COMS3157 Advanced Programming
- Logistics
- Week 1
- Week 2
- Week 3
- Week 4
- Week 5
- Week 6
- Week 7
- Week 8
- Week 9
- Week 10
- Week 11
- Week 12
- Week 13
- Week 14
- Miscellaneous
Logistics
-
Office hours:
- Jae’s office hours
- TA office hours
- https://calendar.google.com/calendar/u/0/embed?src=75136mi2i4kn31s4ullcc2dtio@group.calendar.google.com&ctz=America/New_York&pli=1
-
Four online but synchronous exams
- Thu 10/15, 4:10pm: Exam 1
- Thu 10/29, 4:10pm: Exam 2
- Thu 11/19, 4:10pm: Exam 3
- Tue 12/8, 4:10pm: Exam 4
- No final exam
There are no make-up or alternate exams. If you cannot make any of those exams, please take the course next semester.
For more details on logistics, see http://www.cs.columbia.edu/~jae/3157/files/00-overview.pdf?asof=20200908
In general, see http://www.cs.columbia.edu/~jae/3157/
- ListServ emails
- [cs3157]
- all emails will have this tag
- [ANN]
- important announcements
- [LABn]
- information relevant to a particular lab
- [cs3157]
Week 1
UNIX CLI Basics
- First, we need to know that labs are finally submitted to a server hosted by google, which is called CLAC by AP
- this means that you probably need to SSH/SSH client
ssh -X youraccount- the
-Xmeans x-forwarding, which means displaying GUI on your machine but runs in the server - see more with the file Linux Programming Environment
- the
- before the account of the above is delivered to you, you can try using the
cunixaccount which Columbia delivers to every studentssh xy2437@cunix.columbia.edu- password would be the same as UNI’s password
| Commands Inputs | Sample Outputs | Meaning |
|---|---|---|
pwd |
/ means root directory; the following / are only separators; ~ mean home directory, which is different from root directory |
shows current absolute path |
ls -p |
list the file/folders, appending / if it is a folder |
|
ls -F |
firstProject/ patchedProject/ test.txt 'vim commands.txt' |
slightly different than above |
ls -F -l or ls -Fl |
drwxr-xr-x 3 jasonyux jasonyux 4096 Sep 10 21:20 firstProject/ |
shows long format, including permissions |
ls -a |
list all files, even hidden | |
cd; same as cd ~ |
go to your home directory | |
alias ll='ls -alF' |
this is used to setup ‘shortcuts’. However, those aliases will be forgotten once you close the terminals. Therefore, you need to automatically do it using the file .bashrc |
|
cp <originFile> <targetFile> |
copies the original file to another file called targetFile |
|
vimtutor |
looks at the vim tutorial file | |
diff <file1> <file2> |
computes the difference between two TEXT files | |
cmp <file1> <file2> |
computes the difference between two files, including a BINARY file | |
Ctrl+r |
then type something |
search in your command history that contains the string something |
locate <someFileName> |
search in your computer for that file | |
cat -tn |
cat, but replaces \t tab characters explicitly with ^I, and show line numbers |
Note:
.xxx, or called dot files, have the convention to be not visible withls, unless you specify-a
- this is a convention initiated from the UNIX system
- UNIX refers to the operating system that comes from UNIX, for example LINUX and MacOS.
Week 2
First, our simple program
#include <stdio.h>
int main(){
printf("hello, world\n");
return 0; // exit code = convention that things went well
}
where:
- we do NOT need a class
Compiling and Linking
If you compile a program with
gcc <somefile>.c
the default output is a.out
- unless you specify
-o <outputFileName>.out
Then, to run the .out program, you need to:
./<filename>.out
because:
UNIXby defaults looks at your system path variable for executables. The executable under the current directory is not added to path, hence need to specify full path of that executable- The PATH variable is an environment variable that contains an ordered list of paths that Unix will search for executables when running a command. Using these paths means that we do not have to specify an absolute path when running a command.
Yet this is not a good practice, as `gcc` without any option does both compiling and linking
The good practice is to:
-
Compile ONLY
gcc -c <yourFile>.cwhere:
- you get a file with
.o, which is an object file. This is not an executable
- you get a file with
-
Linking
gcc <yourFile>.owhere:
- you are feeding in an object file
- This still produces
a.out- if you specify
-o <someName>, you can change the name froma.outto<someName>.out
- if you specify
Extension
- An object file is the real output from the compilation phase. It’s mostly machine code, but has info that allows a linker to see what symbols are in it as well as symbols it requires in order to work. (For reference, “symbols” are basically names of global objects, functions, etc.)
- A linker takes all these object files and CAN combine them to form one executable (assuming that it can, ie: that there aren’t any duplicate or undefined symbols).
Linking
Now suppose you have two files:
#include <stdio.h>
void main(){
printf("hello, world\n");
printf("Function in another file %d",myAdd(3000,167));
}
and
int myAdd(int x, int y){
return x+y;
}
you can first:
- Compile both of them with
gcc -c - Link both into one executable
- what actually happens is:
- the compiler checks, just by name, if the function
myAddis defined- the only place where link error can occur
- concatenate/include that definition into the executable. Job done.
- the compiler checks, just by name, if the function
- what actually happens is:
gcc <file1>.o <file2>.o -o <someName>
And in the end the executable runs.
Declaring a Prototype
You can specify, during compilation process
-g- generate and embed debug information
-Wall-Wmeans show warning, and-Wallmeans show all warnings
Notice that the above compilation of an explicit function myAdd() gets complained:
hello.c:10:39: warning: implicit declaration of function ‘myAdd’ [-Wimplicit-function-declaration]
10 | printf("Function in another file %d",myAdd(3000,167));
|
This is fixed by declaring a prototype/signature of a function
- declaring $\neq$ defining, where as the latter actually defines the functionality of a function, the former just declares the existence of a function
#include <stdio.h>
int myAdd(int x, int y); // the prototype
void main(){
printf("hello, world\n");
printf("Function in another file %d",myAdd(3000,167));
}
But what about the function printf(), which has not been declared anywhere yet functions?
#include
The line in the above example:
#include <stdio.h>
means:
- tells the compiler to first find the file named
stdio.h- the symbol
<>refers to the system directory, which means search the filestdio.hin the system’s directory - if you want to search in the current directory, use
"".
- the symbol
- textual replace/include the content of that file at the position
#includeduring the compilation stage
Note:
- This has nothing to do with
importin languages such as Java.
Header File
A header file is a file with extension .h which contains C function declarations and macro definitions to be shared between several source files.
- it should not contain actual function definitions.
For example, you can break the above two pieces of code:
#include <stdio.h>
int myAdd(int x, int y); // the prototype
void main(){
printf("hello, world\n");
printf("Function in another file %d",myAdd(3000,167));
}
and
int myAdd(int x, int y){
return x+y;
}
into three pieces of codes
-
#include <stdio.h> #include "myadd.h" void main(){ printf("hello, world\n"); printf("Function in another file %d",myAdd(3000,167)); } -
int myAdd(int x, int y); // myadd.h -
int myAdd(int x, int y){ // myadd.c return x+y; }
But still, then printf is only declared but not defined.
Standard Library
Like Java, where some functions are within the standard library to be automatically imported in a class when needed, the compiler of C do the same job:
- first, it looks at the functions declared but not defined
- then, it looks for those functions in its standard library
libc.a- if that function is there, then link it automatically when linking with
gcc <someFile>.o -o <outputFile> - if not, error
- if that function is there, then link it automatically when linking with
Note:
Sometimes linking error might happen when the standard library for math functions (
libm.a). In that case, you need to manually link it withgcc <someFile>.o <otherFile>.o -o <someName> -lmwhere:
the
-lstands for standard librarythe
mstands for theminsidelibm.a
Compiling
The stage of compilation has nothing to do with checking if a specific content is defined. It just cares if the syntax is correct, or if a specific function is declared.
- Checks if the methods are declared correctly
- this includes first match the function by name
- then, check number of parameter and return type
- this means you cannot have functions of the same name but with different number of parameters
- this includes first match the function by name
- If correct, replace those header files and compile.
Extension
- function overloading is a feature of a programming language that allows one to have many functions with same name but with different signatures. This feature is present in most of the Object Oriented Languages such as C++ and Java. But C (not Object Oriented Language) doesn’t support this feature.
This means at the compilation stage, if you compile
#include <stdio.h>
#include "myadd.h"
void main(){
printf("hello, world\n");
printf("Function in another file %d",myAdd(3000,167));
}
There will be no error, as at compilation stage, the two #include made sure that all functions are declared, even if you haven’t wrote the actual function myadd(int x, int y) anywhere.
- it is always up to the linking stage to actually get things defined
Linking Problem
The gcc compiler links the function only by name.
This means that it will match declaration and definitions in the following successfully:
-
#include <stdio.h> #include "myadd.h" void main(){ printf("hello, world\n"); printf("Function in another file %d",myAdd(3000,167)); } -
int myAdd(int x, int y, int salt){ // myadd.c // matches by name, even if argument does not return x+y+2*salt; } -
int myAdd(int x, int y); // myadd.h
Therefore, if you compile each functions, they all work because technically there is no error for compilation.
Linking also works because linking only link by name.
If you actually run the executable, you will get erroneous results even if it runs.
This is generally because you only made a **1-way contract**, the implementation of the `myadd.h` should also fill in the contract
Solution:
-
Change into:
#include "myadd.h" int myAdd(int x, int y, int salt){ // myadd.c return x+y+2*salt; }and a compilation error occurs because a compiler:
- see a match for the function name
myadd - looks at its number of parameters, mismatch
- error
- see a match for the function name
Makefile
Basically a configurable shortcut to automate the compilation/linking process with gcc.
This uses a make command.
-
it looks for and parse the content in the file
Makefile, which contains instructions on how to compile and link -
similar to
docker-compose
In general, the Makefile takes the following format:
<targetFile>: <sourceFiles> <dependency>
<commands to execute>
<targetFile2>: <sourceFiles2> <dependency>
<commands to execute>
.PHONY: <target3> <target4>
<targte3>:
<commands to execute>
<targte4>:
<commands to execute>
Simple Example
For example, instead of needing to compile:
gcc -c -Wall -g hello.c
You can do:
-
Create and edit a file with name
Makefilehello.o: hello.c gcc -c -Wall -g hello.cwhere:
- you actually use tabs instead of spaces, which makes a difference there
-
run
make
Making Multiple Targets
If you have two targets or more, make by default does not execute all the scripts for you. Its only mission is to execute the first target successfully.
To execute other targets, you need to specify make <targetName>
For example:
hello.o: hello.c
gcc -c -Wall -g hello.c
myadd.o: myadd.c
gcc -c -Wall -g myadd.c
and the execute with
make myadd.o
However, what if some of its source files are missing for a job?
Suppose you only have:
*-
|- myadd.c
|- hello.c
|- myadd.h
and your Makefile looks like:
main: main.o myadd.o
gcc main.o myadd.o -o main
hello.o: hello.c
gcc -c -Wall -g hello.c
myadd.o: myadd.c
gcc -c -Wall -g myadd.c
Now, if you execute make, you will get:
makelooks at the first goalmain, and realize that its ingredients are goals themselves- in this case, those files are missing. So first it checks if ingredients can be made by
makeitself- if yes, proceed
- if not, error, abort
- if its ingredients are modified, but make has the goal
- it will remake the file if the timestamp has been updated
- in this case, those files are missing. So first it checks if ingredients can be made by
makethose missing ingredients- “recursively”
makethe first goalmain
Managing Dependencies
The last problem with the above piece of code remains in the part:
hello.o: hello.c
gcc -c -Wall -g hello.c
where:
- this would not recompile if
myadd.hgets changed
To solve this, we need to explicitly make this an ingredient/dependency, even though we are not using it:
hello.o: hello.c myadd.h
gcc -c -Wall -g hello.c
and this completes the above example.
Variables
You can also use variables in Makefile
CC = gcc
CFLAGS = -Wall -g
hello.o: hello.c myadd.h
${CC} -c${CFLAGS} hello.c
In fact, make by default works smartly to know what you want to do by looking at the ingredient file types.
It deduces that:
CC = gcc
CFLAGS = -Wall -g
hello.o: hello.c myadd.h
and make will execute the following
${CC} -c${CFLAGS} -o hello.o hello.c
where:
CCandCFLAGSare special variables thatmakewill insert automatically if it detects that you are dealing with a C program.
.PHONY
By default, Makefile targets are “file targets” - they are used to build files from other files. Make assumes its target is a file, and this makes writing Makefiles relatively easy.
However, sometimes you want your Makefile to run commands that do not represent physical files in the file system.
- If you do have a target file produced,
makewill only run it when the file doesn’t appear to be up-to-date with regards to its dependencies.
These special targets are called phony and you can explicitly tell Make they’re not associated with files, e.g.:
.PHONY: clean
clean:
rm -rf *.o
Now make clean will run as expected even if you do have a file named clean.
In terms of Make, a phony target is simply a target that is always out-of-date, so whenever you ask make <phony_target>, it will run, independent from the state of the file system.
Full Example
Following contains the full example of a Makefile:
# This Makefile should be used as a template for future Makefiles.
# It’s heavily commented, so hopefully you can understand what each
# line does.
# We’ll use gcc for C compilation and g++ for C++ compilation
CC = gcc
CXX = g++
# Let’s leave a place holder for additional include directories
INCLUDES =
# Compilation options:
# -g for debugging info and -Wall enables all warnings
CFLAGS = -g -Wall $(INCLUDES)
CXXFLAGS = -g -Wall $(INCLUDES)
# Linking options:
# -g for debugging info
LDFLAGS = -g
# List the libraries you need to link with in LDLIBS
# For example, use "-lm" for the math library
LDLIBS =
# The 1st target gets built when you type "make".
# It’s usually your executable. ("main" in this case.)
#
# Note that we did not specify the linking rule.
# Instead, we rely on one of make’s implicit rules:
#
# $(CC)$(LDFLAGS) <all-dependent-.o-files> $(LDLIBS)
#
# Also note that make assumes that main depends on main.o,
# so we can omit it if we want to.
main: main.o myadd.o
# main.o depends not only on main.c, but also on myadd.h because
# main.c includes myadd.h. main.o will get recompiled if either
# main.c or myadd.h get modified.
#
# make already knows main.o depends on main.c, so we can omit main.c
# in the dependency list if we want to.
#
# make uses the following implicit rule to compile a .c file into a .o
# file:
#
# $(CC) -c$(CFLAGS) <the-.c-file>
#
main.o: main.c myadd.h
# And myadd.o depends on myadd.c and myadd.h.
myadd.o: myadd.c myadd.h
# Always provide the "clean" target that removes intermediate files.
# What you remove depend on your choice of coding tools
# (different editors generate different backup files for example).
#
# And the "clean" target is not a file name, so we tell make that
# it’s a "phony" target.
.PHONY: clean
clean:
rm -f *.o a.out core main
# "all" target is useful if your Makefile builds multiple programs.
# Here we’ll have it first do "clean", and rebuild the main target.
.PHONY: all
all: clean main
Week 3
# in C
In the previous section #include, we have seen how this gets processed first by the compiler and texts are replaced into that line.
In general, the symbol # means preprocessing
- so that before the actual compiling happens, the compiler first looks at those
# - process the lines below (if needed) until a new
#is met
#define
Another example other than #include would be #define, which can basically be understood as textual replacement done by the compiler
- quite a close analogy
For example:
#include <stdio.h>
#define PI 3.14 // first encountered
int main(){
printf("defined %f\n",PI); // replaces PI with 3.14
#define PI 3.15 // then encountered
if(-37){
printf("redefined %f\n",PI); // replaced PI with 3.15
printf("other variable %f\n",PI2); // unknown PI2 even if defined next, because this happens at the fly
#define PI2 3.16
}
}
// gets compiler error
A more interesting example of using define is for ‘functions’:
#define SQR(x) x*x
...
SQR(3) // gets replaced to 3*3, which WORKS
SQR(3+4) // gets replaced to 3+4*3+4, which is WRONG
Hence, in general, MACROS with #define are discouraged
#ifdef/#ifndef/#else/#endif
A sample usage would be making a proper header file:
#ifndef __MYADD_H__ // if NOT previously defined __MYADD_H__, execute the code within the if/endif
#define __MYADD_H__ // an empty definition
int myadd(int,int);
#endif // end the code within the if/endif
where:
.are not allowed, hence we used_as replacements__MYADD_H__is just a conventional name using the filename. In theory it can be anything unique.- the purpose of this is to prevent multiple textual replacements of the header file
Mechanism explanation:
- first in the preprocessor step in the compilation process, the first time its contents are reached the first two lines will check if
__MYADD_H__has been defined for the preprocessor. - If not, it will define
__MYADD_H__and continue processing the code between it and the#endifdirective. - If the check against
#ifndef __MYADD_H__is false, it will immediately scan down to the#endifand continue after it. This prevents redefinition errors.
This should always be how you define the header files.
Data Types in C
-
charThis is basically a 8-bit integer/1-byte
- therefore this is defined within the range $-128 \sim 127$
-
shortBasically a 16-bit integer/2-bytes
- therefore in the range $-32768 \sim 32767$
-
int/signed int/int32_tBasically a 32-bit integer
- since signed, it is in the range of $-2G \sim 2G-1$
- where:
- $2^{10}=1024=1K$
- $2^{20}=2^{10}\times 2^{10}=1M$
- $2^{30}=1G$
- since signed, it is in the range of $-2G \sim 2G-1$
-
longTypically a 64-bit integer/8-bytes. But for older OS, long might be just 4-bytes.
-
long longForces it to be 64-bit integer/8 bytes.
In all the above, we have signed version by default. All of them also have an unsigned version, if you specify:
unsigned charunsigned int/uint32_t- etc.
You can the unsigned version.
Single Quote vs Double Quote
In other programming language such as Java, there is no big difference between the two as representing Character/String. In C, the rules are below:
- Single Quote
'a'refers to the integer value of the character according to the ASCII table- for example,
int y = 'a'+1which is97+1=98
- for example,
- Single Quote
'\013'refers to the octal system, which here is11- you can have up to three bits after the slash
- hence
'\0'==0, but'\0'!='0', where the ASCII table shows'0'=48

