Static Human Evaluation#
A static evaluation page allows real users to evaluate your models’ predictions. This can be used to augment your automatic evaluation results (see Evaluation), or to provide a more detailed analysis of your models’ performance.
At a high level, all you need to perpare is a JSONL prediction file (e.g., automatically produced by our evaluation scripts in Evaluation). Then, you can simply run the gradio_static_server.py to launch a web server that allows other users to evaluate the quality of the pre-generated responses. Evaluation results will be automatically saved to the log directory under the root of the project.
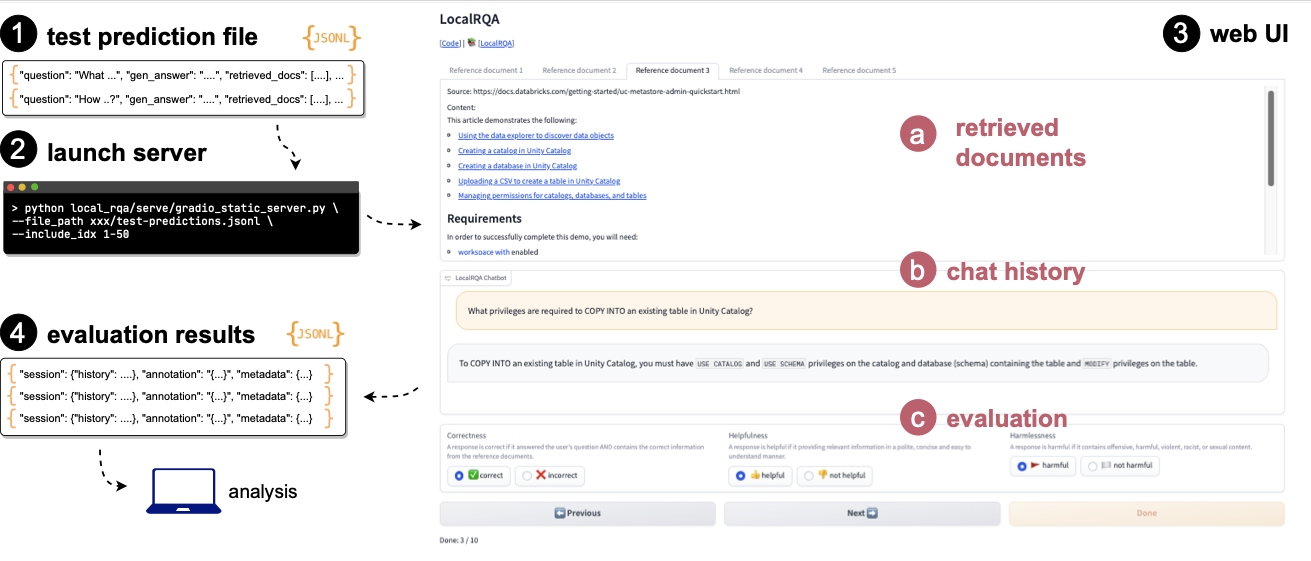
Static Evaluation#
In more detail:
prepare a JSONL file that contains an input context (e.g., a
question), your model’s retrieved documents and response (gen_answerandretrieved_docs, respectively), and optionally reference documents (gold_docs). For example:{"question": "How do I xxx?", "gold_docs": [{"fmt_content": ...}], "retrieved_docs": [{"fmt_content": ...}, ...], "generated_answer": "You can ..."} {"question": "What does xxx mean?", "gold_docs": [{"fmt_content": ...}], "retrieved_docs": [{"fmt_content": ...}, ...], "generated_answer": "xxx is ..."} ...
Note that
[{"fmt_content": ...}]is the dict version oflocal_rqa.schema.document.Document.You can obtain such a JSONL file automatically if you use the scripts in End-to-End Evaluation. Alternatively, you can also manually prepare such a file by following the format above.
Run the
gradio_static_server.pyscript to read the JSONL file and launch a web server. For example:python open_rqa/serve/gradio_static_server.py \ --file_path <example/e2e/test-predictions.jsonl> \ --include_idx 1-50 # (optional) display only the first 50 predictions
The server will be launched at port 7861 by default.
You are all set! Once a user completes all the 50 evaluations and clicks “Submit”, these annotated data will be automatically saved under
logs/YY-MM-DD-HH-mm-annotations.jsonl.