry, d_child);
struct inode *i = d_inode(d);
/* some code omitted here */
}
spin_unlock(&dentry->d_lock);
where:
- basically it is stored in the
&dentry->d_subdirs->nextas a circular linked list
snippet iget_locked
basically, this is used to get or create an inode with a specified ino.
However, if it is a new inode, there will be a lock that you need to release
- see
unlock_new_inode(inode);
struct inode *some_function()
{
retry:
/* obtains the inode with ino=pid */
inode = iget_locked(parent->d_sb, pid);
/*
* if old inode, ...
* if new inode, ...
* and set relevant field
*/
info = inode->i_private;
if (!(inode->i_state & I_NEW) && info) {
/* old inode */
goto retry;
}
/* new inode, sets relevant field */
inode->i_atime = inode->i_mtime = inode->i_ctime = current_time(inode);
inode->i_fop = &ppagefs_piddir_operations;
inode->i_op = &ppagefs_piddir_inode_operations;
inode->i_mode = S_IFDIR | 0755;
/* set private data */
info = kmalloc(sizeof(struct p_info), GFP_KERNEL);
inode->i_private = info;
info->retain = 1;
/* some code omitted here */
unlock_new_inode(inode);
}
snippet create file/folder
In short, both a file/folder will need a dentry + inode
Therefore, the code is almost the same:
- create a
dentryto be associated for the file/folder - get a new inode
- if we want a file, the
inodeshould be attached with file related operations - otherwise, directory related operations
- if we want a file, the
- attach the
inodewith thedentry
dentry = d_alloc_name(parent, file->name);
if (!dentry)
return NULL;
/* only difference here is the operations assigned */
inode = ppage_get_inode(parent->d_sb, S_IFREG);
if (!inode)
return NULL;
d_add(dentry, inode);
and the creation of inode is slightly customized to be:
- create a new inode
new_inode() - assign some generic properties
- only difference between a file and a folder in
inode
/* generic operations */
struct inode *ppage_get_inode(struct super_block *sb, umode_t mode)
{
struct inode *inode = new_inode(sb);
if (inode) {
/* 2. assign some generic properties */
inode->i_ino = get_next_ino();
inode->i_atime = inode->i_mtime =
inode->i_ctime = current_time(inode);
/* 3. only difference between a file and a folder in `inode` */
switch (mode & S_IFMT) {
case S_IFDIR:
inode->i_mode = S_IFDIR | 0755;
inode->i_op = &ppagefs_piddir_inode_operations;
inode->i_fop = &ppagefs_piddir_operations;
break;
case S_IFREG:
inode->i_mode = S_IFREG | 0644;
inode->i_op = &ppagefs_file_inode_operations;
inode->i_fop = &ppagefs_file_operations;
break;
default:
inode->i_op = &ppagefs_file_inode_operations;
inode->i_fop = &ppagefs_file_operations;
break;
}
}
return inode;
}
Linux Disk I/O
func wakeup_flusher_threads()
This is the mechanism mentioned above where we periodically flush written data from RAM to Disk.
One example of this is:
void ksys_sync(void)
{
int nowait = 0, wait = 1;
wakeup_flusher_threads(WB_REASON_SYNC);
/* some code omitted here */
}
SYSCALL_DEFINE0(sync)
{
ksys_sync();
return 0;
}
where:
-
the
syncsystem call has the description of:DESCRIPTION Synchronize cached writes to persistent storage If one or more files are specified, sync only them, or their containing file systems.
Note
- this also means that the
write()system calls actually first write to Page Cache of RAM. Only when it is flushed, it gets to the disk.
- this also means that sometimes,
write()might even be faster thanread()- However, it is possible to implement a file system that writes directly to disk. An application-side example is the DBMS, some of which has its own cache management and disk management mechanism.