- Double Quote
"abc"are only compatible with Strings.
Expression
Expressions are basically values that get computed from an expression.
- for example:
5,x+1,prime(5)which returns aboolean- assignments
=, like in Java are also expressions - for example:
(x=1)+2actually makes the expression evaluate to3
- assignments
Every expression also has a type.
- for example:
int
Statement
Every expression can also be seen as statements, but statements typically include ;, or any compound expression with {}.
- for example,
x=x+1;is a statement, yet it also contains the expressionx=x+1
Exam Note
Question: Does the following code has the same output?
int x,y;
x=10;
y = x++ + 2;
int x,y;
x=10;
y = (x++) + 2;
Solution:
They are the same. The brackets () only defines the order of operation, without influencing the operations themselves.
- you can think of this being a way to tell the machine which piece of code to execute first
Operators in C
Operators in C include basically the same ones as in Java, but some have different return types.
==
The comparison operator in C returns int, namely:
1if it is true0if it is false
However, every int value that is not 0 is the same as true.
For example:
#include <stdio.h>
int main(){
if(-37){ // is true
printf("%d", 10);
}
}
Bitwise Operators in C
Basically operators that work if arguments are treated as binary numbers.
& and |
Notice that instead of && and || which is logical and and logical or.
int x=1;
int y=2;
int z;
z=x|y; // z=3
z=x&y; // z=0
where:
- first the values of
xandyare converted to the 32-bit binary int - then the bitwise operators are applied
<< and >>
<< left shift basically shifts digits to the left, and >> right shift basically shifts digits to the right
- this is true for unsigned integers
// if we have unsigned integers
unsigned int z=1;
unsigned int y=2;
z = z<<2; // z=4
y = y>>2; // y=0
where:
- left shift is basically multiplying by
2^n, wherenis the number of digits shifted - right shift is basically dividing by
2^n, wherenis the number of digits shifted- simple to understand if you think about decimal system
if we have signed integers/2’s complement, then:
- left shift is the same
- right shift fills in the leftmost blanks with the original leftmost digit
- in order to preserve the sign (think about decimal system)
For example:
int y=-2; // same as saying signed int y=-2;
y = y>>1; // 11111111111111111110 (assumes 31 times 1) -> 111111111111111111 (assumes 32 times 1) = -1
~
This is basically the not operator for binary numbers.
- it basically flips
1to0, and0to1
Sample Combinations
x = x&(1<<4)- picks out the 4th bit of the binary number
x
- picks out the 4th bit of the binary number
x = x|(1<<4)- turn on the 4th bit of the binary number
x
- turn on the 4th bit of the binary number
x = x&~(1<<4)- turn off the 4th bit of the binary number
x
- turn off the 4th bit of the binary number
Operator Associativity
Associativity in this context refers to the order of operation when you are met with operators of the same precedence.
For most operators, evaluations are done left to right
int y = 2+3-5;
However, for assignment =, it actually goes right to left
int y = x = 5; // first gets x=5, then gets y=5 (as x=5 evaluates to 5).
Variable Scope
Local Variable
Basically any normal variables used in methods. This is slightly different from Java, which is stricter in one key aspect:
- In C, if a variable is already defined in a code block:
- you can define/declare another variable of the same name, overriding that variable
- In Java, if a variable is already defined in a code block:
- you cannot define/declare a variable of the same name
They are also called stack variables, since they are usually stored in process stack (we’ll see what this means later)
For example:
char a = 'a';
printf("character %c\n",a);
{
char a = 'b'; // allowed, and hides the variable char a = 'a' in the outside
printf("character %c\n",a); // prints b
}
but in Java:
char a = 'a';
System.out.println(a);
{
char a = 'b'; // compile error
System.out.println(a);
}
Static Variable
There are three kinds of static variables:
- Global Static
- created/initialized before program runs
- lives for the lifetime of the entire program
- visible to all other files at link time
- this is the only variable that might be name conflicted with other global variables when you have multiple files
- File Static
- created/initialized before program runs
- lives for the lifetime of the entire program
- visible only to this file, before being linked
- Function Static
- created/initialized before program runs
- lives for the lifetime of the entire program
- visible only to this function
For static variables, they must be initialized with a literal/value. In other words, you cannot have static int x= y*2, which will throw compile error.
- this is because, in fact, all those variables are initialized/created at the beginning of the program, before anything runs
This is best illustrated with an example
int global_static = 0; // visible to other files, static in all files
extern global_static2 = 0; // this is technically the same as above, but could creates confusion
// so this style is discouraged
static int file_static = 0; // only visible within this file, static in this file
int foo(int auto_1){
static int function_or_block_static = 0; // only visible in this block, static to this block
...
int localvariable = 0; // the normal local variable
...
}
where:
- notice that you need to define those static variables with a constant
Global Static Variable
Of course, the actual value of a global variable is known cross-file only at link time.
Therefore, you need to manually tell the compiler that a variable is meant to be global in another file, with the keyword extern.
- just like linking method from different files, compilers need to know them beforehand
For example:
// inside main.c
int x = 5; // global variable
int main(){
int z; // local variable
x = x+1;
printf("%d",x);
return 0;
}
and then:
// inside foo.c
extern int x; // tells the compiler this is external
int foo(){
return x=x+2;
}
where:
- for global variables, you need to be careful of name collision of other global variables from other files
File Static Variable
The only difference between any of the three static variables are their scope (i.e. all of them are created before the program runs).
For a file static variable, it is only visible in the same file.
For example:
// inside bar.c
static int x = 5; // file static variable, ONLY visible within THIS FILE
int f1(){
return x;
}
Function Static Variable
Again, the same principle, but only visible in the same function.
- together with the other static variables, they get initialized before the program runs
For example:
int f(){
static int count = 0; // function static variable
// lives outside this function, but visible only inside this function
count++;
return count;
}
int main(){
int s=0;
for(int i=0; i<10; i++){
s += f();
}
printf("%d\n",s); // prints 55 = 1+2+3...+10
}
Week 4
Process Address Space
Every single process (i.e., a running program/executable) gets 512GB of memory space, some of which is then mapped to your RAM:
- Obviously, computers don’t have that much RAM. It’s virtual memory!

where:
- sizes of static variables and program code are known/fixed
-
sizes of stack and heap CAN grow/shrink, as it depends on how your program runs
- the program code refers to the executable you have in the end
Note:
Although the stack goes from top to bottom, actually what variable gets stored first is controlled by your operating system.
for example:
int i = 0; int d = 3.14;and it might be that
dis stored at a higher memory thani:&i is 0x7fff6289abec &d is 0x7fff6289abf0 // the above +4
Extension:
- Every memory cell contains 1 byte. This means that a 32-bit integer would use up 4 bytes = 4 memory cells.
- The bit number for CPU (e.g. 64-bit CPU), means how many bits it can read simultaneously from your RAM. If you have a 64-bit CPU, you can read 8 bytes at a time.
Virtual Memory vs Physical Memory
This is the technique used modern days to prevent memory allocation collision of multiple different programs.
- consider one program needing memory location
2000and the other also2000
To solve all the above issues, this is what happens:

where:
- each actual usage in the virtual memory gets transported/mapped to a space in your physical memory
- no memory allocation collision occurs because the mapping makes sure you are allocated the correct physical spot
Extension:
Virtual memory uses both computer hardware and software to work. When an application is in use, data from that program is stored in a physical address using RAM. More specifically, virtual memory will map that address to RAM using a memory management unit (MMU). The OS will make and manage memory mappings by using page tables and other data structures. The MMU, which acts as an address translation hardware, will automatically translate the addresses.
If at any point later the RAM space is needed for something more urgent, the data can be swapped out of RAM and into virtual memory. The computer’s memory manager is in charge of keeping track of the shifts between physical and virtual memory. If that data is needed again, a context switch can be used to resume execution again.
While copying virtual memory into physical memory, the OS divides memory into pagefiles or swap files with a fixed number of addresses. Each page is stored on a disk, and when the page is needed, the OS copies it from the disk to main memory and translates the virtual addresses into real addresses.
However, the process of swapping virtual memory to physical is rather slow. This means that using virtual memory generally causes a noticeable reduction in performance. Because of swapping, computers with more RAM are seen to have better performance.
Stack vs Heap

For example:
// The size of memory to be allocated is known to compiler and whenever a function is called
int main()
{
// All these variables get memory
// allocated on stack
int a;
int b[10];
int n = 20;
int c[n];
}
but:
int main()
{
// This memory for 10 integers
// is allocated on heap.
int *ptr = malloc(sizeof(int)*10);
}
Hierarchy Example
Having the notion of the hierarchy would be useful. For example:
int main(){
...
char *buffer = malloc(20);
int larger = (char *)buffer < (char *)&buffer; // gives 1
}
The reason being the address of stack are generally higher up than address of heap:

where:
- the above also shows another double pointer, but all we need to notice is that the address of stack variables are always higher than address of heap variables, which is always higher than address of code variables.
Pointers
Pointers is a group of storage cells (in total 8 byte=8 cells) that holds a memory address as data.
- one byte in memory address could hold data such as a
char, for example - 8 byte is also the largest primitive type you can have
long long(though it has nothing to do with this, use it for mnemonic)
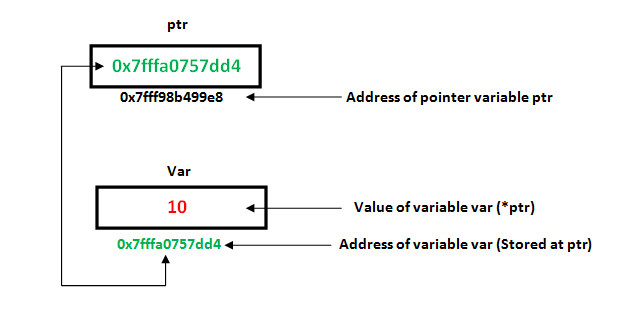
where:
- hexadecimal is used
- difference of 1 in memory address corresponds to 1 byte.
Related Operators
Common related operations include:
&gives the address of an object from a variable- you cannot use a
&with a literal or an expression - effectively add a
*to a type- e.g.
int x=5;then&xis typeint *
- e.g.
- you cannot use a
*dereferences the address (goes to the actual address)- also used to instantiate a pointer
- effectively peel a
*off from a type- e.g.
int *y = &x, then*yis typeint
- e.g.
Therefore, common operations include:
int x = 1, y = 2;
int *p; // p is a pointer variable
int *q;
p = &x; // that holds an address of an int variable
// p++ would increase the memory location itself
y = *p; // y is now the data p points to, which is 1
*p = 0; // the data p points to, which is x, is now 0
p = &y; // p now points to y
*p = 2; // the data p points to, which is y, is now 2. x is still 0
q = p; // q points to p, which is the memory address of y
++*p; // ++(*p), y is now 3
(*p)++; // y is now 4. Note that * and ++ go right-to-left.
where in the above example:
- variable
pis just the memory address *pcan be read as the datappoints to
Pointer Data Type
Every pointer is constrained to point to a particular kind of object.
- you can imagine the compiler needs to know if that pointer is calling the correct methods
This is necessary because the type tells the pointer:
- how much bytes to read from that address
- what operations are allowed
- how much bytes to advance with pointer arithmetic
- see the section Generic Pointer
For example:
#include <stdio.h>
int main(){
double i = 3.14;
int j = (int) i;
double *dp = &i;
int *ip = (int *)dp; // casting a double pointer to an int pointer
// prints 3
printf("j=%d\n", j);
// prints 1374389535
printf("*ip = %d\n", *ip);
// prints 1.37439e+09, basically the above as a double
printf("*ip = %g\n", (double)*ip);
}
where:
- the wrong number comes out because
double *is expected to read 8 bytes, butint *reads only 4 bytes.
Note:
- Even though pointers are just storing memory addresses, and they are just integers/numbers, doing things like
char *c = 10is forbidden by the compiler. The only exception is the value of0. (see section Null Pointer)
Pointers and Function Arguments
Since C passes arguments to functions by value, if you need to alter states of a variable in a function, you need to take pointers as parameters.
void swap(int x, int y); // wrong
void swap(int *x, int *y); // correct
and you use the correct one like:
int a=5;
int b=6;
swap(&a, &b); // pass memory locations to them
Double/Nested Pointers
Basically, if you have understood everything correctly, this should make sense:
#include <stdio.h>
int main(){
int var = 789;
int *ptr1;
int **ptr2;
ptr1 = &var; // address of var
ptr2 = &ptr1; // address of ptr1
printf("Value of var = %d\n", var );
printf("Value of var using single pointer = %d\n", *ptr1 );
printf("Value of var using double pointer, single derefernce = %p\n", *ptr2);
printf("Value of var using double pointer, double derefernce = %d\n", **ptr2);
}
And below would be the schematic:

Generic Pointer
Consider using void * as a pointer. Every pointer type can be assigned to this pointer.
- However, you cannot dereference it. Because the compiler does not know
voidmeans how many bytes to read. - So, before dereferencing it, you need to cast it.
For example, this is allowed:
int a = 10;
char b = 'x';
void *p = &a; // void pointer holds address of int 'a'
p = &b; // void pointer holds address of char 'b'
With GCC compiler, this is also allowed:
#include<stdio.h>
int main()
{
int a[2] = {1, 2};
void *ptr = a;
int *ptr2 = a;
ptr = ptr + sizeof(int); // instead of ++, because void pointer does not know the type
ptr2++;
// both prints 2
printf("sizeofint=%ld ,%d\n", sizeof(int), *(int *)ptr); // type casting is needed for dereferencing
printf("sizeofint=%ld ,%d\n", sizeof(int), *ptr2);
return 0;
}
where:
- typecasting is always needed if you want to dereference a
voidpointer - pointer arithmetic has to be done manually since
void *does not know its type, hence doesn’t know how much cells/bytes to advance. voidpointer arithmetic may not work with other compilers
Null Pointer
A null pointer basically a pointer pointing to 0 or NULL.
- where
0is a special int value that can be automatically converted to a pointer type (null)
For example:
char *q = 0;
int *p = NULL;
And graphically, it looks like:

where:
- even though it looks like just having one byte, every pointer is of 8 bytes
If you try to dereference a null pointer, you will get runtime errors:
*p; // segmentation error
Pointers to T/F
In C, every pointer themselves can be evaluated to “true” of “false”.
- every non-null pointer is “true”
- every null pointer is “false”
For example:
char c = 0;
char *d = &c;
char *e = 0; // null pointer
if(d){ // evaluates to true, non-null pointer
...
}
if(*d){ // the VALUE 0 is false
...
}
if(e){ // evaluates to false, null pointer
...
}
if(*e){ // program crashes, segmentation error
...
}
sizeof
The built-in function of C that returns the number of bytes that variable is using.
For example:
char d[4] = {97,98,99,0};
sizeof(d); // gives 16 = 4*4
sizeof(d[0]); // gives 4
char *e;
sizeof(e); // gives 8
Pointer Arithmetic
One common expression in C is to deal with pointers/memory address directly.
Consider the example:

int val[7] = {11,22,33,44,55,66,77};
int *p = &val[0]; // points to 11
p = p+1; // this is equivalent to:
// p = p + sizeof(*p), in terms of bytes
*p; // this is now 22
where:
- this also explained why casting of a pointer does not work well, and why arithmetic of
voidpointers would be more cumbersome if you use GCC compiler (+1would be advance by 1 byte).
Theorem:
In an array
a, if a pointerppoints to the first element of it, then:*(p+i) = a[i]
Adding and Subtracting Pointers
First, in general, adding/subtracting a pointer with/from another pointer would just be doing arithmetic directly on the address (also scaled by the type of the pointer)
Consider two pointers:
int val[7] = {11,22,33,44,55,66,77};
int *p1 = val+1; // points to 22
int *p2 = val+4; // points to 55
where:
- doing address arithmetic usually only makes sense if we are pointing to the same continuous memory location. However, if you are certain exactly where each memory address is, you can also do arithmetic on different pointers as long as they are the same type
- notice that the hard restriction by compiler is actually the pointers have to be of the same type
Now, obviously doing:
int diff = p2 - p1; // gives 3, meaning 3 cells of int away
Therefore, in general, address arithmetic for pointers work as:
\[p_2 - p_1 = \frac{\text{address of $p_2-$ address of $p_1$ }}{\text{size pointer type}}=\text{#elements away}\]For example:
char *a[4] = { "", "A", "BC", "DEF" };
int diff = (char *)a[2] - (char *)(a+1); // gives 1
Arrays
To instantiate an array in C, you do:
type name[];
// for example
int a[10];
int b[10] = { -1,2,3 }; // b[3] - b[9] are initialized to zero
int c[] = { 1,2,3 }; // same as int c[3] = { 1,2,3 }
// notice that in C, char is 1 byte. In Java, char is 2 bytes
char d[4] = {97,98,99,0};
char e[4] = {'a','b','c','\0'}; // same as above
Now, in your memory space, arrays are guaranteed to be allocated to contiguous blocks/cells.
For example:
int val[7] = {11,22,33,44,55,66,77};
where:
- each memory location differ each other by 4 bytes, which is precisely the size of
int
“Pointing” to an Array
You cannot point to a type array directly, but you can point to the first element of an array.
For example:
int val[7] = {11,22,33,44,55,66,77};
int *p = &val[0]; // points to the first element in the array
// so basically p holds the value 88820
Therefore, looping over the array would be:
for(int i = 0; i<7; i++){
printf("%d\n",*(p+i));
}
// or, you could have
for(int i = 0; i<7; i++){
printf("%d\n",*p);
p++;
}
// the more terse way
for(int i = 0; i<7; i++){
printf("%d\n",*p++); // ++ binds more tighly then *
}
where:
- in the first case, your pointer still points to the beginning of the array
- in the second and the last case, your pointer will point pass the end, which is allowed in C
Automatic Type Conversion of Array
In most of the cases, when you use/pass an array, the array will be automatically converted to a pointer pointing to the first element.
For example:
int a[10] = {0,1,2};
int *p = a; // same as *p = &a[0];
// and you can also do
a+1; // same as &a[0]+1 = p+1 = a[1]
*a; // same as *p
But in some rare cases, arrays are just arrays:
sizeof(a); // returns 40 instead of 8
sizeof(p); // returns 8
Theorem:
In most cases, when you have an array
a:// passing around a around means // a => &a[0] = p
- the only few exceptions would be the
sizeof().
Passing Array into Functions
In short, you CANNOT pass arrays int a[] into functions. What happens automatically is the conversion to from a => &a[0]
Therefore, whenever you have a method/function:
void f1(int a[10]){
...
printf(sizeof(a)); // prints 8 = size of pointer
}
void f2(int *a){
...
printf(sizeof(a)); // prints 8 = size of pointer
}
int *f3(int *a){
...
return a; // return an int pointer
}
void main(){
int a[10] = {1,2,3,4,5};
printf(sizeof(a)); // prints 40 = size of actual array
f1(a);
f2(a);
}
where:
- You cannot return arrays as well. You can only return pointers.
- As you have noticed, the size information would be lost to any other method than the one you declared the array.
Grand Unified Theory of Arrays
And in general:
Grand Unified Theory:
Since arrays
aare most often automatically converted to pointers, we have*(p+i) = a[i] // same as *(a+i) = a[i] // same as *(p+i) = p[i]Therefore, this means for any array
x:*(x+y) = x[y]For machines, all it uses is the LHS expression all the time
*(x+y)
Therefore, corollaries take place easily:
Corollaries:
This means that:
*a = *(a+0) = a[0] *p = p[0] = a[0]
And this also means that:
Corollaries:
This also means that:
a[0] = 0[a]; // because 0[a] = *(0+a) = *(a+0) = a[0]is allowed (obviously discouraged).
Heap
Basically, stack memory are also called function stack, because when functions finish executing, those memories get removed.
However, what if we want to have a persistent memory block across functions?
This is done by storing data inside your heap:
// notice the return type
int *foo(){
int *p;
p = malloc(10*sizeof(int)); // memory allocate 40 bytes in heap
// notice you can use AN EXPRESSION inside malloc
return p;
}
int main(){
int *a = foo(); // fetches that array in the heap
}
where:
malloc()returns an address/pointer to the first cell memory/byte.
**Note**:
- The key difference between using a
staticversion of it and usingmallocin heap is thatmalloccan dynamically determine its sizes at RUNTIME (therefore allowing expressions), butstaticrequires it to know at COMPILE TIME (therefore requiring literals/values).
And this is what happens:

where:
pwent away as function stack finished, but the array survived since we made it to the heap.
Now, because storage in your heap is persistent, whenever you finished using it, you need to free your memory:
int main(){
int *a = foo();
...
free(a); // free the memory
}
where:
free()takes an address/pointer.
Note:
- If you finished executing your program, all spaces will get cleaned automatically.
- If you did not finish the program, but lost the handle to heap memory, then you have a memory leak because you cannot
free()it anymore.
Theorem:
- You cannot return a pointer to a local variable in a function/method. If you actually need that, you need to use
malloc().
String
There is no type string in C. The only type that holds such data is exactly a char array.
- This is in fact the same in Java, as Java implements a
Stringusing achararray, but C does not implement it.
However, the only difference for the compile to tell between a string and a char array is that:
- a string is a
chararray ending with character\0, which is called a null character- how the end of a string is defined
- if you use a literal, use
""
For example:
char c[4] = {'a','b','c','\0'};
// is the same as, and vice versa
char d[4] = "abc";
//but
char *pmessage = "now is the time";
// is different from
char amessage[] = "now is the time";
where:
- the last case is special with string, because
"abc"literal will be immediately converted tochar *pwhich points to the first char"a".- the only case where you have a string and not use a pointer is the first and second line in the above example.
This is what actually happens:

where:
- obviously
pmessagewill NOT be mutable - but
amessagewill be mutable
Therefore, to advance in your pointer’s string, you do:
// prints "hello"
printf("%s", "hello"); // prints the first char in the pointer, then moves on, until hitting the \0
// prints "ello"
printf("%s", "hello"+1); // prints the second char in the pointer, then moves on, until hitting the \0
where:
- in fact,
printf(), and with most functions in C, they automatically converts thearraydata type to apointerof that data type- e.g.
int c[]becomes typeint *to the first element
- e.g.
Empty String
By the design of C for string, an empty string would be:
// both are empty strings
char empty[] = "";
char empty[] = {'\0'};
where:
- notice that it technically has a content, but it is just directly the end of the string.
Example: String Copy
Consider the following program:
int main(){
char t[4];
char *s="abc";
strcpy(t,s); // t gets automatically converted to char *, because it is an array
}
void strcpy(char *t, char *s){
while((*t=*s)!=0){
t++; // address advances
s++; // address advances
}
}
// however, a cleaner way to write it is:
void strcpy(char *t, char *s){
// *t++ is the same as *(t++)
while((*t++=*s++)!=0); // the only substle difference is that the ending pointer actually points pass the "array"
}
where:
- notice that the pointers passed in
tandsare a new copy of the original pointers. Everything passed in a function is a copy/value.- this means the external
tandsin themain()function is not altered
- this means the external
and this is what happens under the hood:

where:
- notice how scope is also illustrated in the above diagram
Safer String Copy
However, how does your program know if you have allocated the correct space for it?
Consider the case:
int main(){
char t[2];
char *s="abc";
strcpy(t,s);
}
If we used our previous method, then C will simply overwrite useful data beyond the storage of t. This might crash your program.
Therefore, a safer version of it would be:
strncpy(char *t, char *s, size_t n); // where size_t is an unsigned integer telling it the upper limit to write to
Example: String Concat
Another example of clean code would be concatenating a string to the end.
Consider:
void main(){
char t[6]; // having the correct size makes sure space are allocated correctly beforehand
char *s="abc";
strcpy(t,s);
strcat(t, "ab");
}
void strcat(char *t, char *s){
while(*t) t++;
strcpy(t,s);
}
Safer String Concat
Similar to the String copy, you have the same problem. Therefore, there is a safer alternative:
strncat(char *t, char *s, size_t n); // where size_t is an unsigned integer telling it the upper limit to write to
Command Line Arguments
Basically you need to variables to get those command line arguments: argc and argv.
This is how you write a program that takes command line arguments.
- a variable
int argcthat tells you how many arguments are executed - a variable
char **argvthat gives you a pointer to the first element in an array, each element of which contains an string (char []).
Now, consider this call:
echo hello, world

where:
argcis of size 3*argvis of size 4
Extension:
- whenever you execute things like
echo helloin your terminal, all the arrayargvandargcwill be handled by your OS and given to you.
And your program would look like:
int main(int argc, char **argv){
argv++; // moves the pointer/memory location forward
while(*argv){ // the last element is 0, hence will be false
printf("%s", *argv++);
}
}
Week 5
Reading: K&R2, chapters 5 and 6
const
Basically, any variable that is made const cannot be changed. This is a good alternative to #define.
For example:
const int CONST_VALUE = 10;
CONST_VALUE = 11; // throws compiler error
The more interesting usage is using const with a pointer:
const char *t- this means the value that
tpoints to cannot change, e.g. you cannot do*t = 'a'; - this essentially made the data
tpoints to become read-only
- this means the value that
char const *t- this means that the pointer
tcannot change, e.g. you cannot dot++.
- this means that the pointer
For example:
-
Question:
How do you implement a safer
strcopy()function usingconst? -
Solution:
void strcopy(char *t, const char *s){ // therefore, pointer s is made read-only while((*t++ = *s++)!=0); } int main(){ char *a = "ABC"; char b[4]; strcopy(a,b); // works, as char * can always be treated as const char * }
However, there is a trick to remove const by casting:
void strcopy(char *t, const char *s){ // here s is read-only
char *s2 = (char *)s; // casting to make s2 not read-only
while((*t++ = *s2++)!=0); // now you can modify the value of s using s2, though not shown here
}
where:
- obviously this is not a good practice, but sometimes/rarely it is used/necessary.
Note:
- This means that you can pass
char *directly intoconst char *, i.e. you can be more restrictive.- But you cannot (will get a warning) pass
const char *intochar *, i.e. you cannot be less restrictive.- Making a variable
constdoes not change the memory location of the variables (does not move them to read-only). It is just a restriction that compiler checks.
Pointers to Functions
An example of it would be to consider the quicksort implementation of C:
void qsort(void *base, size_t nmemb, size_t size,
int (*compar)(const void *, const void *));
where:
-
void *baseis the pointer to the first member of the array size_t nmembbasically describes the number of members in the array- the type
size_tis basically anintorunsigned_long
- the type
size_t sizedescribes the byte size of each element- this is needed since that array is
void *, being generic
- this is needed since that array is
int (*compar)(const void *, const void *)is a pointer to a function calledcomparwhich compares the elements you are putting in- this means that functions also have type:
int (*)(const void *, const void *)
- this means that functions also have type:
and to use it, you need to have the following:
int compareInt(const void *a, const void *b){
int x = *(int *)a;
int y = *(int *)b;
return x-y;
}
int main(){
int a[5] = { -1,0,100,-27,2 };
qsort(a, 5, 4, &compareInt); // notice the &compareInt
}
where:
- you are passing in a pointer to a function
- the address of your function is stored in your code section (below heap)
Parsing a Pointer Function
Basically, to see what is happening, you need to use the counter-clockwise spiral out rule. The simple version:
Consider:
+-------+
| +-+ |
| ^ | |
char *str[10];
^ ^ | |
| +---+ |
+-----------+
-
you start with the name, which is
str, then:stris … -
We move in a spiral clockwise direction starting with
strand the first character we see is a[so, that means we have an array, so…stris an array of size 10 of… -
Continue in a spiral clockwise direction, and the next thing we encounter is the
*so, that means we have pointers, so…stris an array of size 10 of pointers to… -
Continue in a spiral direction and we see the end of the line (the
;), so keep going and we get to the typechar, so…stris an array of size 10 of pointers tochar -
We have now “visited’’ every token; therefore we are done!
Now, the example of a pointer function:
+--------------------+
| +---+ |
| |+-+| |
| |^ || |
char *(*fp)( int, float *);
^ ^ ^ || |
| | +--+| |
| +-----+ |
+------------------------+
-
you start with the name, which is
fp, then:fpis a… -
Moving in a spiral clockwise direction, the first thing we see is a
); therefore, sincefpis inside parenthesis, so we need to continue the spiral inside the parenthesis and the next character seen is the*, so…fpis a pointer to… -
We are now out of the parenthesis and continuing in a spiral clockwise direction, we see the
(; therefore, we have a function, so…fpis a pointer to a function passing an int and a pointer to float returning… -
Continuing in a spiral fashion, we then see the `*’ character, so…
fpis a pointer to a function passing an int and a pointer to float returning a pointer to… -
Continuing in a spiral fashion we see the
;, but we haven’t visited all tokens, so we continue and finally get to the typechar, so…fpis a pointer to a function passing an int and a pointer to float returning a pointer to achar
Now, try yourself and figure out what this is:
int *f1 (const void *v1, const void *v2);
- this is a normal function, that returns
int *
then:
int (*f2) (const void *v1, const void *v2); // a variable/function pointer called (f2), that returns (int)
- this is a pointer function, which we have shown before
For example:
-
Question:
What is this?
int (*f3[5]) (const void *v1, const void *v2); -
Solution:
Basically,
f3is an array of size 5 that contains pointers to functions with argumentsint (*f3[5]) (const void *v1, const void *v2);and returns anint.- basically 5 functions placed into an array
Using a Function Pointer
Now, if you have the method:
void qsort(void *base, size_t nmemb, size_t size,
int (*compar)(const void *, const void *)){
// using that function compar
int compare = *compar(2,5); // comparing 2 and 5
}
However, since all you can do with a function pointer involves first dereferencing it, C provides the shortcut:
void qsort(void *base, size_t nmemb, size_t size,
int (*compar)(const void *, const void *)){
int compare = compar(2,5); // same effect as above
}
where:
- this shortcut only works for function pointers
End of Midterm 1 Material
inline Functions
Inline Function are those function whose definitions are small and be substituted at the place where its function call is happened. Function substitution is totally compiler choice.
- for the GCC compiler, it does not inline replace any
inlinefunctions when not optimizing. To force the substitution, you need to usestatic inlineso the compiler is forced to look at it. - the advantage of this is that it will be faster, as the object code is directly placed inside the main function, hence there is no overhead when calling a function.
- the disadvantage is the file size.
For example:
// Inline function in C
// inline int foo() does not work
static inline int foo()
{
return 2;
}
int main()
{
int ret;
// inline function call, ret becomes 2
ret = foo();
printf("Output is: %d\n", ret); // prints 2
return 0;
}
Week 6
Reading: K&R2, chapters 5 and 6
struct
Basically like classes in Java, but you cannot actually build a method in struct.
- basically, it will merely be a collection of data/primitives/objects.
For example:
// defines a new type
struct Pt{
double x;
double y;
}; // notice this semi-colon
int main(){
struct Pt p1 = {1.1, 2.2};
double x1 = p1.x; // will be 1.1
// a pointer would also be fine on struct Pt
struct Pt *q1 = &p1;
x1 = (*q1).x; // makes x1 to be 1.1
}
where:
- the new type is
struct Pt - you can also initialize that
structby laying out its input in orderstructsin C do not automatically initialize themselves to values such asnull.
- notice that the field
.binds more tightly than dereferencing*
However, it is quite cumbersome to access its member via (*q1).x, so a shortcut is:
x1 = (*q1).x;
x1 = q1->x; // the same as above
Notes:
- To access fields of a
struct, use.- To access fields of a pointer to a
struct, use->.
Inside struct
As we have said before, struct is just the conglomeration of its constituent fields.
- The size of a
structis basically the size of its constituents:
struct Pt p1 = {1.1, 2.2};
printf("%lu\n", sizeof(p1)); // returns 8+8=16 bytes
where:
- basically shows that a
structis basically a conglomeration of its fields on the stack.
Extension:
- Sometimes, the size of a
structmaybe larger than the size of its fields, and a padding(s) will be added. However, this is machine/CPU dependent. Some machines do not add paddings, but some does.
- The pointer to the
structwill be the same as the pointer to its first field.
struct Pt p1 = {1.1, 2.2};
struct Pt *q1 = &p1;
// below prints the same address
printf("%p\n", q1);
printf("%p\n", &q1->x); // same as &(q1->x)
where:
- the same address is printed, even though they have a different pointer type
- therefore, pointer arithmetic and pointer dereferencing will also operate differently
For example:
struct Pt p1 = {1.1, 2.2};
struct Pt *q1 = &p1;
// below prints different address
printf("%p\n", q1); // prints 0x7ffd1749a300
printf("%p\n", q1+1); // prints 0x7ffd1749a310 = advanced 16 bytes, because it is HEX
printf("%p\n", (&q1->x)+1); // prints 0x7ffd1749a308 = advanced 8 bytes
where:
+1to astructpointer will then move past the entirestruct=8+8=16bytes+1to adoublepointer will obviously only increment8bytes
struct variables
One syntax that is allowed but not used often is the following:
struct Point{
...
}x, y;
This is simply analogous to having:
int x,y,z;
where:
- obvious the only different is that we have a different type.
you could basically treat the above as the same thing and do:
struct Point{
double x;
double y;
} x={1.0,2.0}, maxPt={5.0,5.0};
where:
- the
xfield inside thestructhas nothing to do with thexvariable outside. - it is also syntactically allowed because
x.xis clear that the outerxis referring tostruct Point.
Example: LinkedList
Basically, the struct Node itself is trivial:
struct Node{
struct Node *next;
int val;
}
createNode()
First, we need to create a node:
struct Node *createNode(int x){
struct Node *node = malloc(sizeof(struct Node));
if(!node){
return NULL;
}
node->val = x;
node->next = NULL;
return node;
}
where:
- notice that
malloc()returned avoid *, and we made it astruct Node *. This means that for C, everystruct/Object is just a piece of memory. And it is for the programmer to decide how to use that memory by casting it into a specific type.
And if you consider in your main():
int main(){
struct Node *node = createNode(10);
assert(node); // see next section
// free(node);
}
Schematically, this is what happens:

where:
- in the end, we need to of course remember to
free()the memory in heap
assert()
This is basically a handy function to use for testing:
- whenever the expression inside the bracket is
false, it quits the program- e.g.
assert(1==2);will basically quit your program at that line every time
- e.g.
A sample usage with the above LinkedList would be:
int main(){
struct Node *node = createNode(10);
assert(node); // aborts the program if node is false/null/0
free(node);
}
where:
- this needs the library
assert.h
create2Nodes()
This is not a standard function in a LinkedList, but it is a good exercise:
struct Node *creat2Nodes(int x, int y){
struct Node *n2 = malloc(sizeof(struct Node));
if(!n2){
return NULL;
}
n2->val = x;
n2->next = NULL;
struct Node *n1 = malloc(sizeof(struct Node));
if(!n1){
free(n2); // at this point, n2 is malloced already
return NULL;
}
n1->val = x;
n1->next = n2;
return n1;
}
where:
- one line to take care would be
n1->next=n2;, which takes the address ofn2, which points to the beginning of its ownstruct Node, and copied ton1->next.- therefore, now
n1->nextpoints to the beginning of noden2.
- therefore, now
Then, to visit the nodes, you can have:
int main(){
struct Node *head = create2Nodes(10,20);
assert(head);
printf("%d --> %d\n", head->val, head->next->val); // prints 10 -> 20
}
where:
- remember,
head->nextis typestruct Node *which points to the beginning of the second node
Lastly, to free() the memories correctly:
int main(){
struct Node *head = create2Nodes(10,20);
assert(head);
printf("%d --> %d\n", head->val, head->next->val);
free(head->next); // free the second one first
free(head);
}
where:
- if you freed the
headfirst, then you never get the reference to the second node anymore- this will cause permanent memory leak
Extension:
This means an efficient algorithm for freeing the LinkedList would be actually first saving the next value:
int freeLinkedList(struct Node *head){ struct Node *saved=head->next; while(saved){ free(head); head=saved; saved=saved->next; } free(head); }
struct as Value
An interesting different between struct in C and class in Java is that struct only contains fields/data.
- This means, when we are passing in/returning a
structinto functions, it passes/returns in by value:
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
struct Pt{
double x;
double y;
};
struct Pt makePoint(double x, double y){
struct Pt temp = {x,y};
// this returns by VALUE!, even though temp disappeared
return temp;
}
int main(){
struct Pt p2 = makePoint(3.0,4.0);
printf("%f and %f\n",p2.x, p2.y); // actually printed 3.0 and 4.0
}
where:
tempwas a local variable, which disappeared after the function call. However,returning astructin C means returning by the values in thatstruct.- as a result, you can imagine
{3.0, 4.0}was returned, and that becomes the content ofp2.
- as a result, you can imagine
- Therefore, other related operations such as assigning also are done by value:
// same code omitted from above
int main(){
struct Pt p1 = makePoint(3.0,4.0);
struct Pt p2 = p1;
printf("%p and %p\n", &p1, &p2); // 0x7ffcf9bf7f50 and 0x7ffcf9bf7f40
}
where:
- again, this shows that even
=copies thestructby value. You get two distinctly differentstructin Stack Memory but having the same value.
Exam Notes
-
Question:
Draw the diagram for the code below, and tell me the output.
struct Node { void * data; struct Node *next; } struct List{ struct Node *head; } struct Node* node1 = ... // assume this is correct struct List list[1]; list->head = node1;and what would be the output of the below:
list.head *list list[0].head -
Solution:

where:
- in the end, there are only four piece of data in the entire program
- note that both
listand&listwould be0X0A, which is the memory address of the first element in the arraylistmeans pointer to astruct List&listmeans pointer to the entirestruct List []- array is nothing than a contiguous block of memory
and output are:
list.head # gives ERROR *list # gives type struct List (actually, value stored by variable `head`) list[0].head # gives type struct Node * (actually, value stored by variable `head`)
Week 7
Standard IO
The C standard library automatically provides every running program with 3 I/O channels
stdin(standard input)fd=0:- incoming character stream, normally from keyboard
- e.g. when you called
scanf(), it takes the content fromstdin
stdout(standard output)fd=1:- outgoing character stream, normally to terminal screen
- buffered until newline comes or buffer is filled
- e.g. unless your call with
printf()has\n, it is first buffered (so if your program crashed, and you didn’t have\n, nothing might be printed)
- e.g. unless your call with
stderr(standard error)fd=2:- outgoing character stream, normally to terminal screen
- unbuffered
- e.g. will immediately show up in your terminal screen if you called
fprintf()
- e.g. will immediately show up in your terminal screen if you called
Redirection
Basically, you can imagine your keyboard input being replaced by contents of a file.
- You can have
stdincome from (<) a file instead of the keyboard:-
#isort is an executable taking an stdin number using `scanf()` #file_containing_a_number contains a number ./isort < file_containing_a_number
-
Note:
If you have more than one number in the file, and your program does:
int main(){ int x; scanf("%d",&x); }Then
scanf()will only read and take the part of the content that is continuous until met a white space
-
And have
stdoutgo to (>) a file instead of the screen:-
./isort > my_sorting_result
-
-
Finally, use
2>to redirectstderrto a file:./isort 2> myerrors
For example, now you could combine the redirections:
./a.out < myinput > myoutout
where:
- first
./a.out < myinput - then outputs and overwrite the content in
myoutout
However, if you want to append instead of overwrite:
-
Use
>>to append to an existing file:./a.out < myinput >> myoutout
Redirecting Valgrind
Now, a typical valgrind looks like:
valgrind --leak-check=yes ./isort
<mark>410</mark> Memcheck, a memory error detector
<mark>410</mark> Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al.
<mark>410</mark> Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info
<mark>410</mark> Command: ./isort
<mark>410</mark>
3
original: 2 78 56
ascending: 2 56 78
descending: 78 56 2
<mark>410</mark>
<mark>410</mark> HEAP SUMMARY:
<mark>410</mark> in use at exit: 0 bytes in 0 blocks
<mark>410</mark> total heap usage: 5 allocs, 5 frees, 2,084 bytes allocated
<mark>410</mark>
<mark>410</mark> All heap blocks were freed -- no leaks are possible
<mark>410</mark>
<mark>410</mark> For lists of detected and suppressed errors, rerun with: -s
<mark>410</mark> ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
where:
- every line starting with
<mark>410</mark>is actuallystderr 3is thestdin- all the rest are
stdout
Therefore, if you redirect stdout only, then you will only see the content:
valgrind --leak-check=yes ./isort > myout
#inside myout
original: 2 78 56
ascending: 2 56 78
descending: 78 56 2
Hence, to redirect stdout and stderr, you can:
-
place them to two different files:
valgrind --leak-check=yes ./isort > myout 2> myerrors#inside myout original: 2 78 56 ascending: 2 56 78 descending: 78 56 2#inside myerrors <mark>410</mark> Memcheck, a memory error detector <mark>410</mark> Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al. <mark>410</mark> Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info <mark>410</mark> Command: ./isort <mark>410</mark> <mark>410</mark> <mark>410</mark> HEAP SUMMARY: <mark>410</mark> in use at exit: 0 bytes in 0 blocks <mark>410</mark> total heap usage: 5 allocs, 5 frees, 2,084 bytes allocated <mark>410</mark> <mark>410</mark> All heap blocks were freed -- no leaks are possible <mark>410</mark> <mark>410</mark> For lists of detected and suppressed errors, rerun with: -s <mark>410</mark> ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0) -
place them into the same file:
valgrind --leak-check=yes ./isort > myfinalout 2>&1where:
2>&1means redirect2=stderrin the same manner to the same place of1=stdout.
#inside myfinalout <mark>410</mark> Memcheck, a memory error detector <mark>410</mark> Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al. <mark>410</mark> Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info <mark>410</mark> Command: ./isort <mark>410</mark> original: 2 78 56 ascending: 2 56 78 descending: 78 56 2 <mark>410</mark> <mark>410</mark> HEAP SUMMARY: <mark>410</mark> in use at exit: 0 bytes in 0 blocks <mark>410</mark> total heap usage: 5 allocs, 5 frees, 2,084 bytes allocated <mark>410</mark> <mark>410</mark> All heap blocks were freed -- no leaks are possible <mark>410</mark> <mark>410</mark> For lists of detected and suppressed errors, rerun with: -s <mark>410</mark> ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0) -
Therefore, if we want to append instead of overwrite:
valgrind --leak-check=yes ./isort >> README.txt 2>&1where:
- now
stdoutis appended toREADME.txt stderr=2is done in the same manner (also appended), to the same place ofstdout=1(the same fileREADME.txt)
- now
perror
This is a handy library method by C, such that it, by default (with no arguments:)
void perror(const char *s);
- produces a message on standard error describing the last error encountered during a call to a system or library function.
The powerful thing is that if you supply it with an argument:
perror("additional info");
it will output in stderr:
additional info: whatever message perror had
where:
- your additional message automatically gets placed into the error message with
additional info:
Pipeline
A pipe connects stdout of one program to stdin of another program:
prog1 | prog2 | prog3
- a common example would be using
cat:- e.g.
cat myinput | ./isort - above will have the same effect as
./isort < myinput
- e.g.
- and
grep <text>, which only prints out the line containing the wordtext- e.g.
cat myinput | ./isort | grep original - above produces
original: 2 78 56
- e.g.
For example:
-
Question:
Are the below two lines doing the same thing?
prog1 < input_file | prog2 | prog3 > output_file cat input_file | prog1 | prog2 | prog3 > output_file -
Solution:
Yes.
Tail
This is another handy command to only see stdout after a certain line
- if you want to see
stdoutbefore a certain line, usehead
By default, tail takes in content of from stdin, and outputs the last 10 lines of that stdin to the stdout.
-
the useful option is:
-n, --lines=[+]NUM output the last NUM lines, instead of the last 10; or use -n +NUM to output starting with line NUMwhere:
- line number here starts from 1.
Therefore, to see the lines starting from line 3:
valgrind --leak-check=yes ./isort 2>&1 | tail -n +3
where:
- since pipeline only works with
stdout, we need to redirect what we wantedstderrfirst tostdout, and then pipe it
The output becomes
<mark>441</mark> Copyright (C) 2002-2017, and GNU GPL'd, by Julian Seward et al.
<mark>441</mark> Using Valgrind-3.15.0 and LibVEX; rerun with -h for copyright info
<mark>441</mark> Command: ./isort
<mark>441</mark>
3
original: 10 19 80
ascending: 10 19 80
descending: 80 19 10
<mark>441</mark>
<mark>441</mark> HEAP SUMMARY:
<mark>441</mark> in use at exit: 0 bytes in 0 blocks
<mark>441</mark> total heap usage: 5 allocs, 5 frees, 5,156 bytes allocated
<mark>441</mark>
<mark>441</mark> All heap blocks were freed -- no leaks are possible
<mark>441</mark>
<mark>441</mark> For lists of detected and suppressed errors, rerun with: -s
<mark>441</mark> ERROR SUMMARY: 0 errors from 0 contexts (suppressed: 0 from 0)
where:
-
the first two line skipped where:
valgrind --leak-check=yes ./isort <mark>444</mark> Memcheck, a memory error detector
End of Material for Midterm 2
File IO
ncat
The code looks like:
/*
* ncat <file_name>
*
* - reads a file line-by-line, printing them out with line numbers
*/
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv)
{
if (argc != 2) {
// notice this fprintf, takes an extra argument FILE *
fprintf(stderr, "%s\n", "usage: ncat <file_name>");
exit(1);
}
char *filename = argv[1];
FILE *fp = fopen(filename, "r");
if (fp == NULL) {
perror(filename);
// exit would be equivalent to return 1 in main, but it is more proper
exit(1);
}
char buf[100];
int lineno = 1;
while (fgets(buf, sizeof(buf), fp) != NULL) {
// a potential bug here is that if I did't have enough buffer, I would only have a partial line
// therefore, it will print partial lines to the output file
printf("[%4d]", lineno++);
if (fputs(buf, stdout) == EOF) {
perror("can't write to stdout");
exit(1);
}
}
if (ferror(fp)) {
perror(filename);
exit(1);
}
// don't forget to free the handle to the file in the end
fclose(fp);
return 0;
}
where:
fprintf(stderr, "%s\n", "usage: ncat <file_name>");- prints the content to
stderr
- prints the content to
FILE *fp = fopen(filename, "r");- open the file with read mode, and work with it
- see the section
fopen - and the
FILE *is an opaque handle
exit(1)- will terminate the entire program (not only the method)
Note:
This also means that the following to line are equivalent:
fprintf(stdout, "%s\n", "usage: ncat <file_name>"); printf("%s\n", "usage: ncat <file_name>");The above also means the below two are also the same:
int x; fscanf(stdin, "%d", &x); scanf("%d", &x);
fopen
Signature looks like:
FILE *fopen(const char *filename, const char *mode)
- Opens a file, and returns a
FILE*that you can pass to other file-related functions to tell them on which file they should operate.FILE*is an example of an “opaque handle”.
- mode:
- “r” open for reading (file must already exist)
- “w” open for writing (will trash existing file)
- “a” open for appending (writes will always go to the end of file)
- “r+” open for reading & writing (file must already exist)
- reading will be the primary mode
- “w+” open for reading & writing (will trash existing file)
- writing will be the primary mode
- as you write, you could read what you have written
- “a+” open for reading & appending (writes will go to end of file)
- returns
NULLif file could not be opened for some reason
Opaque Handle
Basically, it involves the use of typedef: used to give data type a new name.
For example:
#include <stdio.h>
// After this line BYTE can be used
// in place of unsigned char
typedef unsigned char BYTE;
int main()
{
BYTE b1, b2; // same as: unsigned char b1, b2;
b1 = 'c';
printf("%c ", b1);
return 0;
}
More useful cases would involve renaming pointer types:
typedef struct tnode *Treeptr
where:
- this means variables such as
Treeptr leftis actually of typestruct tnode *
However, I personally just prefer using:
typedef struct tnode Treeptr
where:
Treeptr *leftis for typestruct tnode *is more intuitive.
Extension:
- A more advanced usage would be
typedef int (*PFI)(char *, char *);, which defines the namePFIas a pointer to a function.
fgets()
Signature looks like:
char *fgets(char *buffer, int size, FILE *file)
- reads at most
size-1 characters intobuffer, or stop reading if newline orEOFis read (those characters are also inserted into the buffer), and terminating thebufferwith\0- since you need to place that
\0, it explains why it only takessize-1 characters
- since you need to place that
- internally, it also keeps track of the position of the current cursor in the file (e.g. which line it read)
- returns
NULLonEOF
- or, error (you can call
ferror()afterwards to find out if there was an error).
Note:
- Never use the similar
gets()function; it’s UNSAFE!
For example, if fgets()is reading the line in a file :
//
- There are three characters in this line:
/,/, and\n(byte number10). - Met
\n, insert/,/, and\nand\0into the arraybuffer- (assumed there are within
size-1 characters, as specified)
- (assumed there are within
fputs()
Signature
int fputs(const char *str, FILE *file)
- writes
strto file (and flushing/clearing the arraystr), without its terminating null byte (\0).- the terminating
\0comes from thefget().
- the terminating
- returns
EOFon error.
This means a standard usage would be:
if(fputs(buf, stdout) == EOF){
perror("can't write to stdout");
exit(1);
}
Note:
- Notice that we passed
stdoutto the typeFILE *. It actually works.- This also means that everything in Linux is a file, such that
stdin/stdout/stderrare just “special” files, or they can be seen as just global variables of typeFILE *
fclose()
Signature:
int fclose(FILE *stream);
- flushes the stream pointed to by stream (writing any buffered output data using
fflush(3)) and closes the underlying file descriptor.- basically, close and free whatever resource you had with that file
Week 8
Formatted IO
First, a few things on the ordinary formatted IO:
// notice the ... in argument
int scanf(const char *format, ...);
int printf(const char *format, ...);
where:
- in fact, both methods accept
varargs.
Extension: Variadic Arguments:
The symbol
...must appear last in the parameter list and must follow at least one named parameter.e.g.
int printx(const char* fmt, ...); // function declared this wayWithin the body of a function that uses variadic arguments, the values of these arguments may be accessed using the
<stdarg.h>:
Defined in header <stdarg.h>Usage va_startenables access to variadic function arguments (function macro) va_argaccesses the next variadic function argument (function macro)
T va_arg( va_list ap, T );Theva_argmacro expands to an expression of typeTthat corresponds to the next parameter from theva_list ap.va_copy(C99)makes a copy of the variadic function arguments (function macro) va_endends traversal of the variadic function arguments (function macro) va_listholds the information needed by va_start,va_arg,va_end, andva_copy(typedef)
and some common conversion specifiers are listed below, which can be used in the functions above:
%d: int
%u: unsigned int
%ld: long
%lu: unsigned long
%s: string (char *)
%f: double
%g: double (trailing zeros not printed)
%p: memory address (void *)
sscanf()
Consider the case when you need to convert a string into an integer.
- for example, convert
char *a = "123";into an int123.
There are two ways to solve it, by formatting/parsing the string:
-
use
atoi(), which means convert a string toint:char *a = "123"; int n = atoi(a); // n=123 -
use the formatted IO
sscanf():char *a = "123"; int n; sscanf(a, "%d", &n); // n=123
And this sscanf() works as:
int sscanf(const char *input_string, const char *format, ...)
which:
- basically read from
input_stringrather thanstdin, and put it in whatever holder/storage you have - in the end, you can convert anything from
char *to anything else
sprintf()
Consider the reverse case, if you need to convert from a number to a string, you use sprintf().
int sprintf(char *output_buffer, const char *format, ...);
- write to
output_bufferrather thanstdoutoutput_bufferbetter be pointing to a large enough memory- this also means
output_bufferhas to be initialized
- this also means
- in the end, it means you can convert anything else to a
char *
For example, you can do:
int n = 456;
char b[100];
sprintf(b, "%d", n);
and now:
bwill look like[52,53,54,0], where'4'=52in ASCII.
Notice:
this also means if you did:
int n = 456; char *b; sprintf(b, "%d", n);there will be error (if you check
valgrind), sincebonw only points to0, and you obviously cannot write456to0pointer.
Buffering on IO
Three types of buffering:
- Unbuffered - typically
stderr - Line-buffered -
stdoutwhen it’s connected to terminal screen- usually, the buffer size is whenever you have
\norEOF
- usually, the buffer size is whenever you have
- Block-buffered - all other files
- usually, the buffer size is
4k byte - this means if you redirected
stdoutto a file, the4kBwill be new buffer size
- usually, the buffer size is
Note:
- The above applies for both ways: both
stdinandstdoutwill be line-buffered. This means that your program will not receive anything fromstdinuntil\norEOFis hit.
- to simulate terminating your program (e.g.
ncat) usingEOF, you can useCtrl+D, which means from inputting anEOFto your program.
This means, that if your program crashed during:
- line-buffering before you put in
\n - block-buffering before
4k Bytedata read
All your work will be gone.
Flushing Buffer
The remedy to the above is to not crash, or flush the buffer manually:
fflush(fp)
- which manually flushes the buffer for
fp(which is aFILE*).
Or, you can turn on the buffer to unbuffered mode, by:
setbuf(fp, NULL)
- which turns off buffering for
fp.- remember,
stdout/in/erris alsoFILE *
- remember,
Standard IO for Binary Files
Consider the LAB4, which basically does the following:
- A program that takes in two strings, your name and your message
- Write the data to an actual binary file (with no extension)
In details:
struct MdbRec{
char name[16]; // so you will have at most 15 char + '0'
char msg[24]; // so you will have at most 23 char + '0'
}
- encapsulates the format of the data that you need to write into your file
This means that, if you put in:
xiao@my-Laptop: ./mdb-add mydatabase jason Hello
where:
jasonwill be mynameHellowill be themsg
then the output file will be:
jason^@^@^@^@^@^@^@^@^@^@^@Hello^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@^@
where:
-
^@means0(null) in VIM jason^@is the actual data written by the program (6 bytes). The following^@10 times (10 bytes) comes from the initialization of thechar []- in total, 16 bytes as required
Hello^@is the actual data written by the program (7 bytes). The following^@17 times (17 bytes) comes from the initialization of thechar []- in total, 24 bytes as required
Opening Binary Files
Now, knowing the basics, we need to know how to write to a file.
First, you need to obtain the FILE * data structure, so that you could work on. To do this you have learnt two ways:
FILE *fp = fopen(filename, "rb");FILE *fp = fopen(filename, "wb");
where:
bstands for binary files.- In UNIX, there is no distinction between text and binary files, so
bhas no effect. - In windows,
bsuppresses newline translations that happens:- when reading, turn “\r\n” into “\n”
- when writing, turn “\n” into “\r\n”
- this also means that for any content it reads/writes, it translates
\n=10to\r=13 \n=10, and vice versa.- therefore, if you are reading binary files, this translation will cause errors
- However, this will be useful if you run your program in a different OS.
- In UNIX, there is no distinction between text and binary files, so
Note:
- Fundamentally, there is no difference between a binary file and a text file (or an image file, or anything). In your hard disk, all those data are just bytes. A binary file have those bytes representing purely binaries, text file having bytes representing ASCII code for characters (images having bytes representing RGB values)
Writing to Binary Files
Then, you need to use to the FILE * to write:
-
Using:
size_t fwrite(const void *p, size_t size, size_t n, FILE *file)- writes
nobjects, eachsizebytes long, from the memory location pointed to bypout tofile. - returns the number of objects successfully written, which will be less than
nwhen there is an error.- e.g. the above example would be to use
fwrite(pToMdbStruct, sizeof(MdbStruct), 1, myDatabase)
- e.g. the above example would be to use
- writes
Reading from Binary Files
Again, first obtain the FILE *, and then use:
size_t fread(void *p, size_t size, size_t n, FILE *file)
- reads
nobjects, eachsizebytes long, fromfileinto the memory location pointed to byp. - returns the number of objects successfully read, which may be less than the requested number
n, in which casefeof()andferror()can be used to determine status.- e.g. if it returned
0from a file with some content, you might need to check withferror()
- e.g. if it returned
Positioning in the File
By default, your FILE * will automatically keep track of the position when you did fread() and/or fwrite(). This means, it will increment the cursor automatically in the file to the next position after reading/writing.
However, if we want to manually skip something, or forcibly place the cursor starting at a particular position, you can use:
int fseek(FILE *file, long offset, int whence)
- Sets the file position for next read or write. The new position, measured in bytes, is obtained by adding
offsetbytes to the position specified bywhence.- If
whenceis set toSEEK_SET,SEEK_CUR, orSEEK_END, the offset is relative to the start of the file, the current position indicator, or end-of-file, respectively.
- If
Week 9
Numeric IDs in UNIX
If you do ll, you see:
drwxr-xr-x 8 jasonyux jasonyux 4096 Oct 30 04:32 cs3157/
and with ll -n, you see your IDs:
drwxr-xr-x 8 1000 1000 4096 Oct 30 04:32 cs3157/
The take home message is this:
- everything in UNIX is just a number/numeric ID. Including your user, group, process IDs, port numbers, etc.
Other example includes ps au, where:
aallows you to see processes in other terminalsuallows you to see user information running those processes- every process (running instance of program) has its unique numeric ID
fork()
This is a very special function, in which it:
- creates a new process by duplicating the calling process.
- The new process is referred to as the child process.
- inside a child process, the
pid_t p = fork()will always be0- this
0is usually indicative of the program being a child process
- this
- inside a child process, the
- The calling process is referred to as the parent process.
- inside the parent process, the
pid_t p = fork()will always be actualpidof the child
- inside the parent process, the
- The new process is referred to as the child process.
For example:
#include <unistd.h>
#include <stdio.h>
#include <stdlib.h>
int main()
{
int i;
pid_t p;
p = fork();
if (p > 0) {
for (i = 0; i < 10; i++) {
printf("Listen to me\n");
sleep(1);
}
printf("I give up...\n");
return 0;
}
else if (p == 0) {
for (i = 0; i < 10; i++) {
printf("No way\n");
sleep(1);
}
printf("Whatever.\n");
return 1;
}
else {
perror("fork failed");
return -1;
}
}
And the output will be:
Listen to me
No way
Listen to me
No way
...
where:
Listen to mecomes from the parent process, since its child process will not be zeroNo waycomes from the child process, since its “child process” will be0
and what happened was:
|
|
main
|
|
fork() ----- (child)
| |
| |
| |
where:
-
everything will get cloned, such that you have two identical pieces in memory:

where:
- e.g. accessing memory location
200in Heap in one does not affect memory location200in another, because now they are two separate virtual memory space
- e.g. accessing memory location
-
however, the child will start running **exactly at the same code level when you called
fork()**-
e.g. if you had:
... printf("What about here?\n"); pid_t p; p = fork(); // child process starts here ...You will only have
What about here?run once by the parent.
-
Interestingly:
- If you call
fork()twice in your main program, you will get4processes.- The most often case that causes
forkto return negative value (error) would be a user reaching the limit of processes it can create.
- this limit is often used for preventing fork bombing.
shell
This will be a limited version of shell:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <sys/wait.h>
#include <sys/types.h>
#include <unistd.h>
static void die(const char *s)
{
perror(s);
exit(1);
}
int main()
{
char buf[100];
pid_t pid;
int status;
printf("AP> ");
while (fgets(buf, sizeof(buf), stdin) != NULL) {
if (buf[strlen(buf) - 1] == '\n')
buf[strlen(buf) - 1] = 0; // replace newline with '\0'
pid = fork();
if (pid < 0) {
die("fork error");
} else if (pid == 0) {
//child process
execl(buf, buf, (char *)0);
die("execl failed");
} else {
// parent process
if(waitpid(pid, &status, 0) != pid)
die("waitpid failed");
}
printf("AP> ");
}
return 0;
}
where:
- inside parent:
if(waitpid(pid, &status, 0) != pid)waits until the process withpidfinishes- then it prints
AP>, and loops
- inside child:
execl(buf, buf, (char *)0)runs the program specified inbuf- you need to end the arguments with
(char *)0, instead of0, becauseexeclis a variadic function:- alike
printf(char *, ...), it assumes all following data are typechar *. So it is the same situation here. - in fact,
int execl(const char *pathname, const char *arg, ...), so you can think of your arguments constructing an “null terminated array” so that the program knows when to end
- alike
- you need to end the arguments with
- in fact
int execl(const char *pathname, const char *arg, ..., /* (char *) NULL */);- the first
bufis basically the path of that executable- since we do not access path variable stored in our system, we need to specify the full path
- so the second
bufis basically theargvarray - the last parameter in
execlshould be a null pointer
- the first
- another special behavior of
execl()is discussed below
In fact:
- this is actually the core of a
bashshell, except that abashshell has all those additional functionalities such as path variable/redirection, and etc.
execl
If you are running a process ls using the execl function, what happens is:
- first, the
execlwill kill the process calling it - then, it will execute the
lsprocess, in place of that killed process- therefore, the
pidis preserved
- therefore, the
- this means you never come back from
execl()to your program, because your child process is entirely replaced with thelsprocess you called- therefore, the only thing you know from the new process
lsprocess is itspidwhen you got fromfork()
- therefore, the only thing you know from the new process
Therefore, if you ran your own shell program above and run ls, the below is what happened.

where:
- the horizontal line would be time
Week 10
netcat
This is basically a program that allows two devices to connect between each other.
- for instance, you can run:
nc -l <portnumber>to listen for connection on port<portnumber>- a server socket
nc <address> <portnumber>to connect- a client socket
- in the end, you will have established a TCP connection. It is a two way connection, such that:
- on the client, it:
- reads
stdinfrom client terminal, and sendsstdoutto the network and to the server terminal (line buffered) - reads
stdoutfrom server terminal if there is
- reads
- on the server, it:
- reads
stdinfrom server terminal, and sendsstdoutto the network and to the client terminal (line buffered) - reads
stdoutfrom client terminal if there is
- reads
- on the client, it:

where:
netcatessentially created a running process on both devices, such that the process only terminates only if one of them terminated
Connecting devices to a Program
The idea is as follows. We have a program running on a computer, called mdb-lookup-cs3157, and we want:
- a remote computer to use this program
This means you want to do the following:
- on a server side
- run
mdb-lookup-cs3157 - transport the input of client side to the server program
- transport the output of the program back to the client
- run
- on the client side
- establish a
netcatsession, and usemdb-lookup-cs3157
- establish a
The difficulty is in the server side, where you have to
pipe output of
netcattomdb-lookup-cs3157, AND- pipe output from
mdb-lookup-cs3157tonetcat- which is essentially forming a loop
Approach 1
Running, on the server side:
$./mdb-lookup-cs3157 < mypipe | netcat -l 8888 > mypipeThere are two problems with it:
Since the first thing that bash executes it
./mdb-lookup-cs3157 < mypipe, sincemypipewill be empty or not even there, the program will quit.Redirection from a normal file is not blocked. i.e. if there is nothing on the file, the redirection just reads
EOFand is done.
- however, pipeline is BIO. This means that it blocks the next command to read from input until there is something on the file, which is different than file IO.
Solution:
Instead of the normal file, we need to use a special file called a named pipe (see section Named Pipe)
Therefore, first we do:
$ mkfifo mypipewhich will create a file that looks like:
xyLaptop$ ll prw-r--r-- 1 jasonyux jasonyux 0 Nov 9 18:13 mypipe|where you see the special pipe
|symbol to tell you that this is a named pipe fileNow, if you do
$ ./mdb-lookup-cs3157 < mypipe | netcat -l 8888 > mypipeit will work, because:
./mdb-lookup-cs3157continues executing by continuingly reading from named pipemypipeis a BIO way, until readingEOFnetcat -l 8888 > mypipealso continues executing untilnetcatfinishesEquivalently:
$ cat mypipe | ./mdb-lookup-cs3157 | netcat -l 8888 > mypipeOr:
$ netcat -l 8888 < mypipe | ./mdb-lookup-cs3157 > mypipe
Named Pipe
mkfifo creates the special file called a named pipe.
- basically, this is a file that act as a pipe, such that it has a BIO mechanism and never has a
EOF(end) until your program finishes- so you could make this a two way pipe
- this also means a named pipe actually flushes its content to the
stoutwhen a program is using it. - Therefore, after executing program finishes, the content of the named pipe should be empty.
This means the following (supposed the named pipe is called mypipe)
- a program reading from
mypipewill be the same as reading from another program - a program outputting to
mypipewill be the same as outputting to another program
Therefore, what happened in the above $ ./mdb-lookup-cs3157 < mypipe | netcat -l 8888 > mypipe is this:

where:
- the order of
mypipeand./mdb-lookup-cs3157does not matter. Both works as long as you are completing the cycle.
Another example:
If you do something like:
$ ./someProgram < mypipe
where:
mypipeis a newly created named pipe./someProgramtakes some input fromstdin
Then your terminal will just hang there, until you do something like:
$ ./someOtherProgram > mypipe
where:
- first, the
stdoutofsomeOtherProgramis buffered to the filemypipe - then,
mypipeflushes the content tosomeProgramasstdin - finally, you will see
./someProgramexecuted something as now it has got some input.
Lastly, both of the above will terminate only one of the program terminated.
- think about it, a normal unnamed pipeline also has this behavior.
Exam 3 Material Ends Here
Internet
The founding basics of the internet is deep. In short, we have several layers of abstraction, such that each layer uses its underneath layers, and in the end produce the internet we use today.
OSI Model
The idea is basically the idea that

