Interactive Chat#
An interactive chat page allows real users to perform multi-turn chat with the model while providing feedback on the quality of the responses. This is useful for collecting human feedback on the model’s performance in a more natural setting.
At a high level, you will need to prepare 1) your embedding and generative model of choice, and 2) a document and index database. Then, to handle asynchronous requests, you will launch 1) a model controller to manage model workers, 2) model workers to actually run the models, and 3) a web server to serve the interactive chat page.
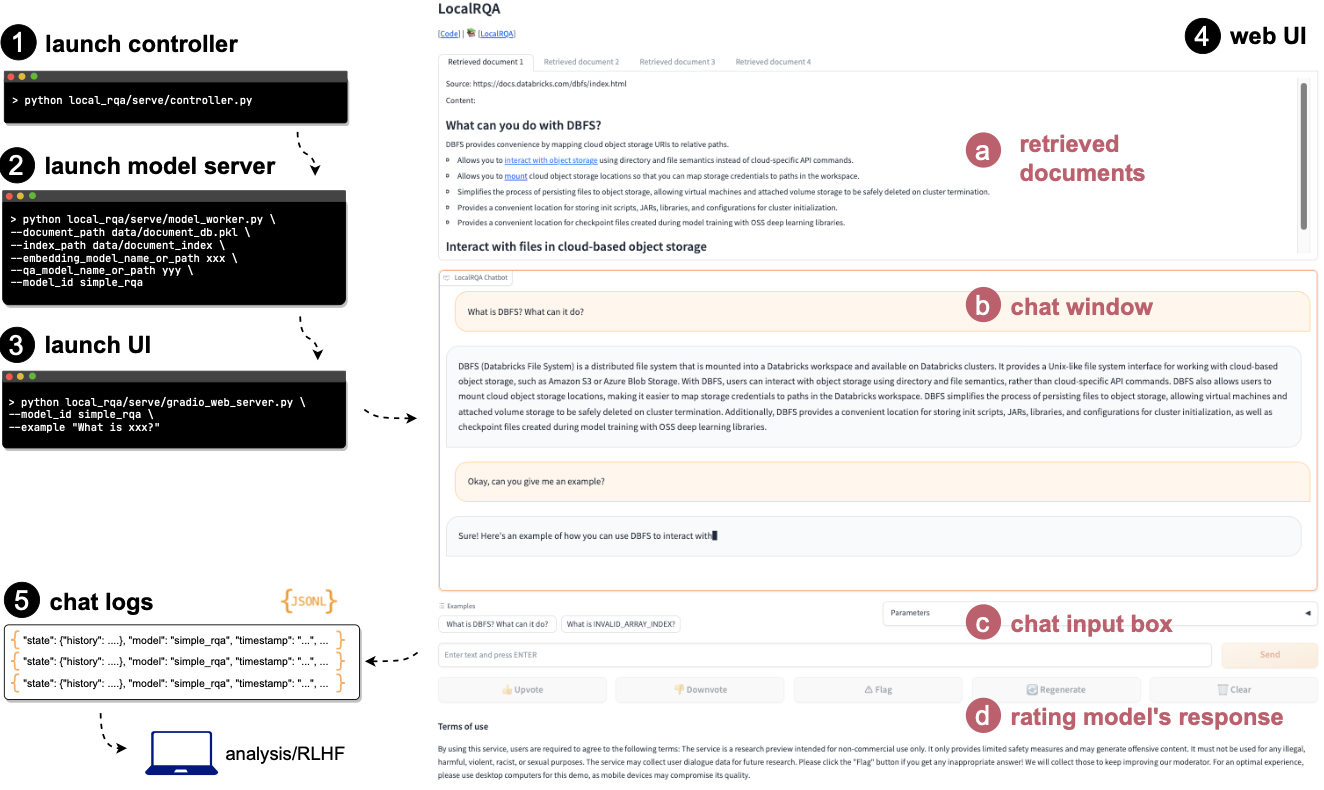
Interactive Chat#
In more detail:
Make sure the
logfolder exists under the project root directory. This is because by default, all server logs and annotations will go underlogsfolder.First start the model controller, which will by default listen to port 21001.
python local_rqa/serve/controller.pyThen, start the model worker(s) to run the models. For example, you can start one worker with GPU 0:
export CUDA_VISIBLE_DEVICES=0 python local_rqa/serve/model_worker.py \ --document_path <example/documents.pkl> \ --index_path <example/index> \ --embedding_model_name_or_path intfloat/e5-base-v2 \ --qa_model_name_or_path lmsys/vicuna-7b-v1.5 \ --model_id simple_rqa
which will:
read in the document database saved at
<example/documents.pkl>load the embedding and generative model (
intfloat/e5-base-v2andlmsys/vicuna-7b-v1.5in this case). In general, this also works with most models that can be recognized by huggingface’sAutoModelclass.read the index from
<example/index>if not empty, otherwise index all the documents using the embedding model and save the index to<example/index>register this worker as
simple_rqato the controller
For more details on how to obtain the document or index database in step 1 and 3, you can refer to Quickstart for a quick example.
To test to see if the above is working at this point:
python local_rqa/serve/test_message.py --model_id simple_rqa
which will send a request to the controller for a response given the prompt “Tell me a joke with more than 20 words.”.
Finally, simply start the front-end web server to serve the interactive chat page!
python local_rqa/serve/gradio_web_server.py \ --port 28888 \ --model_id simple_rqa \ --example "What is DBFS? What can it do?" \ --example "What is INVALID_ARRAY_INDEX?"
this will launch a web server at http://localhost:28888. Note that
--model_id simple_rqatells the controller that all requests to this server should be handled by the worker with id simple_rqa.--example "What is DBFS? What can it do?"and--example "What is INVALID_ARRAY_INDEX?"are example inputs that will be shown to the user when they open the chat webpage.
Optionally, you can further accelerate your language model’s inference speed using acceleration frameworks such as TGI, vLLM, or SGLang. For more details, please refer to Inference Acceleration Frameworks. To use these frameworks with this interactive chat page, simply replace the --qa_model_name_or_path argument with the model URL provided by the acceleration framework.
For example, with vLLM:
Use
vLLMto host your generative model:python -m vllm.entrypoints.api_server --model lmsys/vicuna-7b-v1.5
this should by default host the model at
http://localhost:8000.Change the
--qa_model_name_or_pathargument to<framework-name>::<url>/generate:export CUDA_VISIBLE_DEVICES=0 python local_rqa/serve/model_worker.py \ --document_path <example/documents.pkl> \ --index_path <example/index> \ --embedding_model_name_or_path intfloat/e5-base-v2 \ # --qa_model_name_or_path lmsys/vicuna-7b-v1.5 \ --qa_model_name_or_path vllm::http://localhost:8000/generate \ --model_id simple_rqa
and the rest of the steps are the same as above.