c fs/read_write.c
Used for read/write() system calls
func ksys_read()
Eventually this gets to __vfs_read
ssize_t __vfs_read(struct file *file, char __user *buf, size_t count,
loff_t *pos)
{
if (file->f_op->read) /* if file system specific has open() */
return file->f_op->read(file, buf, count, pos);
else if (file->f_op->read_iter) /* if only has read_iter */
return new_sync_read(file, buf, count, pos);
else
return -EINVAL;
}
and now, in the example of ramfs (as well as for ext4, which is the main file system for regular files), there is no read() for a file operation. So we go to new_sync_read() and does:
-
sets up the starting point of the buffer and the end, where:
iov_baseis the starting point/destination to put data toiov_lenis the total length to read
-
conglomerate all relevant info from above to a single
struct iov_iter iter- e.g. user’s buffer would be there
-
eventually calls the file specific
read_iterstatic ssize_t new_sync_read(struct file *filp, char __user *buf, size_t len, loff_t *ppos) { struct iov_iter iter; /* 1. ets up the starting point of the buffer and the end */ struct iovec iov = { .iov_base = buf, .iov_len = len }; /* some code omitted here */ /* 2. conglomerate all relevant info from above to @iter */ iov_iter_init(&iter, READ, &iov, 1, len); /* 3. calls file specific read_iter */ ret = call_read_iter(filp, &kiocb, &iter); BUG_ON(ret == -EIOCBQUEUED); if (ppos) *ppos = kiocb.ki_pos; return ret; }for
ramfsas well asext4, theread_iteris ageneric_file_read_iterforlibc, which reads data from the page cache (ramfsstores data in page cache)So
genetic_file_read_iterdoes:-
real work occurs in
generic_file_buffered_read/** * This is the "read_iter()" routine for all filesystems * that can use the PAGE CACHE directly. * Return: * * number of bytes copied, even for partial reads * * negative error code if nothing was read */ ssize_t generic_file_read_iter(struct kiocb *iocb, struct iov_iter *iter) { /* some code omitted here */ retval = generic_file_buffered_read(iocb, iter, retval); }now, inside
generic_file_buffered_read(), we have:-
get an “address space” for a file
-
computes the address of the
PAGEthat we are reading from -
gets the page from Page Cache using
find_get_page- if we got the
PAGE, then we can read from there - otherwise, we need to read from Disk, we would go to
page_cache_sync_readahead
-
sets the the Pages we need
-
submit a Disk I/O request for reading from Disk, and return
- some other functions will checks if the allocated Pages are updated (and does some other work/checking). If not updated when checked, it will then block the process
unsigned int __do_page_cache_readahead(struct address_space *mapping, struct file *filp, pgoff_t offset, unsigned long nr_to_read, unsigned long lookahead_size) { /* some code omitted here */ /* 1. sets the the Pages we need */ page = __page_cache_alloc(gfp_mask); /* 2. submit request to read data from DISK */ if (nr_pages) read_pages(mapping, filp, &page_pool, nr_pages, gfp_mask); }where eventually, the
read_pagescalls file system specificreadpages(), in the case ofext4, we have the following definition:static const struct address_space_operations ext4_aops = { .readpage = ext4_readpage, .readpages = ext4_readpages, /* some code omitted here */ }so that the
ext4_readpages()gets called and eventually goes to:-
configures the request.
- for example,
bio->bi_end_io = mpage_end_io;is the call back when the I/O completed
- for example,
-
submit the request
int ext4_mpage_readpages(struct address_space *mapping, struct list_head *pages, struct page *page, unsigned nr_pages, bool is_readahead) { /* some code omitted here */ if (bio == NULL) { struct bio_post_read_ctx *ctx; bio = bio_alloc(GFP_KERNEL, min_t(int, nr_pages, BIO_MAX_PAGES)); if (!bio) goto set_error_page; /* some code omitted here */ /* 1. configures the request. */ bio_set_dev(bio, bdev); bio->bi_iter.bi_sector = blocks[0] << (blkbits - 9); bio->bi_end_io = mpage_end_io; /* call back */ bio->bi_private = ctx; bio_set_op_attrs(bio, REQ_OP_READ, is_readahead ? REQ_RAHEAD : 0); } /* 2. submit the request */ if (bio) { submit_bio(bio); bio = NULL; } }Note
-
What happens to the request then? There will be a queue for the I/O request, and some scheduling done on the submitted requests, to do:
- merge the requests if possible
- if the contents to be read is contiguous for two requests
- if not, sort the requests
- if the contents to be read is close to each other but not contiguous, put/sort the two requests close to each other (so I can handle nearby requests)
- then, you also have to solve the problem of starvation
the aim is to make disk arm to be more efficient, because seek takes time on the Disk!
- merge the requests if possible
-
- if we got the
-
Now we would most likely have the pages ready.
-
However, since the I/O request is async, we need to know if the Page is up-to-date.