As a programmer, what happens most of the time when you are developing a new product is that you use the Socket APIs:
where:
- basically, as a programmer, you usually stay at and above the socket API level, i.e. layer 5
- most of the time, programmers don’t need to go down to layer 4 or beneath
Application Layer
Application layer that specifies the shared communications protocols and interface methods used by hosts in a communications network. This layer also serves as a window for the application services to access the network and for displaying the received information to the user.
- e.g. Application – Browsers, Skype Messenger etc.
Common protocols specified by the application layer involves:
HTTPprotocol, how websites work on browsers, as they all uses methods such asGET,POST, etc.SMTPprotocol, simple mail transport protocolSSHprotocol, the programsshimplements this protocolNTPprotocol, used for synchronizing time- etc.
As a result, different applications could potentially use the specified protocol to interact with each other.
Transport Layer
It is responsible for the actual End to End Delivery of the complete message. The transport layer also provides the acknowledgement of the successful data transmission and re-transmits the data if an error is found.
-
Therefore, it guarantees a package delivery, if it is feasible. If not, some message will tell you that it is not feasible.
- This even includes data that are truncated into several packages, which gets recomposed in this packet.
- It also uses port number associated with the receiver’s application, so that it knows which application specially it should send to.
Hence, it has the following functionality:
- Segmentation and Reassembly:
- Starting from the sender, if a data to send is too large for a packet, this layer first breaks the message into smaller units . Each of the segment produced has a header associated with it.
- The transport layer at the destination station/receiver reassembles the message.
- Service Point Addressing: In order to deliver the message to correct process, transport layer header includes a type of address called service point address or port address. Thus by specifying this address, transport layer makes sure that the message is delivered to the correct process.
Protocols defined in this layer include:
- TCP
- UDP
Network Layer
Every computer or interface on the internet has an IP address. Network layer works for the transmission of data from one host to the other located in different networks, using that IP address.
It also takes care of packet routing i.e. selection of the shortest path to transmit the packet, from the number of routes available.
Therefore, it has the following functionalities:
- Routing: The network layer protocols determine which route is suitable from source to destination. This function of network layer is known as routing.
- Logical Addressing: In order to identify each device on internetwork uniquely, network layer defines an addressing scheme. The sender & receiver’s IP address are placed in the header by network layer. Such an address distinguishes each device uniquely and universally.
Detailed Mechanism of Routing
Every organization first has gateway router that takes all the packets, look at the destination, and distribute/send the packet to the next hop (router)
- the next hop would usually be another router, which figures out one step deeper where your packet should go (by looking up the forwarding tables that it has)
- eventually, the packet gets delivered to your laptop, if it does
Router vs Gateway Router
- Router a device or a hardware which is responsible for receiving, analyzing and forwarding the data packets to other networks/router. It also stores the forwarding tables and headers.
- Gateway Router a device or a hardware which acts like a “gate” among the networks. Thus it can also be defined as a node which acts as an entrance for the other nodes in the network. It is also responsible for enabling the traffic flow within the network and communication among the networks which have a different set of protocols
The short take home message is that the Network Layer defines how to get one data packet from a device to another.
- however, it does not guarantee that the actual delivery of the data packet happens (i.e. it might not be received)
Some protocols include:
- IPv4
- when we talk about IP, we are by default talking about this
- IPv6
(Data) Link Layer
The data link layer (DLL) is responsible for the node to node delivery of the message (ethernet frame). The main function of this layer is to make sure data transfer is error-free from one node to another, over the physical layer.
- When a packet arrives in a network, it is the responsibility of DLL to transmit it to the Host using its MAC address.
Some functionalities of the DLL is:
- Framing: It provides a way for a sender to transmit a set of bits that are meaningful to the receiver.
- Physical addressing: After creating frames, Data link layer adds physical addresses (MAC address) of sender and/or receiver in the header of each frame.
- Error control: Data link layer provides the mechanism of error control in which it detects and retransmits damaged or lost frames.
- etc.
Some protocols related to the DLL is:
- WIFI
- Ethernet
- etc
Ethernet Frame
Basically, a format of encapsulating data, source/destination IP, source/destination MAC, and etc.

MAC Address
MAC Addresses are unique 48-bits hardware number of a computer, which is embedded into network card (known as Network Interface Card) during the time of manufacturing. MAC Address is also known as Physical Address of a network device.
With MAC being unique, you can essentially send the message to the designated machine.

Physical Layer
It is responsible for the actual physical connection between the devices.
- even when you make the connection, you need to specify how to get/receive (parse) whatever you got. This is done by the data link layer
The physical layer contains information in the form of bits. It is responsible for transmitting individual bits from one node to the next. When receiving data, this layer will get the signal received and convert it into 0s and 1s and send them to the Data Link layer, which will put the frame (the bunch of bytes) back together.
- essentially, this is what Electrical Engineering is about, and what we have covered in the Fundamentals of Computer Science Course.
Some functionalities of this layer includes:
- Bit synchronization: The physical layer provides the synchronization of the bits by providing a clock. This clock controls both sender and receiver thus providing synchronization at bit level.
- Bit rate control: The Physical layer also defines the transmission rate, i.e. the number of bits sent per second.
Shell Scripts
First of all Bash and Shell distinction:
-
At its base, a shell is simply a macro processor that executes commands.
- A Unix shell is both a command interpreter and a programming language.
- As a command interpreter, the shell provides the user interface to the rich set of GNU utilities.
- The programming language features allow files containing commands can be created, and become commands themselves.
- These new commands have the same status as system commands in directories such as
/bin, allowing users or groups to establish custom environments to automate their common tasks.
- These new commands have the same status as system commands in directories such as
-
Bash is the shell, or command language interpreter, for the GNU operating system. The name is an acronym for the ‘Bourne-Again SHell’, a pun on Stephen Bourne.
- Bash is largely compatible with
shand incorporates useful features from the Korn shellkshand the C shellcsh.
Terminologies
Some of the common ones are listed below.
name- A
wordconsisting solely of letters, numbers, and underscores, and beginning with a letter or underscore.Names are used as shell variable and function names. Also referred to as anidentifier.
- A
builtin- A command that is implemented internally by the shell itself, rather than by an executable program somewhere in the file system.
control operator- A
tokenthat performs a control function. It is anewlineor one of the following:‘||’, ‘&&’, ‘&’, ‘;’, ‘;;’, ‘;&’, ‘;;&’, ‘|’, ‘|&’, ‘(’, or ‘)’.
- A
field- A unit of text that is the result of one of the shell expansions. After expansion, when executing a command, the resulting fields are used as the command name and arguments.
job- A set of processes comprising a pipeline, and any processes descended from it, that are all in the same process group.
process group- A collection of related processes each having the same process group ID.
signal- A mechanism by which a process may be notified by the kernel of an event occurring in the system.
token- A sequence of characters considered a single unit by the shell. It is either a
wordor anoperator.
- A sequence of characters considered a single unit by the shell. It is either a
Writing a Shell Script
A simple example would be:
#!/bin/sh
ls
where:
#means comment, but if the first line contains#!, it means run the program/bin/sh, and feed the rest of the code in asstdin
File Permissions
Basically, it refers to:
xy-Laptop$ ll
total 32
drwxr-xr-x 2 jasonyux jasonyux 4096 Nov 11 19:39 ./
drwxr-xr-x 3 jasonyux jasonyux 4096 Nov 9 18:49 ../
-rwxr-xr-x 1 jasonyux jasonyux 16880 Nov 9 19:22 a.out*
-rw-r--r-- 1 jasonyux jasonyux 259 Nov 9 19:22 testPipe.c
where:
-
owner is
jasonyux, group isjasonyux -
file permissions can be seen from
-rw-r--r--
where:
groupmeans all users in this group- therefore,
-rw-r--r--means:- it is a regular file
- owner has read/write permission
- users in the group has read permission
- all other users have read permission
For directories, the meanings are different:
- read permission means you can
ls(or autocomplete) -
write permission means you can change contents in that directory
- execute permission means you can enter the directory (i.e.
cdinto it)- this means that if you want to get to a directory such as
cd ~/code/test, all directories~,code,testneeds to havexpermission
- this means that if you want to get to a directory such as
s Permission
Now, consider the case that you ONLY want an executable to edit your directory (e.g. editing a file there). This means you give the directory permission of r-x. But if you do not give w permission, that program cannot write anything as well.
- therefore, there is a special permission
s, meaningsetuidorsetgidbit is on.
For example:
An executable with:
-rwsr-xr-x means:
- owner can do anything, and it sets the
useridof all the others executing it to be the same as the owner- this means users in group/other users, though cannot write to the file, can execute the file as if the owner executed it
Binary Encoding of File Permissions
The idea is that every permission can be expressed as a number:
_rw_r__r__means110 100 100, hence it means6 4 4_rwxr_xr_xmeans111 101 101, hence it means7 5 5
Extension:
- For the special permission
s, you need to add an extra1in front-rwsr-xr-xmeans1 7 5 5
Changing Permission
Basically, you use chmod <permission number> <file>
For example
chmod 755 <your file>- usually needs
sudo
File Descriptors
UNIX OS has the I/O API: open, read, write
-
these are system level functions.
-
the standard
Clibrary usesfopen,fread,fwrite, etc- they depends on the system level I/O functions. If you use UNIX, then
Cusesopen,…
- they depends on the system level I/O functions. If you use UNIX, then
Additionally, the methods open/read/write has integer (file descriptor) return type.
- file descriptors are small integers representing open files
- instead of the
FILE *forClibrary - when a program starts, kernel automatically opens 3 files without being asked
stdin,stdout,stderron descriptors0,1,2(imagine those are specifically connected to your program)- i.e. keyboard, screen, screen unless redirected
- subsequent open files get file descriptor
3,4,5,6,…
- instead of the
For example:
int fd = open("myfile", O_RDONLY, 0);
if (fd == -1) {
// open error
}
...
In general
- The take-away message is that everything in UNIX is a file, namely, the base operations are read/write.
- file descriptors are used for sockets too, i.e. reading from internet and writing to internet
Endianness
Big Endianness vs Little Endianness
- if you write multi-byte data into your file, little endianness stores and reads each byte of the data in the “reverse order”, such that the least significant byte goes first
- e.g. this means
0x 00 01 02 03gets stored to03 02 01 00- this happens because the above is a single 4 byte data, and it when it writes the data together, it flips
- since we have binary files, the actual storage looks like
00000011 00000010 00000001 00000000
- therefore, this will not happen to
char [], which are essentially sequence of 1 byte data, so it will write each data (one character=one byte), and hence will not be flipped - e.g. Intel-CPUs store them backwards
- e.g. this means
- Big endianness is the “natural” order for storing each byte, such that it
- the internet byte order is also big endianness
#include <stdio.h>
#include <assert.h>
#include <arpa/inet.h>
#define HOST_FILE "endian-demo.host"
#define NET_FILE "endian-demo.net"
int main()
{
FILE *f;
unsigned int num_host;
unsigned int num_net;
printf("Enter a hexadecimal integer: ");
scanf("%x", &num_host);
printf("The hex number 0x%.8x is %d in decimal\n", num_host, num_host);
f = fopen(HOST_FILE, "wb");
assert(f);
// write the number
fwrite(&num_host, sizeof(num_host), 1, f);
printf("Wrote num_host to %s\n", HOST_FILE);
fclose(f);
// converts the HOST byte order TO NETWORK byte order
// for intel cpu, converts Little Endianness to Big Endianness
// actually, just swap the sequence of numbers
num_net = htonl(num_host);
f = fopen(NET_FILE, "wb");
assert(f);
fwrite(&num_net, sizeof(num_net), 1, f);
printf("Wrote num_net to %s\n", NET_FILE);
fclose(f);
printf("Run \"hd <filename>\" to see the content of a file\n");
}
where:
- a hexadecimal number would be 4 bytes, in the form
0x 00 00 00 00.
Therefore, to read/write into the network, you need to:
- use
htonltransform your computer’s byte order to the network byte order - use
ntohltransforms network byte order (big endianness) to your host computer’s endianness
In general
- The problem is with how each single unit of data is represented. If each unit of data to be written exceeded one byte, then every write will flip the order (if little endian). However, if each unit of data is one byte or less, then each write does nothing.
- e.g. writing
char string[2] = "ac"will be stored as61 63, since you have two units/writes of one byte.
- you are essentially writing
a, then writingc.- e.g. writing
short test = 2will be stored as02 00, because a short is a single write of0002.- Use
hdto look at the content of a binary file
Week 11
Socket API
The client server (or B/S) model

and the idea is:
- server (program) waits for request from clients
- client (program) makes a request
- server and client handshakes, and establish a connection/session
- now, we can communicate using data packets
- remember, data packets would contain source/destination IP and source/destination port number
Under the hood, the base implementations will be the Socket API
- e.g. underneath Java, it is probably written in
C
For example:
www.columbia.eduwill be translated by theDNSserver to the IP address of128.59.105.24- obtained by running
dig <web-address>
- obtained by running
Socket
A socket is defined as the end-point for TCP/IP network connection.
- It is consist of two components from both client and server:

- an IP address
- a port number
For example:
- Once you made a connection between the client and the server via
nc, there are four things being connected:nc -l 10000on server- with IP
217.100.011.011(e.g.) - with port
10000
- with IP
nc 217.100.011.011 10000- with IP
123.456.789.000(e.g.) - with randomly generated port
4543(e.g.)
- with IP
Socket API Summary

where:
accepton the server side would be a BIO function
socket()
Listening Socket vs Connected Socket

where:
- the listening socket lives for the lifetime of the program
-
all server side sockets will have a port number being the same:
80 - a problem you see here is that in this design, you can only make one socket connection with the server, since the port
80for listening will be blocked until the established connection closes.- you can in fact also specify the size of queue for that listening socket
- this diagram would be useful for some examples shown in the section Socket API Examples
Socket API Examples
tcp-echo-client
In short, the program:
- Create/initialize the
socket - Connect to the
tcp-echo-serverprogram using the serveripandport - Get a line from client terminal, and send that to
tcp-echo-server - Receive content (first letter capitalized) from the server
- Close the connection, and quit the program
static void die(const char *s) { perror(s); exit(1); }
int main(int argc, char **argv)
{
if (argc != 3) {
fprintf(stderr, "usage: %s <server-ip> <server-port>\n",
argv[0]);
exit(1);
}
const char *ip = argv[1];
// atoi converts initial portion of the string pointed to by ptr to int.
unsigned short port = atoi(argv[2]);
// 1. Create a socket for TCP connection
int sock; // socket descriptor
// creates the socket that contains its own IP and port
if ((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0)
die("socket failed");
// 1.1 Construct a server address structure
struct sockaddr_in servaddr
// put 0 on every single byte of the structure
// this is useful in other cases as well,
// since it made sure every allocated byte is non-empty/initialized
memset(&servaddr, 0, sizeof(servaddr)); // must zero out the structure
servaddr.sin_family = AF_INET;
// inet_addr takes in ip in string, and converts to network byte order ip
servaddr.sin_addr.s_addr = inet_addr(ip);
// htons converts short variable to big endian/network byte order
servaddr.sin_port = htons(port); // must be in network byte order
// 2. Establish a TCP connection to the server
// connect returns only when its done connecting
if (connect(sock, (struct sockaddr *) &servaddr, sizeof(servaddr)) < 0)
die("connect failed");
// 3. Read a line from stdin and send it to the server
char buf[100];
if (fgets(buf, sizeof(buf), stdin) == NULL) {
die("fgets returned NULL");
}
// recall that fgets add a "\0" in the end.
// so "Hi\n" becomes "Hi\n\0"
size_t len = strlen(buf); // so strlen("Hi\n\0")==3
/*
* send(int socket, const void *buffer, size_t length, int flags)
*
* - normally, send() blocks until it sends all bytes requested
* - returns num bytes sent or -1 for error
* - send(sock,buf,len,0) is equivalent to write(sock,buf,len)
* - recall that write() is the unix version for file descriptor=sock here
*/
// here, you don't need to send the "\0"
// blocks/returns only when finished sending
if (send(sock, buf, len, 0) != len)
die("send failed");
// 4. Receive the responses from the server and print them
/*
* recv(int socket, void *buffer, size_t length, int flags)
*
* - normally, recv() blocks until it has received at least 1 byte
* - returns num bytes received, 0 if connection CLOSED, -1 if error
* - recv(sock,buf,len,0) is equivalent to read(sock,buf,len)
* - again, read() is the UNIX version for file descriptors
*/
int r;
// here, it says we receive up to 100 bytes.
// In fact, server usually breaks content up into multiple shots,
// AND number of chunks sent each time is also RANDOM
// the only thing that is preserved is the ORDER (so we can put them together)
while (len > 0 && (r = recv(sock, buf, sizeof(buf), 0)) > 0) {
printf("RECEIVED: [");
// printf() would NOT work because it might not be null terminated
fwrite(buf, 1, r, stdout); // write 1 byte r times
printf("]\n");
len -= r;
}
if (r < 0)
die("recv failed");
// 5. Close the connection. Clean-up
close(sock);
return 0;
}
where, some important things to note are:
-
the socket of the client will have its own
ipandportindented automatically. -
socket(AF_INET, SOCK_STREAM, 0)means we are doing:AF_INET=IPv4SOCK_STREAM=TCP
-
structaddr_inlooks like:// see this as: class sockaddr_in "extends" sockaddr struct sockaddr_in { // in total takes up 8 bytes sa_family_t sin_family; /* address family: AF_INET */ in_port_t sin_port; /* port in NETWORK BYTE order */ struct in_addr sin_addr; /* internet address */ };and the
struct in_addrlooks like:struct in_addr { uint32_t s_addr; /* address in NETWORK BYTE order */ };lastly, we casted the pointer to
sockaddr_intosockaddr, because:struct sockaddr { // internally, when connect sees sa_family=AF_INET // it will cast the type back to sockaddr_in (down-casting) sa_family_t sa_family; char sa_data[14]; // this is just a filler } -
send()function is blocking, such that it returns (number of bytes sent) only when finished sending the contents you specified- it is more useful than
write()due to the last option. (in this case,0means default, which would be equivalent towrite(sock,buf,len))
- it is more useful than
-
recv()function is also blocking, but different fromsend(), such that you have no control exactly how many bytes are going to come.- the return values here is important to know:
- number of bytes received
0if connectionCLOSED-1iferror
- the return values here is important to know:
Trick
Instead of reading from the client with random number of bytes with
recv, you can read line by line, by:
convert the
socketinto aFile *withFILE *input = fdopen(socket_descriptor, "r");use
fgets(), assuming the content is a text
- if you have binary coming, it will not work
So we see that almost always, we will have the template:
const char *ip = argv[1]; unsigned short port = atoi(argv[2]); // Create a socket for TCP connectionint sock; // socket descriptor if ((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0) die(“socket failed”);
// Construct a server address structure
struct sockaddr_in servaddr; memset(&servaddr, 0, sizeof(servaddr)); servaddr.sin_family = AF_INET; servaddr.sin_addr.s_addr = inet_addr(ip); servaddr.sin_port = htons(port);
// Establish a TCP connection to the server
if (connect(sock, (struct sockaddr *) &servaddr, sizeof(servaddr)) < 0) die(“connect failed”);
tcp-echo-server
In short, this program:
- create/initialize the socket
- bind the socket to your
ip/portfor listening - start listening and waits for a connection
- when receives a request for connection, accept and establish the connection
- receive contents from client, capitalize the first character
- sends the content back to the client
- close the connection
- loop back to to step 4
static void die(const char *s) { perror(s); exit(1); }
int main(int argc, char **argv)
{
if (argc != 2) {
fprintf(stderr, "usage: %s <server-port>\n", argv[0]);
exit(1);
}
unsigned short port = atoi(argv[1]);
// 1. Create a listening socket (also called server socket)
int servsock;
if ((servsock = socket(AF_INET, SOCK_STREAM, 0)) < 0)
die("socket failed");
// 1.1 Construct local address structure
struct sockaddr_in servaddr;
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
// need to pass in your OWN ip address
// INADDR_ANY=0.0.0.0, meaning any IP address I HAVE/OWN
// you could manually put in your own IP address as well
servaddr.sin_addr.s_addr = htonl(INADDR_ANY); // any network interface
// your OWN port
servaddr.sin_port = htons(port);
// 2. Bind to the OWN local address
// bind instead of connect
// error: port number already in use is an error from this function
if (bind(servsock, (struct sockaddr *) &servaddr, sizeof(servaddr)) < 0)
die("bind failed");
// 3. Start listening for incoming connections
if (listen(servsock, 5 /* queue size for connection requests */ ) < 0)
die("listen failed");
int r;
char buf[10]; // 10 bytes buf
int clntsock;
socklen_t clntlen;
struct sockaddr_in clntaddr; // this is empty
while (1) {
// 4. Accept an incoming connection
fprintf(stderr, "waiting for client ... ");
clntlen = sizeof(clntaddr); // initialize the in-out parameter
// accept() is also a BLOCKING function
// BOTH client and server sockets RETURN ONLY WHEN accepted
if ((clntsock = accept(servsock,
(struct sockaddr *) &clntaddr, &clntlen)) < 0)
die("accept failed");
// accept() RETURNED a CONNECTED SOCKET (also called client socket)
// and filled in the client's address into clntaddr
fprintf(stderr, "client ip: %s\n", inet_ntoa(clntaddr.sin_addr));
// 5. Receive msg from client, capitalize the 1st char,
// 6. And send it back
// receive up to 10 bytes=sizeof(buf) at a time
// note that r != 10 all the time (in fact, often it is random)
// we terminate the loop NORMALLY when r=0, namely, CLIENT CLOSED connection
while ((r = recv(clntsock, buf, sizeof(buf), 0)) > 0) {
*buf = toupper(*buf);
// so we should send up to r bytes
if (send(clntsock, buf, r, 0) != r) {
// SERVER should not die!
// if something went wrong, we should just close the connection
// and restart/accept NEW connections
fprintf(stderr, "ERR: send failed\n");
break;
}
}
if (r < 0) {
fprintf(stderr, "ERR: recv failed\n");
}
// Client closed the connection (r==0) or there was an error
// 7. Either way, close the connected client socket and go back to accept()
close(clntsock); // so in the end, client closes first, and then server closes
}
}
where:
accept(servsock, (struct sockaddr *) &clntaddr, &clntlen)does a lot:- establishes the connection and returns a connected socket
- fills in data related to the client side into
clntaddr - change the
clntlento tell me how many bytes have been filled intoclntaddr(not used here)
- listening socket lives forever until the program dies.
- you can think of the returned
socketfromaccept()to be another standalone socket
- you can think of the returned
recv(), as mentioned for client version of the program as well, has a random behavior, such that:- you cannot be sure how many bytes will come at each time
- lastly, for the error conditions here (by
sendorrecv), we should try not to terminate our program:- as a server, we should keep ourselves alive, unless you are sure it will be server side error
- for other errors, the intuitive solution would be close the connection, and let the client retry/reconnect
Again, the template almost always for a server would be:
// 1. Create a listening socket (also called server socket) unsigned short port = atoi(argv[1]); int servsock; if ((servsock = socket(AF_INET, SOCK_STREAM, 0)) < 0) die("socket failed"); struct sockaddr_in servaddr; memset(&servaddr, 0, sizeof(servaddr)); servaddr.sin_family = AF_INET; servaddr.sin_addr.s_addr = htonl(INADDR_ANY); // any network interface servaddr.sin_port = htons(port); // 2. Bind to the OWN local address if (bind(servsock, (struct sockaddr *) &servaddr, sizeof(servaddr)) < 0) die("bind failed"); // 3. Start listening for incoming connections if (listen(servsock, 5 /* queue size for connection requests */ ) < 0) die("listen failed"); int r; char buf[10]; int clntsock; socklen_t clntlen; struct sockaddr_in clntaddr; while (1) { fprintf(stderr, "waiting for client ... "); // 4. Accept an incoming connection clntlen = sizeof(clntaddr); // initialize the in-out parameter if ((clntsock = accept(servsock, (struct sockaddr *) &clntaddr, &clntlen)) < 0) die("accept failed") ... }
Week 12
HTTP
First, we talk about HTTP 1.0 protocol. The general concept behind web is:
- Client sends a
HTTPrequest for a resource on server (by default, to port80)- e.g. the
index.htmlfile
- e.g. the
- Server sends a
HTTPresponse
For example
- If you type in something like
www.test101.com/doc/test.html, your browser sends the following:- the format of request and response will conform to the HTTP protocol

-
Then, by the same protocol, the server will respond the following (a different request):

Note:
HTTP protocol also specified that each new line is terminated with
\r\n, instead of\n.
for example:
HTTP/1.1 200 OK\r\n Date: ...where:
- the actual one would be in binary of course
Further Reading:
- http://www.jmarshall.com/easy/http/
Imitating HTTP using netcat
In fact, you could simulate the action of requesting using netcat:
-
use
nc clac.cs.columbia.edu 80, and sendGET / HTTP/1.1GET / HTTP/1.1is the same asGET /index.html HTTP/1.1
-
The content returned will be:
HTTP/1.1 200 OK Date: Wed, 25 Nov 2020 14:21:40 GMT Server: Apache/2.4.29 (Ubuntu) Upgrade: h2 Connection: Upgrade, close Last-Modified: Fri, 25 Jan 2019 02:00:56 GMT ETag: "4c2-5803eb299c120" Accept-Ranges: bytes Content-Length: 1218 Vary: Accept-Encoding Content-Type: text/html <!DOCTYPE html> <head> <title>Welcome to CLAC</title> <style> pre { font-family: Consolas, Menlo, monospace; } </style> </head> <body> <pre> _ _ __ _____| | ___ ___ _ __ ___ ___ | |_ ___ \ \ /\ / / _ \ |/ __/ _ \| '_ \ _ \ / _ \ | __/ _ \ \ V V / __/ | (_| (_) | | | | | | __/ | || (_) | \_/\_/ \___|_|\___\___/|_| |_| |_|\___| \__\___/ @@@@@@ @@@ @@@@@@@ @@@@@@@@ @@@@@@@ @@@@ @@@@@@@ @@@@@@@@ @@@ @@@!! !@@ @@! @!@ !@! !@! !@! @!@!!@ @!@ !!@@!! @!! !!@!@! !@! @!!@!!! !!! !!: !!: !:! !!: :!: :!: !:! :!: :: :::: ::: :::: :: :: : : : :: :: : : : : Trying to log in? <a href="http://www.cs.columbia.edu/~jae/3157/linux-environment.html">Click here for the login guide.</a> </pre> </body>where:
- you see the first part being the
response header - the
htmlcontent being theresponse body. If we connected using a browser, then thehtmlwill also be rendered
- you see the first part being the
Similarly, you could simulate the action of responding using netcat as well:
-
use
nc -l 10027on your laptop -
go to your browser and do
localhost:10027/Then you see the follows in your
netcat:GET / HTTP/1.1 Host: localhost:10027 Connection: keep-alive Upgrade-Insecure-Requests: 1 User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36 Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9 Sec-Fetch-Site: none Sec-Fetch-Mode: navigate Sec-Fetch-User: ?1 Sec-Fetch-Dest: document Accept-Encoding: gzip, deflate, br Accept-Language: en-US,en;q=0.9in fact, I can fake the response as well by:
HTTP/1.0 200 OK <html><h1>Hi</h1></html>where:
- **the browser will render the **
<html><h1>Hi</h1></html>to be the webpage displaying on your laptop
- **the browser will render the **
Week 13
Socket API (Continued)
Here, we discuss the advanced version of tcp-echo-client and tcp-echo-server, where:
- instead of sending/receiving command line texts, we can send and receive files
tcp-sendersends a file to a targetiptcp-recverlistens,receives, and saves a file from clients
tcp-sender
This will be the advanced version of tcp-echo-client.
- Establish a TCP connection with a remote IP
- Step 1 basically uses the boiler template
- Send a file content to the server by:
- Send file size
- Read and send file content
- Receive and compare the received file size
- if incorrect,
die
- if incorrect,
- Done, closes the socket
With the additional feature that:
- if we passed
./send <ip> <port> -, we can typed in filename fromstdin- in fact, passing in
-as filename to indicate read content fromstdinis a common paradigm in UNIX - this is bugged actually due to the unknown file size and loop in server code
- in fact, passing in
static void die(const char *s) { perror(s); exit(1); }
int main(int argc, char **argv)
{
if (argc != 4) {
fprintf(stderr, "usage: %s <server-ip> <server-port> <filename>\n",
argv[0]);
exit(1);
}
const char *ip = argv[1];
unsigned short port = atoi(argv[2]);
const char *filename = argv[3];
// additional feature
// Open the file to send; if "-" is passed, read from stdin
FILE *fp;
if (strcmp(filename, "-") == 0) {
fp = stdin;
} else {
if ((fp = fopen(filename, "rb")) == NULL)
die(filename);
}
/* Start of template code */
// Create a socket for TCP connection
int sock; // socket descriptor
if ((sock = socket(AF_INET, SOCK_STREAM, 0)) < 0)
die("socket failed");
// Construct a server address structure
struct sockaddr_in servaddr;
memset(&servaddr, 0, sizeof(servaddr)); // must zero out the structure
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = inet_addr(ip);
servaddr.sin_port = htons(port); // must be in network byte order
// Establish a TCP connection to the server
if (connect(sock, (struct sockaddr *) &servaddr, sizeof(servaddr)) < 0)
die("connect failed");
/* End of template code */
// First, send file size as 4-byte unsigned int in network byte order
struct stat st;
stat(filename, &st); // get data about the file into struct stat
uint32_t size = st.st_size; // use uint32_t to make sure
// 1. it is unsigned
// 2. it is 4 byte. Because actually size of int may vary
fprintf(stderr, "file size: %u\n", size);
uint32_t size_net = htonl(size); // since it is multibyte, we need to convert
/*
* send(int socket, const void *buffer, size_t length, int flags)
*
* - normally, send() blocks until it sends all bytes requested
* - returns num bytes sent or -1 for error
* - send(sock,buf,len,0) is equivalent to write(sock,buf,len)
*/
// send the size of file
if (send(sock, &size_net, sizeof(size_net), 0) != sizeof(size_net))
die("send size failed");
// Second, send the file content
char buf[4096];
unsigned int n;
unsigned int total = 0;
// reading OBJECT of size 1 byte for 4096 TIMES INTO buf
// returns n=numebr of bytes read
// returns 0 for EOF
while ((n = fread(buf, 1, sizeof(buf), fp)) > 0) {
// send content in buf, for n bytes
if (send(sock, buf, n, 0) != n)
die("send content failed");
else
total += n;
}
if (ferror(fp)) {
// fread() returns 0 on EOF or error, so we check if error occurred
die("fread failed");
}
fclose(fp);
fprintf(stderr, "bytes sent: %u\n", total); // done with sending file
// Third, receive file size back from the server as acknowledgement
uint32_t ack, ack_net;
/*
* recv(int socket, void *buffer, size_t length, int flags)
*
* - normally, recv() blocks until it has received at least 1 byte
* - returns num bytes received, 0 if connection closed, -1 if error
* - recv(sock,buf,len,0) is equivalent to read(sock,buf,len)
*
* - With TCP sockets, we can receive less data than we requested;
* MSG_WAITALL flag changes this behavior -- it requests that the
* operation block UNTIL THE FULL request is satisfied.
*/
// receive all 4 bytes together, which is sizeof(ack_net)=length
int r = recv(sock, &ack_net, sizeof(ack_net), MSG_WAITALL);
if (r != sizeof(ack_net)) {
if (r < 0)
die("recv failed");
else if (r == 0)
die("connection closed prematurely");
else
die("didn't receive uint32");
}
ack = ntohl(ack_net); // convert it back to host byte order
// check if the SERVER wrote the correct number of bytes
if (ack != size)
die("ack!=size");
// recv() will return 0 when the SERVER CLOSES the TCP connection
char x; // dummy variable, server should close here
r = recv(sock, &x, 1, 0);
assert(r == 0);
// Clean-up
close(sock);
return 0;
}
where, some additional functions used above are:
stat()- use
man 2 statinstead ofman stat, which would give you the command instead of function - Signature:
int stat(const char *pathname, struct stat *statbuf);- give a
path/filename, andstatwill fill in all the data relevant to that file intostruct stat
- give a
- use
MSG_WAITALLflag forrecv(int socket, void *buffer, size_t length, int flags)- block until all
lengthbytes are received - for example ` recv(sock, &ack_net, sizeof(ack_net), MSG_WAITALL)`
- this will block until all
sizeof(ack_net)number of bytes are received. In this casesizeof(ack_net)=4
- this will block until all
- block until all
tcp-recver
This will be the advanced version of tcp-echo-server.
- Establish a listening server
- Accept a connection
- step 1 and step 2 basically uses the boiler template
- Receive and save a file:
- Receive the size of file
- Receive and write the content of the file
- Send the size of the written file to the client
- Close the client connection
- Repeat to step 2
static void die(const char *s) { perror(s); exit(1); }
int main(int argc, char **argv)
{
if (argc != 3) {
fprintf(stderr, "usage: %s <server-port> <filebase>\n", argv[0]);
exit(1);
}
unsigned short port = atoi(argv[1]);
const char *filebase = argv[2];
// Create a listening socket (also called server socket)
int servsock;
if ((servsock = socket(AF_INET, SOCK_STREAM, 0)) < 0)
die("socket failed");
/* Start of template code */
// Construct local address structure
struct sockaddr_in servaddr;
memset(&servaddr, 0, sizeof(servaddr));
servaddr.sin_family = AF_INET;
servaddr.sin_addr.s_addr = htonl(INADDR_ANY); // any network interface
servaddr.sin_port = htons(port);
// Bind to the local address
if (bind(servsock, (struct sockaddr *) &servaddr, sizeof(servaddr)) < 0)
die("bind failed");
// Start listening for incoming connections
if (listen(servsock, 5 /* queue size for connection requests */ ) < 0)
die("listen failed");
// additional setups
int clntsock;
socklen_t clntlen;
struct sockaddr_in clntaddr;
FILE *fp;
unsigned int filesuffix = 0;
char filename[strlen(filebase) + 100];
int r;
char buf[4096];
uint32_t size, size_net, remaining, limit;
struct stat st;
while (1) {
// Accept an incoming connection
clntlen = sizeof(clntaddr); // initialize the in-out parameter
if ((clntsock = accept(servsock,
(struct sockaddr *) &clntaddr, &clntlen)) < 0)
die("accept failed");
/* END of template code */
fprintf(stderr, "client ip: %s\n", inet_ntoa(clntaddr.sin_addr));
sprintf(filename, "%s.%u", filebase, filesuffix++); // formatting a string into filename variable
fprintf(stderr, "file name: %s\n", filename);
// opening a file for writing, in binary
// binary mode so that there will be no data "translation" into other formats
if ((fp = fopen(filename, "wb")) == NULL)
die(filename);
// First, receive file size
// uint32_t size_net; was defined
// MSG_WAITALL means to block UNTIL all sizeof(size_net)=4 bytes are received
r = recv(clntsock, &size_net, sizeof(size_net), MSG_WAITALL);
// make sure all 4 bytes are received.
// e.g. client might have quitted before sending the 4 bytes
if (r != sizeof(size_net)) {
if (r < 0)
die("recv failed");
else if (r == 0)
die("connection closed prematurely");
else
die("didn't receive uint32");
}
size = ntohl(size_net); // convert multi-byte data from internet to host byte order
fprintf(stderr, "file size received: %u\n", size);
// Second, receive the file content
remaining = size; // size = number of bytes of the file to receive
// loop UNTIL remaining=size bytes are RECEIVED
while (remaining > 0) {
// char buf[4096];
// controls writing AT MOST 4096 bytes at a time
limit = remaining > sizeof(buf) ? sizeof(buf) : remaining;
// now, receive random numebr of bytes, upto limit
r = recv(clntsock, buf, limit, 0);
if (r < 0)
die("recv failed");
else if (r == 0)
die("connection closed prematurely");
else {
// write r bytes to the file
remaining -= r;
if (fwrite(buf, 1, r, fp) != r)
die("fwrite failed");
}
}
assert(remaining == 0);
fclose(fp); // done receiving and write file
// Third, send the file size back as acknowledgement
// get the stat of the file I JUST WROTE TO
stat(filename, &st);
size = st.st_size;
fprintf(stderr, "file size on disk: %u\n\n", size);
size_net = htonl(size);
// send the data of content written to CLIENT
if (send(clntsock, &size_net, sizeof(size_net), 0)
!= sizeof(size_net))
die("send size failed");
// Finally, close the client connection and go back to accept()
close(clntsock); // SERVER closes the connection
}
}
Exam 4 Material Ends Here
Dynamic HTML
First, we need to understand fully how a static html works.
Consider the following html file with path ~xy2437/html/index.html:
<html>
<body>
<h1>
Star Trek: The Next Generation, the best TV show ever!
</h1>
<p>
<table>
<tr>
<td><h2>The ship:</h2></td>
<td><img src="images/ship.jpg"></td>
</tr>
<tr>
<td><h2>And the crew:</h2></td>
<td><img src="images/crew.jpg"></td>
</tr>
</table>
</body>
</html>
Then, in the case of clac, if you requested:
www.clac.cs.columbia.edu/~xy2437/index.html
the following happens between your browser and the Apache server inside clac:
Apache clacreceives a get request forGET /~xy2437/index.html HTTP/1.1Apache clacconverts the directory to/~xy2437/html/index.html- this is configured by the Apache server inside
clac
- this is configured by the Apache server inside
Apache claclooks for the file/~xy2437/html/index.html, and serves/returns the content- and when done, it closes the connection
- Browser receives the
htmlfile, and renders the content- in the above example, realizes that we needed
src="images/ship.jpg"as well
- in the above example, realizes that we needed
- Browser creates another connection, sends another request for
~xy2437/images/ship.jpgautomatically- based on the current URI
/~xy2437/<index.html>
- based on the current URI
Apache clacreceives the request, convert the path, and serve the file- Browser receives the content, and realized another
src="images/crew.jpg" - Repeat step 5 and 6
- Done
In total:
- there has been three separate connections going on (under HTTP 1.0)
- this causes quite some slow down, and is solved by HTTP 1.1:
- server not closing the connection one completed, and connection is kept alive by browser periodically
Now, we get to how modern dynamic HTML works
3-Tier Architecture
In short, to generate a dynamic webpage, you will have:
- a browser that act as a client, that
- talks to the front-end server
- a front-end server, that
- returns the webpage to browser clients
- talks to the back-end server for data
- a back-end server, that
- returns to the front-end server for requested data
This is also called a 3-Tier Structure
For example, for lab7
- You have:
mdb-lookup-serveras a backend server, serving up query resultshttp-serveras the frontend server- serving to the client resources stored in the machine
- talking to backend
firefoxis the client browser talking to frontendhttp-server

