Data#
Training, evaluating, or serving an RQA system requires data. Depending on your use case, what data you need to prepare will vary. In a standard workflow with full model training → evaluation → deployment, you will need: 1) a collection of documents acting as a database, and 2) a collection of question-passage-answer triplets used for training and evaluation.
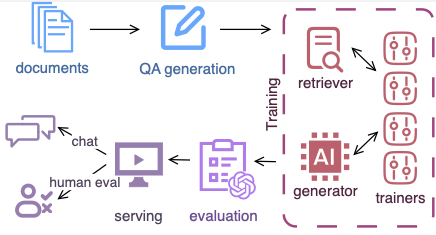
Example workflow using LocalRQA. The data components are colored in blue.#
As an example, a (simplified) document database may look like this:
[
{
"content": "Configure access to the `default.people10m` table\n\nEnable the user you created ...",
"metadata": {
"title": "...",
"url": "..."
}
},
{
"content": "## Updated required permissions for new workspaces\n\n **February 28, 2023**\n\n The [set of required permissions] ...",
"metadata": {
"title": "...",
"url": "..."
}
},
...
]
and (simplified) examples of question-passage-answer triplets may look like this:
[
{
"question": "How can I enable a user to access a specific table in Databricks?",
"passage": "Configure access to the `default.people10m` table\n\nEnable the user you created ...",
"answer": "To enable a user to access a specific table in Databricks, you can follow these steps: ..."
},
{
"question": "How can I access ADLS2 with UC external locations in Databricks?"
"passage": "## Access <ADLS2> with <UC> external locations\n\n .. note:: <ADLS2> is ...",
"answer": "You can access Azure Data Lake Storage Gen2 (ADLS2) with Unity Catalog (UC) by ..."
},
...
]
What Data Do We Need?#
Depending on how you wish to use LocalRQA, you may not need all the data mentioned above. In this section, we provide high-level explanations of the kind of data you will use for training, evaluation, and serving an RQA system.
Training Data#
Training an RQA system end-to-end requires a collection of question-passage-answer triplets. Typically:
to train a retrieval model, you would need a collection of (question, passage) pairs
to train a generative model, you would need a collection of (question, passage, answer) triplets
However, the exact requirement depends on what training algorithms you want to use. For more details, you can refer to Training.
Evaluation Data#
LocalRQA provides two ways to evaluate an RQA system: automatic evaluation (see Evaluation) and human evaluation (see Static Human Evaluation). If you have access to ground-truth question-passage-answer triplets, you should be good for all evaluation functionalities we provide in this package. Alternatively, if you only wish to use a subset of the evaluation pipelines:
automatic evaluation of a retrieval model requires ground-truth question-passage pairs
automatic evaluation of a generative model requires ground-truth question-passage-answer triplets
human evaluation requires a collection of questions (and optionally passages)
For more details on running those evaluations, you can refer to Evaluation.
Serving Data#
Finally, to deploy your RQA system either for human evaluation or just as a chatbot, you will need a collection of documents acting as a database. A document is simply a piece of text plus some metadata (e.g., title, URL), which can be used to provide additional context to the generative model and to the user.
When serving your RQA system with Serving, we will also automatically create a vector index of the document database you provided. This is because embedding a large document database may take time, so saving them prevents you from having to re-embed the documents every time you restart the server.
For more details on how to deploy your RQA system, you can refer to Serving.
Data Schema#
At the beginning of this section, we provided two simplified examples of how a document/passage is formatted. In practice, your data source can come from any format (e.g., docs from Google Drive, texts from a website), so it is important to store additional information beyond the text itself.
LocalRQA considers a uniform schema to represent these documents as:
class Document:
page_content: str
fmt_content: str = field(default='') # content formatted with metadata information
metadata: dict = field(default_factory=dict)
so that you have:
page_contentstores the raw text of the documentmetadatais a dictionary that is used to store all kinds of additional information about the document (e.g., title, URL, author, etc.)fmt_contentis a re-formated version ofpage_content, using some of the metadata information. This is the actual text used by retriever and generative models.
Therefore, the full version of the document database looks like this:
[
{
"page_content": "Configure access ...",
"fmt_content": "Title: How to ...\nURL: ...\nContent: Configure access ...",
"metadata": {
"title": "How to ...",
"url": "..."
}
},
{
"page_content": "## Updated required permissions ...",
"fmt_content": "Title: ...\nURL: ...\nContent: Configure access ...",
"metadata": {
"title": "...",
"url": "..."
}
},
...
]
and question-passage-answer looks like this:
[
{
"question": "How can I enable a user to access a specific table in Databricks?",
"passage": {"page_content": "Configure access to ...", "fmt_content": "...", "metadata": {...}},
"answer": "To enable a user to access a specific table in Databricks, you can follow these steps: ..."
},
{
"question": "How can I access ADLS2 with UC external locations in Databricks?"
"passage": {"page_content": "## Access <ADLS2> ...", "fmt_content": "...", "metadata": {...}},
"answer": "You can access Azure Data Lake Storage Gen2 (ADLS2) with Unity Catalog (UC) by ..."
},
...
]
For more complete examples of these data, see RQA Data Format.
How to Obtain RQA Data?#
Adding up all the data requirements, you may be wondering how to obtain: 1) a collection of documents as a database, and 2) a collection of question-passage pairs or question-passage-answer triplets. In general, we provide two methods:
Create your own data from scratch: starting from your own data source (supported by
langchainorllama-index), you can create question-passage-answer using sampling algorithms and an LLM.Convert from existing QA datasets: many existing QA datasets, such as Natural Questions (Kwiatkowski et al., 2019), TriviaQA (Joshi et al., 2017), and MS-Marco (Bajaj et al., 2018) contain question-passage-answer triplets. We provide one-line commands to convert these datasets into the format required by LocalRQA.
For more details, you can refer to Prepare RQA Data.
References
Tom Kwiatkowski, Jennimaria Palomaki, Olivia Redfield, Michael Collins, Ankur Parikh, Chris Alberti, Danielle Epstein, Illia Polosukhin, Jacob Devlin, Kenton Lee, Kristina Toutanova, Llion Jones, Matthew Kelcey, Ming-Wei Chang, Andrew M. Dai, Jakob Uszkoreit, Quoc Le, and Slav Petrov. 2019. Natural Questions: a benchmark for question answering research. Transactions of the Association for Computational Linguistics, 7:452–466.
Mandar Joshi, Eunsol Choi, Daniel Weld, and Luke Zettlemoyer. 2017. TriviaQA: A large scale distantly supervised challenge dataset for reading comprehension. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 1601–1611, Vancouver, Canada. Association for Computational Linguistics
Payal Bajaj, Daniel Campos, Nick Craswell, Li Deng, Jianfeng Gao, Xiaodong Liu, Rangan Majumder, Andrew McNamara, Bhaskar Mitra, Tri Nguyen, Mir Rosenberg, Xia Song, Alina Stoica, Saurabh Tiwary, and Tong Wang. 2018. MS-Marco: A human generated machine reading comprehension dataset.