-
if not,
wait_on_page_locked_killable, which eventually goes towait_on_page_bit_common:-
configures the wait queue for this process (until the Disk I/O we needed is done)
-
sleep it by setting its state and call
io_schedule()static inline int wait_on_page_bit_common(wait_queue_head_t *q, struct page *page, int bit_nr, int state, enum behavior behavior) { init_wait(wait); wait->flags = behavior == EXCLUSIVE ? WQ_FLAG_EXCLUSIVE : 0; wait->func = wake_page_function; wait_page.page = page; wait_page.bit_nr = bit_nr; for (;;) { /* some code omitted here */ set_current_state(state); spin_unlock_irq(&q->lock); bit_is_set = test_bit(bit_nr, &page->flags); if (behavior == DROP) put_page(page); /* 2. sleep it by setting its state and call `io_schedule()` */ if (likely(bit_is_set)) io_schedule(); } finish_wait(q, wait); }Note
-
eventually, someone has to wake this process up. This is done by the call back function configured while we submitted the
biorequest:bio->bi_end_io = mpage_end_io; /* call back */which would happen when disk i/O request is completed. Then it would go to
__read_end_io, which would:-
sets the Page to be up-to-date
-
unlocks the page via
unlock_pageand wakes the process up-
this will go to
wake_up_page_bit(), then to__wake_up_locked_key_bookmark, and finally wakes the process upvoid __wake_up_locked_key_bookmark( struct wait_queue_head *wq_head, unsigned int mode, void *key, wait_queue_entry_t *bookmark) { __wake_up_common(wq_head, mode, 1, 0, key, bookmark); }
static void __read_end_io(struct bio *bio) { struct page *page; struct bio_vec *bv; struct bvec_iter_all iter_all; bio_for_each_segment_all(bv, bio, iter_all) { if (bio->bi_status || PageError(page)) { /* some code omitted here */ } else { /* 1. sets the Page to be **up-to-date** */ SetPageUptodate(page); } /* 2. unlocks the page via `unlock_page` * and wakes the process up */ unlock_page(page); } if (bio->bi_private) mempool_free(bio->bi_private, bio_post_read_ctx_pool); bio_put(bio); } -
-
-
-
-
-
At this point, the Page will be up-to-date, and we finally can read/copy data to user's buffer
-
eventually, if we are not dealing with pipes, this will go to ` copy_page_to_iter_iovec
and thencopyout`-
this basically copies data back to user
static int copyout(void __user *to, const void *from, size_t n) { if (access_ok(to, n)) { kasan_check_read(from, n); n = raw_copy_to_user(to, from, n); } return n; }
-
static ssize_t generic_file_buffered_read(struct kiocb *iocb, struct iov_iter *iter, ssize_t written) { /* 1. get an "address space" for a file */ struct address_space *mapping = filp->f_mapping; /* 2. gets the page number, i.e. which PAGE I am reading */ index = *ppos >> PAGE_SHIFT; find_page: if (fatal_signal_pending(current)) { error = -EINTR; goto out; } /* 3. gets the page from Page Cache using `find_get_page` */ page = find_get_page(mapping, index); if (!page) { if (iocb->ki_flags & IOCB_NOWAIT) goto would_block; page_cache_sync_readahead(mapping, ra, filp, index, last_index - index); /* 4. Now we would *most likely* have the pages ready */ page = find_get_page(mapping, index); if (unlikely(page == NULL)) goto no_cached_page; } if (!PageUptodate(page)) { /* some code omitted here */ /* 5. if not up-to-date */ error = wait_on_page_locked_killable(page); } page_ok: /* some code omitted here */ /* 6. now we can copy it to user space... recall @iter contains user's buffer */ ret = copy_page_to_iter(page, offset, nr, iter); offset += ret; index += offset >> PAGE_SHIFT; offset &= ~PAGE_MASK; prev_offset = offset; put_page(page); } -
-
-
Week 11 - I/O System
The basic hardware elements involved in I/O are:
- buses
- device controllers
- devices themselves
- CPU/DMA to move data around
The work of moving data between devices and main memory is performed by
- the CPU as programmed I/O
- or is offloaded to a DMA controller.
Device Drivers
- To encapsulate the details and oddities of different devices for their ports, controllers, and etc, the kernel of an operating system is structured to use device-driver modules.
- The device drivers present:
- a uniform device access interface to the I/O subsystem, e.g. a keyboard (similar to system calls).