where, in this case:
- the connection between your browser and
http-server(front-end) is transient (i.e. you close/open new connections for new client/resources) - the connection between your
http-server(front-end) andmdb-cs3157(back-end) is permanent
Additionally:
- your browser also does a lot more than simply getting the data from front-end server:
- its engine runs the JavaScript, which could also do requests/animations etc.
Typical Combinations of 3-Tier Structure would be:
- LAMP: Linux + Apache + MySQL + PHP
Week 14
From C to C++
In short, you can imagine C++ as a superset of C (not strictly true, but works in many cases), with added functionalities:
- OOP
Note:
- For
C++, we should useg++instead ofgccfor compiling/linking
For example
-
The following program runs with the same output as
a.cor asa.cpp:#include <stdio.h> struct Pt { double x; double y; } void print(struct Pt *pp){ printf("(%g, %g)\n", pp->x, pp->y); } int main(){ struct Pt p; // will print garbage value because it has not been initialized print(&p); }
Changes in C++
And some basic changes for cpp in the above example would be:
-
replacing
structdefinition withclass// means the same as struct Pt in C class Pt { double x; double y; }however, in
c++:-
by default, the fields are private
-
to make them public, so that members can be accessed, you need add a
publicsectionclass Pt { public: double x; double y; private: ... }
-
-
omitting the keyword
struct PttoPtfor custom typevoid print(Pt *pp){ printf("(%g, %g)\n", pp->x, pp->y); } int main(){ Pt p; print(&p); }
Note
- One difference between
JavaandC++at this point would be that:
- every
cppfile would require amain
Methods and Constructors
-
method and constructors are supported (signature of OOP)
-
in
C++, methods are also called member functions -
for example:
class Pt { public: double x; double y; // constructor Pt() { x = 1.0; y = 2.0; } // method/member function void print() { // this keyword = implicit pointer to this object printf("(%g,%g)\n", this->x, y); } };
-
Note:
Under the hood, what happens is almost just this:
// some code omitted here void Pt_ctor(struct Pt *this) { this->x = 1.0; this->y = 2.0; } void Pt_print(struct Pt *this) { printf("(%g,%g)\n", this->x, this->y); } int main() { Pt p; Pt_ctor(&p); // inserted automatically Pt_print(&p); }and the take away message is:
- those OOP programs are nothing different from programs like
C
In fact, this is pretty similar to
Java:
for instance, the equivalent Java code would be
class Pt { ... // constructor public Pt() { x = 1.0; y = 2.0; } // method/member function public void print() { System.out.println(this.x +"," + this.y); } };
Similarly, to call those functions in C++,
int main()
{
// Stack allocation of object in C++
// Declaring a reference (i.e. pointer) in Java
Pt p;
/* Heap allocations:
// in Java
Pt pp = new Pt();
// in C++
Pt *pp = new Pt();
// in C
Pt *pp = malloc(sizeof(struct Pt));
Pt_ctor(pp)
*/
p.print();
}
- which is again, same as Java
- and the
p.basically passes the pointer*pto the variablethis
Difference between C++ and Java
One critical differen between Java and C++ is:
-
in
C++:Pt p;would have allocated space forclass Pt -
in
Java:Pt p;only creates a reference, without allocating any memory (a hence aNullPointer)-
however, there is a similar ability in
C++:int main() { // Heap allocations: // in Java Pt pp = new Pt(); // in C++ Pt *pp = new Pt(); // in C Pt *pp = malloc(sizeof(struct Pt)); Pt_ctor(pp) } -
and to
freethe memory, you would havedelete()inC++
-
In fact
in
Java, since every object is a reference, so they also removed*and&.
therefore, the line below only creates a pointer without allocation in
JavaPt p;hence, you have the code like:
// in Java Pt pp = new Pt(); // in C++ Pt *pp = new Pt();Also, this means that all objects for Java would be in
Heap, which is whyJavawould be slower than programs such asC++
Miscellaneous
Using sftp
In general, you need to:
sftpinto a remote server withsftp <remoteaddress>- basically the
<remoteaddress>would be the same address where youssh
- basically the
- configure your
local directorywithlcd - configure your
remote directorywithcd - use
get <fileName>to transfer a file fromremote directorytolocal directory, andput <fileName>to do the reverse.- if you want to transfer folders, use
get -rorput -r
- if you want to transfer folders, use
- use
byeto disconnect
For example:
sftp> lcd '/mnt/d/Dropbox/SEAS2020/Fall Semster/Advanced Programming/cs3157' #configure local directory
sftp> cd ~ #configure remote directory
sftp> get test.c #exists on remote `~/test.c`, and transfers FROM remote TO local
Fetching /mnt/disks/students209/xy2437/test.c to test.c
/mnt/disks/students209/xy2437/test.c 100% 77 0.2KB/s 00:00
where:
getis used because we are transferring fromremotetolocal
GCD with Euclidean Algorithm
It has to do with the fact that:
- Write $A$ in quotient remainder form $(A = B⋅Q + R)$
- Find
GCD(B,R)using the Euclidean Algorithm sinceGCD(A,B) = GCD(B,R) GCD(A,0) = AGCD(0,B) = B
Proof of GCD(A,B)=GCD(B,R)
-
We show that
GCD(A,B)=GCD(B,A-B)-
first, let $A-B = C$, then we know:
-
$X⋅GCD(A,B)=A$
-
$Y⋅GCD(A,B)=B$
Hence:
\[X⋅GCD(A,B) - Y⋅GCD(A,B) = C\\ (X - Y)⋅GCD(A,B) = C\] -
so
GCD(A,B)evenly divides C
-
-
-
Quite long. To continue, view https://www.khanacademy.org/computing/computer-science/cryptography/modarithmetic/a/the-euclidean-algorithm
Algorithm
This is now simple:
int gcd(int a, int b) {
if (a == 0)
return b;
return gcd(b % a, a);
}
Useful Git Commands
-
If you want to view the contents of a file at a previous commit without checking it out, you can run:
git show <commit tag>:path/to/file- remember to remove the angled brackets around the commit tag
-
If you want to see all of the files that you have committed to your repository (in case you want to check if you committed any backup or object files), you can run:
git ls-tree --name-only -r HEADThis will list the files in your git tree (i.e. everything committed) at the HEAD commit with only the name (Git normally prints out other extraneous details). It will recurse (-r) into all subdirectories to show the filenames there too.
- use
git rm filenameto delete files that you don’t want to track and stage
- use
valgrind
Used for checking leakages. Basic uses is:
valgrind --leak-check=yes ./your_program <some optional arguements here>
To append the output to a file (in this example, README.txt):
valgrind --leak-check=yes ./your_program <some optional arguements here> >> ../README.txt 2>&1
where:
-
2>&1means redirectstderrtostdout -
without
2>&1, nothing will be appended to your file
sed
This program itself is actually a programming language. But we could write one-line programs to achieve some cool stuff.
For example:
This can be a tool used for textual replacement in your Makefile.
The original file looks like:
jasonyux@XY-Laptop ~$ cat Makefile
CC = gcc
CFLAGS = -Wall -g
main: main.o prime.o gcd.o
main.o: main.c prime.h gcd.h
prime.o: prime.c prime.h
gcd.o: gcd.c gcd.h
.PHONY: clean all
clean:
rm -rf *.o main
And then run the sed with pipeline:
jasonyux@XY-Laptop ~$ cat Makefile | sed 's/main/twecho/g'
You get:
CC = gcc
CFLAGS = -Wall -g
twecho: twecho.o prime.o gcd.o
twecho.o: twecho.c prime.h gcd.h
prime.o: prime.c prime.h
gcd.o: gcd.c gcd.h
.PHONY: clean all
clean:
rm -rf *.o twecho
where:
- all occurrence of
mainbecome replaced bytwecho. - the one-line program is
's/main/twecho/g', andsstands forsubstitutegstands forglobally, which means all occurrence on the same line will be replaced
Finally, if you want to put them into a file, you can use the >:
jasonyux@XY-Laptop ~$ cat Makefile | sed 's/main/twecho/g' > somefile.txt
Making Own Library
(for more details, see https://randu.org/tutorials/c/libraries.php)
- If you have a bunch of files that contain just functions, you can turn these source files into libraries that can be used statically or dynamically by programs.
- A library is basically just an archive of object files.
This means you need to do:
-
Compile the source files of functions object files.
-
Run:
ar rcs libmylib.a objfile1.o objfile2.o objfile3.owhere
mylib.awill be the final output library file. -
Either link another file directly with:
gcc -o foo foo.o -L. -lmylibwhere:
-
mylibis the name formylib.ayou just had -
-L.tellsgccto look in the current directory in addition to the other library directories for findinglibmylib.a.
Alternatively, add this in a
Makefile:CC = gcc CFLAGS = -Wall -g LDLIBS = -L. -lmylist mylist-test: mylist-test.o libmylist.a libmylist.a: mylist.o ar rcs libmylist.a mylist.o ... etc -
cut
cut OPTION... [FILE]...
DESCRIPTION:
-
Print selected parts of lines from each FILE to standard output.
- With no FILE, or when FILE is
-, read standard input. - Mandatory arguments to long options are mandatory for short options too.
Some useful options would be:
-d, --delimiter=DELIM
use DELIM instead of TAB for field delimiter
-f, --fields=LIST
select only these fields; also print any line that contains no
delimiter character, unless the -s option is specified
sort
sort - sort lines of text files
uniq
uniq - report or omit repeated lines
wget
wget - The non-interactive network downloader.
wget [option]... [URL]...
cmp
Used for comparing two files
rsync
This would be a better version of cp, where this can:
- copy across internet/machines
- copy only the difference