I/O Hardware
Some important hardware elements are:
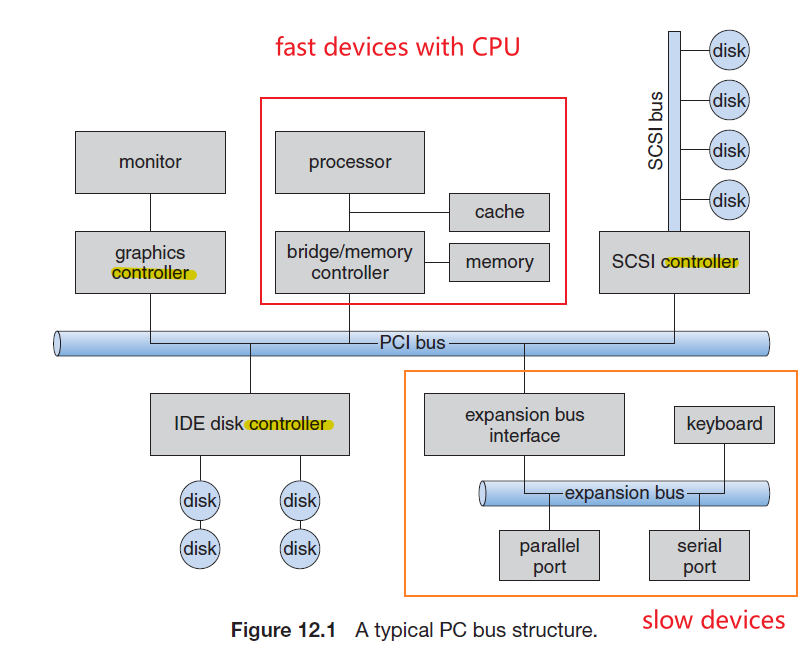
- Port - device communicates with the machine via a connection point, or port
- for example, a serial port
- Bus: set of wires and a rigidly defined protocol that specifies a set of messages that can be sent on the wires.
- Controller: A controller is a collection of electronics that can operate a port, a bus, or a device
- i.e. CPU gives data and commands to controller, then controller actually operates on that device
Communication to Controller
- CPU can send data and commands to the controller in two ways:
- Controller has one or more registers for data and control signals, so CPU transfer of a byte or word to an I/O port address.
- Alternatively, the device controller can support memory-mapped I/O. In this case, the device-control registers are mapped into the address space of the processor.
- communications occur by reading and writing directly to/from those memory areas.
I/O Port Communication
If we are writing data/communicating via the I/O port, then the following happens
**Registers in I/O Port **
- An I/O port typically consists of four registers, called the status, control, data-in, and data-out registers
- The data-in register is read by the host to get input.
- The data-out register is written by the host to send output.
- The status register contains bits that can be read by the host. These bits indicate states, such as whether the current command has completed, whether a byte is available to be read from the data-in register, and whether a device error has occurred.
- The control register can be written by the host to start a command or to change the mode of a device.
Polling I/O
Communication Between CPU and Device using I/O Port
- The host repeatedly reads the
busybit in status register until that bit becomes clear.
- CPU busy waiting/polling
- The host sets the
writebit in the command register and writes a byte into the data-out register.- The host sets the command-ready bit.
- When the controller notices that the command-ready bit is set, it sets the
busybit.- The controller reads the command register and sees the write command. It reads the data-out register to get the byte and does the I/O to the device.
- The controller clears the command-ready bit, clears the error bit in the status register to indicate that the device I/O succeeded, and clears the
busybit to indicate that it is finished.
Disadvantage:
- in step 1, the host is busy-waiting or polling: it is in a loop, reading the status register over and over until the busy bit becomes clear. Suitable for data that needs to be serviced quickly, but not suitable for long waits.
Interrupt Driven I/O
The mechanism is as follows:
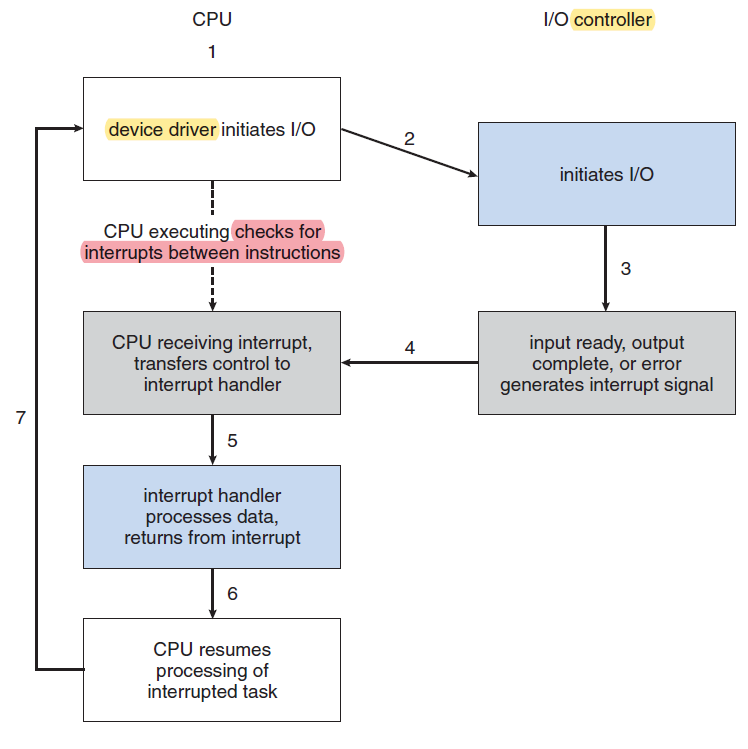
where:
- device driver (kernel) has nothing to do with device controller (hardware)
- this is the interrupt mechanism we discussed in the very beginning of course
In summary, interrupts are used throughout modern operating systems to handle asynchronous events and to trap to supervisor-mode routines in the kernel.
Direct Memory Access
This is the case when we have large amount of data transfer. We don’t want CPU transferring data in and out of registers one byte at a time.
- uses a DMA Controller (a special processor)
- and a DMA block
- uses Interrupt-driven I/O
Note
- This has nothing to do with Memory Mapped I/O.
Components for DMA
- a special-purpose processor called a direct-memory-access (DMA) controller
- a DMA command block which contains
- a pointer to the source of a transfer,
- a pointer to the destination of the transfer,
- a count of the number of bytes to be transferred.
Mechanism of DMA
To initiate a DMA transfer, the host writes a DMA command block into memory
- contains the pointer to source of transfer, etc.
CPU writes the address of this command block to the DMA controller
The DMA controller proceeds to operate the memory bus directly
While the DMA transfer is going on the CPU does not have access to the PCI bus ( including main memory ), but it does have access to its internal registers and primary and secondary caches
When the entire transfer is finished, the DMA controller interrupts the CPU
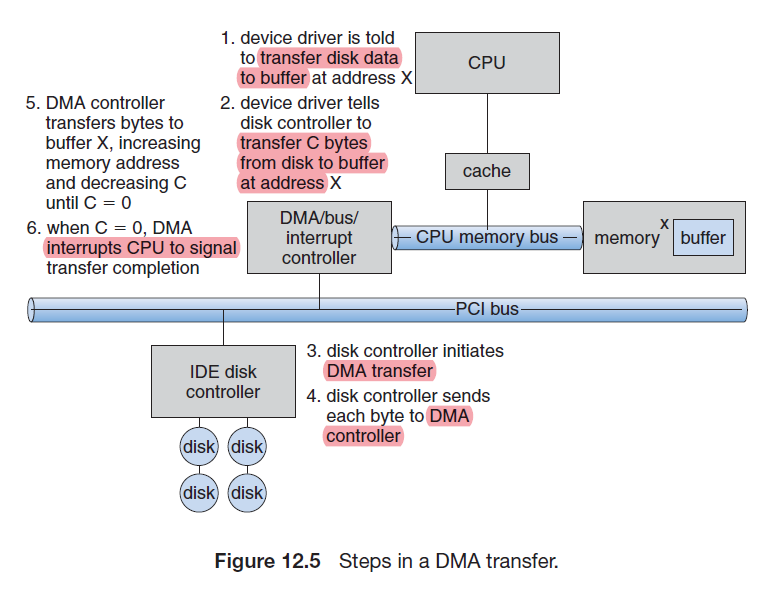
Kernel I/O Subsystem
Buffering
A buffer, of course, is a memory area that stores data being transferred between two devices or between a device and an application
When Buffering is Used
- One reason is to cope with a speed mismatch between the producer and consumer of a data stream.
- for example, that a file is being received via modem for storage on the hard disk. The modem is about a thousand times slower than the hard disk. So a buffer is created in main memory to accumulate the bytes received from the modem. When an entire buffer of data has arrived, the buffer can be written to disk in a single operation.
- A second use of buffering is to provide adaptations for devices that have different data-transfer sizes.
- in computer networking, where buffers are used widely for fragmentation and reassembly of messages.
- A third use of buffering is to support copy semantics for application I/O.
- for example, at
t=0you issuedwrite()with some data in your buffer to send to disk. But before the data is actually written to disk, you changed your data. Copy semantics ensured data written is at the time of submission (t=0).
Caching
The difference between cache and buffer is that:
- buffer may hold the only existing copy of a data item,
- a cache, by definition, holds a copy on faster storage of an item that resides elsewhere.
Caching
- we basically encountered this already, where we have a page cache for
read(), and also for bufferingwriteto be flushed to disk as one unit
Spooling
Spooling works like a typical request queue where data, instructions and processes from multiple sources are accumulated for execution later on.
- SPOOL is an acronym for simultaneous peripheral operations on-line. It is a kind of buffering mechanism or a process in which data is temporarily held to be used and executed by a device, program or the system.
Characteristics of Spooling
- buffers data for ( peripheral ) devices such as printers that cannot support interleaved data streams.
- i.e. cannot print half of the file, and then skip to another file
- If multiple processes want to print at the same time
- they each send their print data to files stored in the spool directory.
- When each file is closed, then the application sees that print job as complete, and the print scheduler sends each file to the appropriate printer one at a time for execution
Implementation of Spooling
- The spooling system copies the queued spool files to the printer one at a time. In some operating systems, spooling is managed by a system daemon process. In others, it is handled by an in-kernel thread.
- Provide explicit facilities for coordination. Some operating systems (including VMS) provide support for exclusive device access by enabling a process to allocate an idle device and to deallocate that device when it is no longer needed
Useful Kernel Data Structures
Tips of C Programming in Kernel
Since there are no standard C library provided in kernel, you should know the kernel alternatives/implemented
Functions
printkprintk(KERN_INFO "Message: %s\n", arg);
kmalloc- the flag you should often use is
GFP_KERNEL - from the library
linux/slab.h
- the flag you should often use is
Structures
- Linked List
include/linux/list.h
Defining System Calls
Essentially, to build a system call, you would need to:
- Configure it in Kernel Files
- Program your System Call in the right Format
- After compiling your file, use the system call with
syscall()
So, first, to configure it in the right places:
-
Configuration in system table
arch/x86/entry/syscalls/sysycall_64.tbl436 common pstrace_enable __x64_sys_pstrace_enable -
Add header files if needed inside
include/linux/xxx.h -
Put your code in
kernel/xxx.cand wrap your code like this:#include <linux/syscalls.h> SYSCALL_DEFINE3(pstrace_get, pid_t, pid, struct pstrace __user *, buf, long __user *, counter) { return 0; } -
Add your
.cfile to theMakefileof kernelobj-y = fork.o exec_domain.o panic.o \ cpu.o exit.o softirq.o resource.o \ /* some code omitted here */ pstrace.o -
then, to program your code with right style:
-
careful of copying to and from users
SYSCALL_DEFINE3(pstrace_get, pid_t, pid, struct pstrace __user *, buf, long __user *, counter) { long kcounter; struct pstrace *kbuf; kbuf = kmalloc(sizeof(struct pstrace) * PSTRACE_BUF_SIZE, GFP_KERNEL); if (!kbuf) return -ENOMEM; if (copy_from_user(&kcounter, counter, sizeof(long))) return -EFAULT; read_lock(&tasklist_lock); /* do some tasklist related stuff */ read_unlock(&tasklist_lock); if (copy_to_user(buf, kbuf, sizeof(struct pstrace) * cp_count)) { kfree(kbuf); return -EFAULT; } kfree(kbuf); return 0; } -
use available kernel functions if there is
- the trick here is to think:
- is there a user function/C library function that does this? e.g.
getpid() - look for the kernel files, see what is beneath
SYSCALL_DEFINE0(getpid)
- is there a user function/C library function that does this? e.g.
/* instead of tsk->pid */ SYSCALL_DEFINE0(getpid) { return task_tgid_vnr(current); } - the trick here is to think:
-
Finally, to use the system calls:
#include <errno.h> #include <stdio.h> #include <unistd.h> ret = syscall(__NR_SYSCALL_PSTRACE_ENABLE, pid); if (ret) fprintf(stderr, "err: %s\n", strerror(errno));
More details on copy_to_user and the other ones:
Copy Data to/from Kernel
Function Description copy_from_user(to, from, n)_copy_from_userCopies a string of n bytes from from(user space) toto(kernel space).get_user(type *to, type* ptr)_get_userReads a simple variable (char, long, … ) from ptr to; depending on pointer type, the kernel decides automatically to transfer 1, 2, 4, or 8 bytes.put_user(type *from, type *to)_put_userCopies a simple value from from(kernel space) toto(user space); the relevant value is determined automatically from the pointer type passed.copy_to_user(to, from, n)_copy_to_userCopies n bytes from from(kernel space) toto(user space).
Defining Compilation Modules
This example talks about the homework of building and compiling your own file system
inside fs/ppagefs
# SPDX-License-Identifier: GPL-2.0-only
ppagefs-objs := inode.o file.o pagewalk.o
obj-y += ppagefs.o
then in fs/Makefile
# SPDX-License-Identifier: GPL-2.0
#
# Makefile for the Linux filesystems.
#
# 14 Sep 2000, Christoph Hellwig <hch@infradead.org>
# Rewritten to use lists instead of if-statements.
# some code omitted here
obj-$(CONFIG_SQUASHFS) += squashfs/
obj-y += ramfs/
obj-y += ppagefs/ # added
Linked List in Kernel
Kernel uses this approach:
struct list_head {
struct list_head *next, *prev;
};
/* this part is made up */
struct my_list_node{
sturct list_head list;
int data;
};
this means that, to traverse between members:
- traverse
list_head
To get the my_list_node structure back for int data from list_head:
- subtract the offset from the address of
list_headto get the address ofmy_list_node- in the above example, the address of
my_list_nodecontaining thelist_headwill be the same address thanlist_head
- in the above example, the address of
- in kernel, this function is the
list_entry()orcontainer_of()function
Advantage of this
- This essentially abstracted the fact that, for any kind of list that needs a
link_head, it can reuse thisstruct
Defining a Linked List
struct fox {
unsigned long tail_length;
unsigned long weight;
bool is_fantastic;
struct list_head list; /* list of all fox structures */
};
struct fox *red_fox;
red_fox = kmalloc(sizeof(*red_fox), GFP_KERNEL);
red_fox->tail_length = 40;
red_fox->weight = 6;
red_fox->is_fantastic = false;
/* initializes the wiring */
INIT_LIST_HEAD(&red_fox->list);
Head Node
Optionally, you can also define a sentinel head node
LIST_HEAD(fox_list); /* defines and initializes a named list. */
which basically does:
struct list_head name = LIST_HEAD_INIT(name)
Adding to a Linked List
list_add(struct list_head *new, struct list_head *head);
list_add_tail(struct list_head *new, struct list_head *head);
for example
list_add(&f->list, &fox_list);
Deleting from a Linked List
list_del(struct list_head *entry) /* This function removes the element entry from the list. */
- This only de-wires, but does not free the memory
- after calling this, you would typically destroy your data structure and the list_head inside it.
For Example:
list_del(&f->list); /* removes f from the list */
Iterating through a Linked List
/* recall
struct fox {
unsigned long tail_length;
unsigned long weight;
bool is_fantastic;
struct list_head list;
};
and that
LIST_HEAD(fox_list);
*/
struct list_head *p;
struct fox *f;
list_for_each(p, &fox_list) {
/* f points to the structure in which the list is embedded */
f = list_entry(p, struct fox, list);
}
Simplified Iteration/Traversing
list_for_each_entry(pos, head, member)
where:
posis a pointer to the object containing thelist_headnodes. Think of it as the return value fromlist_entry()headis a pointer to thelist_headhead node
For Example
static struct inotify_watch *inode_find_handle(struct inode *inode,
struct inotify_handle *ih)
{
/* not list_head any more */
struct inotify_watch *watch;
list_for_each_entry(watch, &inode->inotify_watches, i_list) {
if (watch->ih == ih)
return watch;
}
return NULL;
}
Iterating and removing from a Linked List
Now, you need to use:
list_for_each_entry_safe(pos, next, head, member);
where:
- use this version in the same manner as
list_for_each_entry(), except that you provide thenextpointer, which is of the same type aspos - again,
posis a pointer to the object containing thelist_headnodes. Think of it as the return value fromlist_entry()
For Example
void inotify_inode_is_dead(struct inode *inode)
{
struct inotify_watch *watch, *next;
mutex_lock(&inode->inotify_mutex);
list_for_each_entry_safe(watch, next, &inode->inotify_watches, i_list) {
struct inotify_handle *ih = watch->ih;
mutex_lock(&ih->mutex);
inotify_remove_watch_locked(ih, watch); /* deletes watch */
mutex_unlock(&ih->mutex);
}
mutex_unlock(&inode->inotify_mutex);
}
Red Black Tree in Kernel
All we need to start with it having a root:
#include <linux/rbtree.h>
struct rb_root the_root = RB_ROOT;
where:
RB_ROOTbasically expands to initializing to{ NULL, }
Then, to get the container from the pointer to rb_node, use:
rb_entry(pointer, type, member);
Insert
struct pfn_node {
struct rb_node node; /* for rb tree */
unsigned long pfn;
};
static void pfn_rb_insert(struct expose_count_args *args, struct va_info *lst)
{
struct rb_node **node = &lst->root->rb_node, *parent;
/* new data */
unsigned long new_pfn = lst->new_pfn;
struct pfn_node *tmp;
parent = *node;
/* Go to the bottom of the tree */
while (*node) {
parent = *node;
tmp = rb_entry(parent, struct pfn_node, node);
if (tmp->pfn == new_pfn)
return; /* duplicate */
if (tmp->pfn > new_pfn)
node = &parent->rb_left;
else
node = &parent->rb_right;
}
tmp = kmalloc(sizeof(struct pfn_node), GFP_KERNEL);
tmp->pfn = new_pfn;
/* Put the new node there */
rb_link_node(&tmp->node, parent, node);
rb_insert_color(&tmp->node, lst->root);
/* some code omitted here */
}
Traverse and Free the Tree
Idea of DFS traversal with iterative version:
- Create an empty stack
S. - Initialize current node as root
- Push the current node to S and set current = current->left until current is NULL
- If current is NULL and stack is not empty then
- Pop the top item from stack.
- Print the popped item, set current = popped_item->right
- Go to step 3.
- If current is NULL and stack is empty then we are done
void free_pfn_rb_tree(struct rb_root *root)
{
struct rb_node *curr;
struct list_head stack;
struct list_rb_node *tmp;
int done = 0;
INIT_LIST_HEAD(&stack);
if (!root->rb_node) /* by default, an empty rb-tree has root->rb_note = NULL */
return;
/* clone a root for freeing */
curr = kmalloc(sizeof(struct rb_node), GFP_KERNEL);
*curr = *(root->rb_node);
/* iterative DFS */
while (!done) {
if (curr) { /* 1. walk left continuously */
tmp = kmalloc(sizeof(struct list_rb_node), GFP_KERNEL);
INIT_LIST_HEAD(&tmp->head);
tmp->rb = curr;
list_add_tail(&tmp->head, &stack);
curr = curr->rb_left;
} else { /* 2. on leaf node, go to the right */
if (!list_empty(&stack)) {
tmp = list_last_entry(&stack, struct list_rb_node, head);
/* 2. moves to the right */
curr = tmp->rb->rb_right;
list_del(&tmp->head); //pop
kfree(tmp->rb); // removes left most
kfree(tmp);
} else {
done = 1; /* 5. stack empty, done */
}
}
}
}
HashMap in Kernel
Useful Things to Know
Setting up Serial Log for VM
In general:
Also here are some general debugging tips:
-
Enable kernel debugging:
make menuconfig Go to Kernel hacking -> Compile-time checks and compiler options -> Compile the kernel with debug info Press "/" to enter search mode Type "RANDOMIZE" Press "1" to choose "RANDOMIZE_BASE" Press "n" to diable it Choose "Exit" once Press "/" to enter search mode Type "RANDOMIZE" Press "2" to choose "RANDOMIZE_MEMORY" Press "n" to diable it Choose "Exit" until save and exit -
Enable debugging for spinlock(see here):
make menuconfig
Press "/" to enter search mode
Type "DEBUG_SPIN"
Press "1"
Press "y" to enable spinlock debugging
-
Attach a serial console to your VM
Go to setting for the VM -> Add Device -> Serial Port -> Choose a place to put the log(if you are using macOS, you can save it with .log extended name and use application “Console” to monitor it in realtime)
-
When you suspect you are in a deadlock, check the serial port log to see if there’s something printed out.
Note
make w4118_defconfigthen follow Xuheng’s instruction. Most importantly, don’t forget to do this first during menuconfigGo to Kernel hacking -> Compile-time checks and compiler options -> Compile the kernel with debug info- Randomize Memory: after
RANDOM_BASEis disabled,RANDOMIZE_MEMORYshould be disabled automatically. If not, disable “Randomize the address of the kernel image(KASLR)” in Processor type and features.- name the file attached to the serial port with
.logsuffix- update grub config:
- per the comment in piazza, we need to add
console=ttyS0 ignore_loglevel(ttyS0 worked for me, from ttyS0 to ttyS10, there should be one that works) to the optionGRUB_CMD_LINE_LINUXin/etc/default/grub. (see picture below)sudo update-grubto enable the changes you just made
Expanding VM Disk
- Shutdown your VM.
- In VM settings, choose the virtual hard disk you are using for the VM and expand the size(40-50GB would be enough).
- Boot your VM.
- Open a terminal and
sudo fdisk /dev/sda- Enter
p, you should see something like/dev/sda1 - Enter
d, you should seePartition 1 has been deleted - Enter
nto create a new partion and enterpto select primary partition, the rest are default - You should see warnings like
Partition #1 contains a ext4 signature. - Enter
Ydo delete the signature - Enter
ato set bootable flag on partition 1 - Enter
wto write all the changes - Reboot your VM
- Login to your VM and use
sudo resize2fs /dev/sda1 - Use
df -h /dev/sda1, you should see your disk is now expanded.
Checkpatch.pl
git diff 7dc5355b6 -- linux/ | perl linux/scripts/checkpatch.pl --ignore FILE_PATH_CHANGES,SPDX_LICENSE_TAG
where:
-
contents/code we are checking are
git diff 7dc5355b6 - we are checking the
linux/directory for errors - script id located at
linux/scripts/checkpatch.pl